第5回: 政治的な(?)対立に巻き込まれたOpenACC
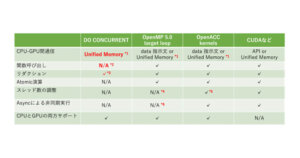
今回の記事からは、OpenMP5.xや言語標準の並列化機能など、OpenACCに代わりうる新たなGPU向けの並列化手法について紹介します。
第4回:MPI+OpenACC実装における計算と通信のオーバーラップ
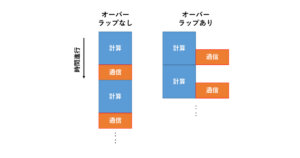
前回はMPI + OpenACCによる拡散方程式のマルチGPU実装を行いましたが、性能向上できたのは4GPUまでで、8GPUでは逆に遅くなってしまったのでした。今回はより高速化するためにはどうしたらいいのかについて解説していきます。
第3回:拡散現象シミュレーションのおさらい
前回はMPI + OpenACCによる簡単な計算を取り上げました。
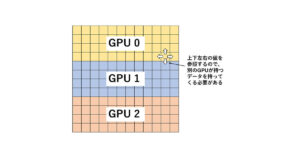
今回は、入門編で取り上げた拡散方程式プログラムの複数GPU実行について考えてみましょう。
第2回:簡単なOpenACC + MPI コードで考える
中級編の続きです。
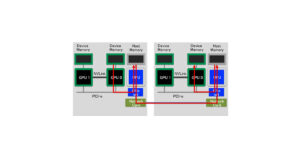
前回はMPI + OpenMPによるHello Worldの解説でしたが、今回はもう少し計算っぽいことをしてみましょう。
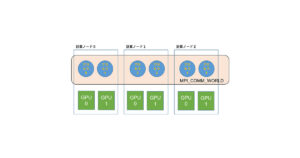
第 1回:複数のGPUを使う方法とは?
お久しぶりです!
今回からは中級編ということで、近年普通になっている複数のGPUを搭載した計算機で、OpenACCを使う方法の解説を行います。

第12回:OpenACCを使ったICCG法の高速化つづき
前回に引き続き、OpenACCを使ったICCG法の高速化手法について考えてみます。
オリジナルのプログラムは東大情報基盤センターの講習会、「OpenMPによるマルチコア・メニィコア並列プログラミング入門」のページから入手できます。

第11回:OpenACCを使ったICCG法の高速化
OpenACCの基本的な考え方や使い方については、前回まででおおよそ説明しきってしまいました。
それでは習うより慣れろということで、今までの総仕上げとして、ICCG法プログラムのOpenACC実装についてご紹介します。

第10回:OpenACCでできる最適化とは?
前回は、OpenACCプログラムにおけるGPU向けライブラリプログラムの呼び出し方の解説に加え、行列積のような計算量オーダーの大きな計算パターンにおいては、GPUの性能を発揮するためのプログラムの最適化を十分に行えず、満足な性能が得られない可能性があることを解説しました。
今回はここをもう少し掘り下げて、GPUプログラミングにおける最適化とOpenACCの関係性について解説します。

第9回:速くならない?とりあえずライブラリに頼ろう!
前回に引き続き、OpenACCでうまく行かないケースとその解決策について学びます。
特に計算が複雑になればなるほど、思ったほどの性能が出ないケースが増えてきます。そんな時はどうしたら良いのでしょうか?
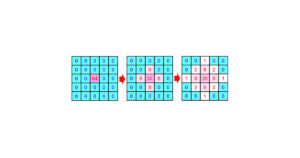
第8回:OpenACCでも扱えるけど面倒な構造体
実のところ拡散方程式のプログラムは、OpenACCと非常に相性の良いプログラム例です。しかし最初に述べた通り、OpenACCで全てがうまく行くわけではありません。
今回からは、どんな時にうまく行かないのか、そしてうまく行かないときにどう解決したら良いのか、について学びます。