前回までの記事で、MPI+OpenACCで押さえておくべきポイント(プロセス番号とGPU番号の割り付け、host_data指示文+CUDA aware MPI、async節による通信と計算のオーバーラップ実行)については解説が終わってしまいました。
そこで今回の記事からは、OpenMP5.xや言語標準の並列化機能など、OpenACCに代わりうる新たなGPU向けの並列化手法について紹介します。
政治的な(?)対立に巻き込まれたOpenACC
OpenACCの登場は2011年頃ですが、ここ数年でGPUプログラミングを取り巻く環境は様変わりしています。少し前までは、スパコンに搭載されるGPUといえばほとんどがNVIDIA製のGPUでした。
ところが2022年6月、世界で初めて1 ExaFLOPS(1秒間に1018乗回浮動小数点演算を行うことができる。富岳は0.44 ExaFLOPS程。)を超えるスパコンとして登場したOak Ridge National LaboratoryのFrontierは、AMDのMI250X GPUを搭載しているのです。
さらにはあのCPUの巨人、IntelまでもがGPUの開発を行っていると言うではないですか!
OpenACCの規格そのものはオープンなものであり、NVIDIAのものというわけではないのですが、旧PGI(2013年にNVIDIAに買収された)が中心となってOpenACCを作ってきたということもあり、おそらくは政治的な対立を経て、現在は事実上NVIDIA GPUの専用言語となってしまいました。
AMDやIntelはOpenACCをサポートするつもりはなさそうなので、AMDやIntelのGPUでの実行を見据えるなら、他の選択肢を考えなければなりません。
「さんざんOpenACCを紹介してきたくせに、今更そんなことを言われても困る!」と石を投げられそうですが、大丈夫です。
OpenACCで覚えた基本を押さえておけば、他の手法も大差ありません。
OpenACC vs. OpenMP 5.x vs. 言語標準並列化
AMD、IntelのGPUを見据えたとき、一番の代替候補はOpenMP 5.xです。
OpenMPといえばCPU向け並列プログラミングの代名詞的存在ですが、OpenMP 4.5くらいからGPU等のアクセラレータにも対応するようになったのでした。
バージョン4.xでは、OpenACCと比べて機能が少なく使いづらかったのですが、5.xになってだいぶマシになってきました。
これに加えてもう一つ、C++のstdparやFortranのdo concurrentといった、言語標準の並列化機能を使ってGPUを利用するという選択肢が新たに登場しました。
これはまだNVIDIAのコンパイラしかサポートしていませんが、言語標準の機能ですから、AMDやIntelでも今後サポートされる可能性があります。
Fortranにてそれぞれの実装方法を比べたのが図1です。
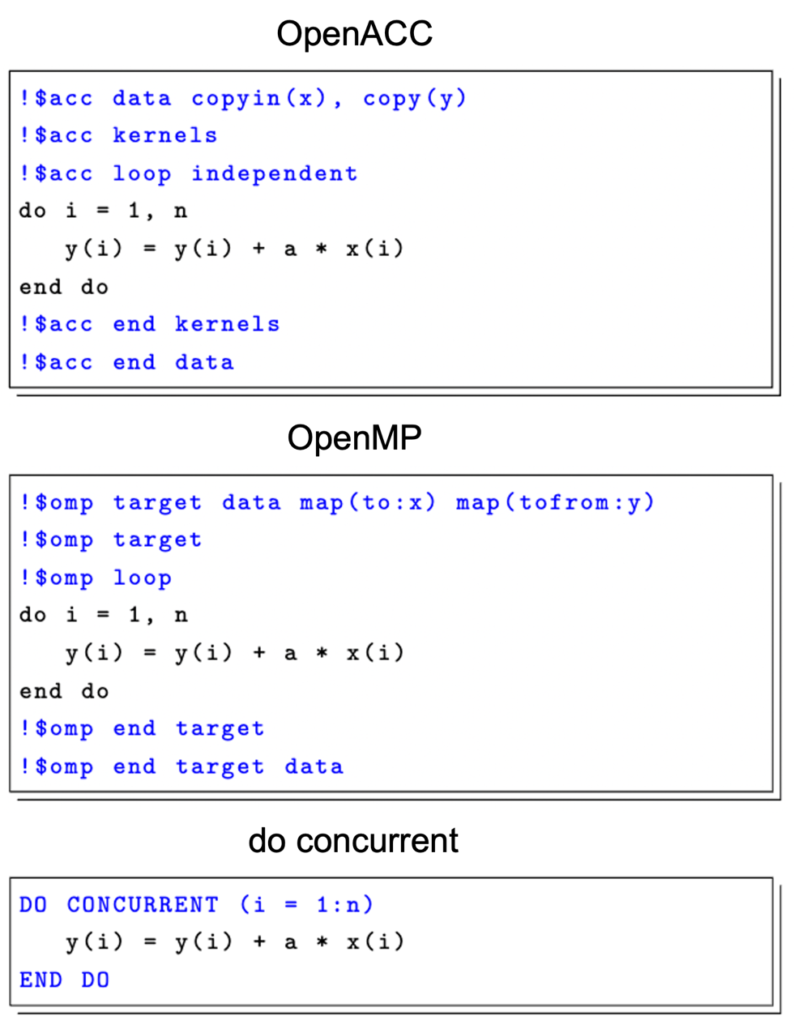
OpenMPのloop指示文は、OpenMP 5.0以降に追加された指示文です。
OpenMPのtarget+loop指示文は、OpenACCのkernels+loop指示文とかなり近い感覚で使用できます。
