GPUアーキテクチャ「Hopper」があらゆるワークロードを加速する
NVIDIA® H100 Tensor Core GPU は、最新のGPUアーキテクチャ「Hopper」を採用し、80GB HBM2eの大容量GPUメモリ、第4世代のTensorコア、前世代となるNVIDIA A100 GPUの約1.5倍にあたる800億個のトランジスタが搭載されています。
NVIDIA H100 GPUは、生成AIや大規模言語モデル(LLM)といった昨今人気を集める推論AIワークロードから、データ分析、ハイパフォーマンス コンピューティング (HPC)など大規模計算向けに設計されています。
開発や研究において、劇的な高速化を実現し、パフォーマンス向上とコスト削減に貢献します。
※ [2026.02] 販売終了のため、在庫限りとなります。
NVIDIA H100 Tensor Core GPU

NVIDIA Hopper アーキテクチャ
最新の TSMC 4N プロセスを利用し、800 億個以上のトランジスタで作られた Hopper は、NVIDIA H100 Tensor コア GPU の中核をなす 5 つの画期的なイノベーションを持ち、それにより世界最大の言語生成モデルである NVIDIA の Megatron 530B チャットボットの AI 推論で、前世代と比較して 30 倍という驚異的なスピードアップを実現します。
Transformer Engine
NVIDIA Hopper アーキテクチャは、AI モデルのトレーニングを高速化するように設計された Transformer Engine との組み合わせで Tensor コア テクノロジを前進させます。
Hopper Tensor コアでは FP8 と FP16 の精度を混在させることができます。トランスフォーマーの AI 計算が劇的に速くなります。
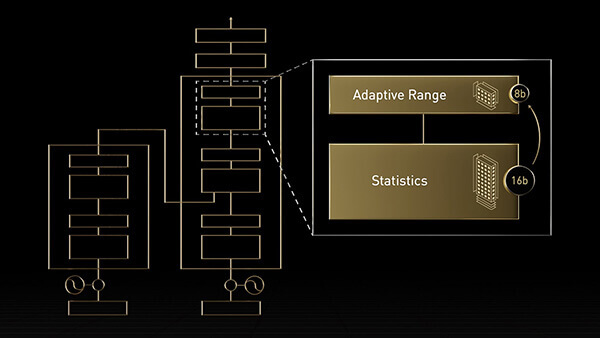
Hopper は、TF32、FP64、FP16、INT8 の精度の浮動小数点演算 (FLOPS) を前世代の 3 倍にします。Transformer Engine と第 4 世代 NVIDIA NVLink® と組み合わせることで Hopper Tensor コアは HPC と AI のワークロードを桁違いに高速化します。
NVLink Switch システム

ビジネスの最先端では、エクサスケール HPC と兆パラメーター AI モデルを大規模にスケールするために、サーバークラスター内の各 GPU 間に高速でシームレスな通信が必要です。
第 4 世代 NVLink は、スケールアップ相互接続で、新しい外部 NVLink Switch と組み合わせると、NVLink Switch システムは、PCIe Gen5 の 7 倍以上の帯域幅、GPU あたり 900 ギガバイト/秒 (GB/s) の双方向で複数のサーバーにわたるマルチ GPU IO (入出力) を拡張することが可能になりました。
NVLink Switch システムは、最大 256 基の H100 を接続したクラスターをサポートし、Ampere で InfiniBand HDRの 9 倍高い帯域幅を実現します。
さらに、NVLink は、これまで InfiniBand でしか利用できなかった SHARP と呼ばれる In-network Computing をサポートし、57.6 テラバイト/秒 (TB/s) の All-to-All の帯域幅を実現しながら、FP8 スパース AI コンピューティングで 1 exaFLOPS という驚くべき性能を提供することができるようになりました。
第 2 世代 MIG
マルチインスタンス GPU (MIG) という機能では GPU を、完全に分離された複数の小さなインスタンスに分割できます。
それぞれにメモリ、キャッシュ、コンピューティング コアが与えられます。Hopper アーキテクチャは MIG の機能をさらに強化するものです。最大 7 個の GPU インスタンスで仮想環境のマルチテナント/マルチユーザー構成をサポートします。
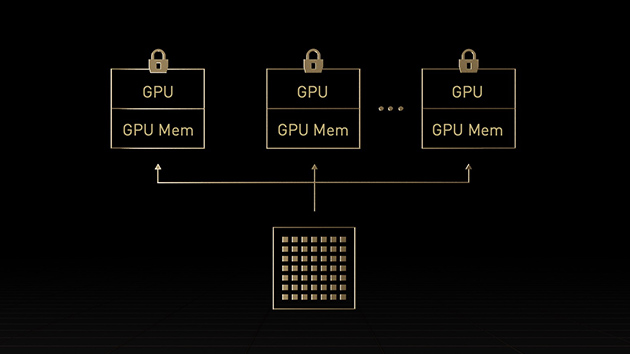
コンフィデンシャル コンピューティングによってハードウェアおよびハイパーバイザー レベルで各インスタンスが分離されるため、安全です。MIG インスタンスごとに専用のビデオ デコーダーが与えられ、共有インフラストラクチャで安定したハイスループットのインテリジェント ビデオ解析 (IVA) が実現します。そして、Hopper の同時実行 MIG プロファイリングを利用すると、管理者はユーザーのために正しいサイズの GPU 高速化を監視し、リソース割り当てを最適化できます。
研究者のワークロードが比較的少ない場合、完全な CSP インスタンスを借りる代わりに、MIG を利用して GPU の一部を安全に分離することを選択できます。保存中、移動中、処理中のデータが安全なため、安心です。