OpenMP 4.xから使える、omp target teams distribute parallel doという呪文は、ただでさえ長い上にCPUでの実行を見据える使い辛い(CPUでもGPUでも実行できるのは良いが、多重ループを並列化する場合、CPUの場合とGPUの場合で、指示文を適用するべきループが変わってしまう。なぜそんな仕様に…)代物だったので、5.0でloopが追加されてようやく紹介できるようになったかなと思います。
!$omp target dataが!$acc dataに相当する指示文で、 map(to:変数名)がOpenACCのcopyin(変数名)に対応します。to:の部分は他にfrom:, tofrom:, alloc:が指定でき、それぞれOpenACCのcopyout, copy, createに対応します。
一方でdo concurrentは、doループそのものをdo concurrentに変えてしまっています。また、data指示文に相当するものがありません。
これは、Fortranの仕様自体がGPUを想定していないからですが、ではNVIDIAコンパイラはどうやってdo concurrentをサポートしているのでしょうか。
その辺を含めて、NVIDIAコンパイラにおけるOpenACC, OpenMP, do concurrentの実装を比較したものが表1です。
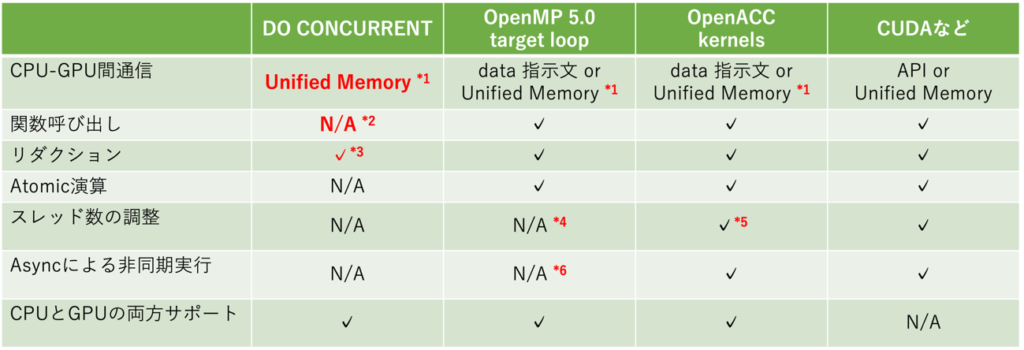
NVIDIAコンパイラでは、do concurrentにおけるCPU-GPU間データ転送はUnified Memoryに依存しています。ただしこれはFortranの言語仕様としてそうなっているわけではありませんので、AMDやIntelがどのように実装するかはわかりません。
Unified MemoryはOpenACCやOpenMPでも有用で、data指示文を記述しなくてもデータ転送を勝手にやってくれますが、GPU direct通信が使えないなどのデメリットも存在します。Do concurrentを使う場合にはこのデメリットを回避する方法がないとも言えますね。
またdo concurrentループの内側では、関数の呼び出しができません。
Fortranの仕様上はpure functionに限り関数呼び出しができるはずなのでが、現時点(nvfortran 22.5)では pure functionすら呼び出しできないようです。
仮にpure function (戻り値一つ、引数の中身を書き換えない関数)をサポートしたとしても、実際のアプリケーションで使うにはかなりキツい制限です。
最新仕様のFortran 2018では、do concurrentによるリダクション演算もサポートしていませんが、NVIDIAコンパイラは独自拡張としてサポートしているようです。
Atomic演算の仕様もありませんが、リダクションと合わせてFortran 202Xでサポートされる予定があるそうです。
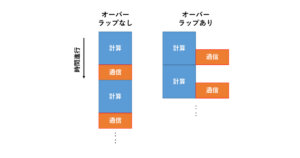
さて、OpenACCとOpenMP 5.xを比較した場合に、性能上差が出そうなのはスレッド数の調整と、OpenACCで行ったasync節による非同期実行です。
この辺の違いが性能にどのくらい影響を与えるのか、次回以降例を示しながらご紹介します。