参考販売価格:5,190,000円(税込 5,709,000円)
短期レンタル価格:850,000 円/月(税込 935,000 円/月)
長期1年レンタル価格:380,000 円/月(税込 418,000 円/月)
発売時期:2023年3月
レンタルの詳細はこちら
NVIDIA H100 Tensor Core GPU 性能
NVIDIA H100 GPUと、前世代となるNVIDIA A100 GPUの性能を掲載しています。
| NVIDIA H100 Tensor Core GPU [PCIe] | NVIDIA A100 Tensor Core GPU [PCIe] | |
| FP64 | 26.0 TFLOPS | 9.7 TFLOPS |
| FP64 Tensor コア | 51.0 TFLOPS | 19.5 TFLOPS |
| FP32 | 51.0 TFLOPS | 19.5 TFLOPS |
| TF32 Tensor コア | 756 TFLOPS | 156 TFLOPS |
| BFLOAT16 Tensor コア | 1,513 TFLOPS | 312 TFLOPS |
| FP16 Tensor コア | 1,513 TFLOPS | 312 TFLOPS |
| FP8 Tensor コア | 3,958 TFOPS | ー |
| INT8 Tensor コア | 3,026 TOPS | 624 TOPS |
NVIDIA H100 Tensor Core GPU スペック
NVIDIA H100 GPUと、前世代となるNVIDIA A100 GPUのスペックを掲載しています。
参考価格は変動する可能性がありますので、価格についてはお問い合わせください。
| NVIDIA H100 Tensor Core GPU [PCIe] | NVIDIA A100 Tensor Core GPU [PCIe] | |
| 参考販売価格 | 5,190,000円 (税込 5,709,000円) | 5,190,000円 (税込 5,709,000円) |
| 発売時期 | 2023年3月 | 2021年6月 |
| GPUアーキテクチャ | Hopper | Ampere |
| GPUメモリ | 80 GB HBM2e | 80 GB HBM2 |
| ECC機能 | 対応 | 対応 |
| メモリバンド幅 | 2 TB/s | 1,935 GB/s |
| メモリバス | 5,120 bit | 5,120 bit |
| Compute Capability | 9.0 | 8.0 |
| CUDAコア | 14,592 | 6,912 |
| RTコア | 0 | 0 |
| Tensorコア | 456 | 432 |
| NVLink | 対応 | 対応 |
| ベースクロック | 1,065 MHz | 1,065 MHz |
| GPU Boost クロック | 1,620 MHz | 1,410 MHz |
| 最大消費電力 | 350 W | 300 W |
| 補助電源 | PCIe CEM5 16 pin | CPU(EPS) 8 pin |
| バスインターフェース | PCIe 5.0 × 16 | PCIe 4.0 × 16 |
| トランジスタ数 | 80 | 54.2 |
| マルチインスタンスGPU | 各10GBで最大7つのMIGS | 各10GBで最大7つのMIGS |
| 相互接続 | NVLink:600GB/s PCIe Gen5:128GB/s | NVLink:600GB/s PCIe Gen4:64GB/s |
NVIDIA GPU 一覧表PDF
弊社で取り扱っているNVIDIA GPUの性能・スペックを一覧にしました。
PDFファイルをダウンロードすることができます。

NVIDIA GPU 拡張保証サービス

NVIDIA GPUは「3年間センドバック保証(無償修理・交換)」のメーカー標準保証が基本として含まれていますが、
当社オリジナルとして「NVIDIA GPU 拡張保証サービス」をご提供しています。
「NVIDIA GPU 拡張保証サービス」には、先出しセンドバック保証、センドバック延長保証、オンサイト保証があり、お客様のニーズや状況にあわせた保証内容にすることができます。
NVIDIA GPU 拡張保証サービスにより、GPU導入後も、長く・安心してお使いいただけます。
GPUを導入される際に、あわせてご検討ください。
★NVIDIA GPU 拡張保証サービスの詳細はこちら
NVIDIA H100 Tensor Core GPUの設置場所は3通り!
会社の環境や設置スペースにあわせて、NVIDIA H100 GPUの設置場所を選ぶことができます。
New!
1. デスクサイドに設置

高負荷をかけても静音!GPU温度も安定
GPU Cooling BOXのファンを工夫したことにより、NVIDIA H100 / A100 GPUがフル稼働しているのも気づかないほどの静音です。
また、GPUを効率的に冷やすことができるため、空冷と比較して10-15%の性能向上が見込めます。
2. サーバー室に設置

GPUサーバー
GS-Supermicro SYS-741GE-TNRT
GPU最大4基 搭載可能
第4世代 インテル Xeon スケーラブル・プロセッサーを搭載しており、16個のDIMMスロット、最大4TBのDRAM、PCI-E 5.0に対応、最大8台のNVMeドライブ、4Uラックサイズのタワー型です。
横置き、縦置きも可能です。
3. 静音ケースに入れて居室内に設置
静音ケースも取り扱っています。
サーバー室への設置が一般的ですが、GPUサーバーを静音ケースに入れて居室に置き、手元で使用されるニーズも増えています。
静音ケースの価格は、GS-Supermicro SYS-741GE-TNRT 製品ページ に掲載しています。
NVIDIA H100 Tensor Core GPU 搭載可能な製品について、
ご不明な点やご質問などありましたら、お問い合わせください!

お気軽にご相談ください!
製品に関するご質問・ご相談など、お気軽にお問い合わせください。
NVIDIA認定パートナー「GDEPソリューションズ」は、
お客様の用途に最適な製品のご提案から導入までサポートします。