簡単導入でRAGを試してみる!
RAGスターターセットは、企業向けに提供する手軽にRAG構築の検証を始めることができるAIソリューションです。
Llama やGemmaなどの最新の大規模言語モデル(LLM)や、RAG開発ツール「Dify」をプリインストールし、さらに必要な初期設定を行っていますので、導入後に複雑な設定を行うことなく、お客様のデータを用いてRAGの構築を始めることができます。
また、動作確認済みのGPU搭載ワークステーションにプレインストールして出荷するため、RAG構築を安心して使えるシステム環境が整っています。
RAGを本格導入する前に、その可能性を試してみたい企業に最適なソリューションです。
まずは、このRAGスターターセットを導入して、最先端の生成AI技術を体験してみませんか?
RAGとは
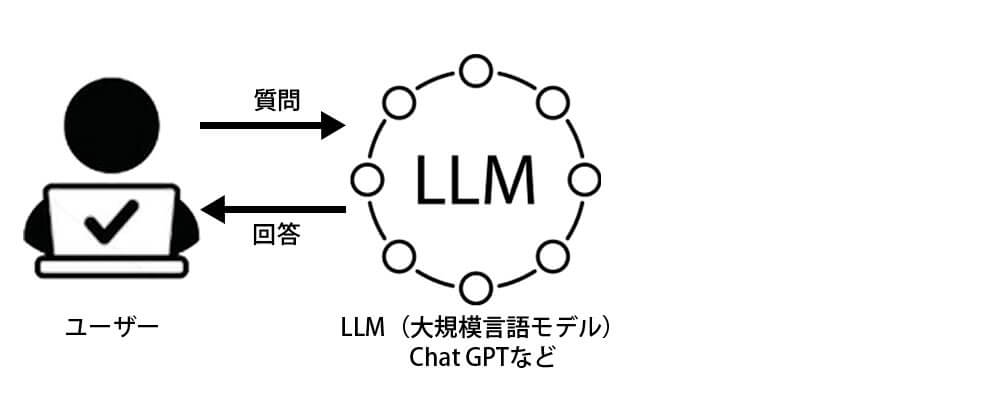
RAG(Retrieval-Augmented Generation:検索拡張生成)とは、LLM(大規模言語モデル)などの生成AIがテキストを生成する際に、事前に学習したデータだけでなく、外部の情報源をリアルタイムで参照して応答を生成する技術です。
生成AIは、過去に学習したデータに基づく応答が行われますが、この方法には「ハルシネーション」と呼ばれる、事実に基づかない内容が出力されることがあります。
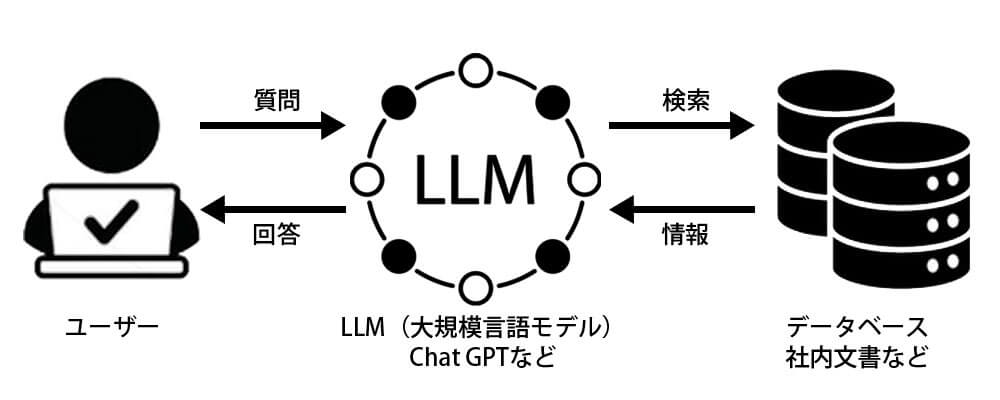
RAGは、データベース(ナレッジベースやドキュメントなど)への検索を組み合わせることで、リアルタイムの最新情報や特定の専門知識を取り込み、より正確で信頼性の高い回答を生成可能です。
この仕組みにより、RAGは、ChatGPTなどの一般的な生成AIよりも高い精度で、特定の業界や企業のニーズに即した応答を提供できる点が注目されています。
LLMのイメージ
RAGのイメージ
クラウド vs ローカル環境
RAGを企業で活用する際、運用環境を「クラウド」か「ローカル環境(オンプレミス)」のどちらにするかは、重要な決断になります。企業のセキュリティポリシーやデータの取り扱い、運用コスト、システムのスケーラビリティなど、さまざまな要因を考慮する必要があります。
クラウド環境は、柔軟でスケーラブルな運用を可能にし、短期間での導入が可能です。
一方で、ローカル環境はセキュリティやデータ管理において大きな利点があります。
それぞれの環境の特徴とメリットを理解し、自社にとってどちらが最適かご検討ください。
クラウド

メリット
スケーラビリティに優れており、初期コストを抑えて導入することが可能。
クラウド上で自動的にメンテナンスされるため、管理負担が軽減されます。
デメリット
データが外部サーバーで処理されるため、機密情報やデータセキュリティに対する懸念がある場合も。また、長期的には利用料金が累積することが多いです。
ローカル環境
メリット
データが社内に留まり、セキュリティリスクを最小限に抑えます。外部への依存がないため、インターネット接続が不安定な状況でも安定して利用することができます。
デメリット
初期導入コストやインフラ管理が必要。ただし、長期的にはコストを抑えられることが多いです。
RAG構築までの作業の流れ
RAGスターターセットは、下記ステップの3~5に該当し、これらの作業をスムーズに進めるためのソリューションです。
1. 目的と要件の明確化
RAG(Retrieval-Augmented Generation)を活用する目的と、システムに求める要件を明確にします。
例えば、社内のFAQシステムの自動化や、製品サポートにおける応答の正確性向上など、具体的な利用シーンを設定することが重要です。目的に応じて、必要なデータやモデルの規模も異なってきます。
2. データセットの準備
RAGでは、生成AIが外部データを活用するため、活用したいデータセットを準備します。
このデータは、ナレッジベースや社内ドキュメント、FAQデータなど、応答に必要な情報が含まれていることが重要です。また、データの整備やクリーニングも行います。
3. LLMの選定・導入
次に、RAGで使用する大規模言語モデル(LLM)を選定します。企業や業界に応じた最適なモデルを選ぶことで、より正確でカスタマイズされた応答を実現できます。代表的なモデルには、LlamaやGemmaなどがあります。
4. システム環境の構築
RAGをスムーズに動作させるために、適切なハードウェア環境を構築します。
GPUを搭載したワークステーションやサーバーなどの高性能なインフラを準備し、モデルの実行やデータ処理に対応できる環境を整えます。
5. RAG開発プラットフォームの導入
RAGを構築するためには、DifyやLangChainなどのRAG開発ツールを活用します。これらのツールを導入し、選定したLLMとデータセットを連携させるための設定を行います。これにより、外部データをリアルタイムで参照する仕組みを構築します。
6. テストとチューニング
RAGの初期設定が完了したら、テストを行い、実際の応答精度やシステムのパフォーマンスを確認します。初めにテストケース用のデータセットを読み込ませて、想定した応答精度が得られるかを確認し、必要に応じてデータセットの修正やハイパーパラメータのチューニングを行います。十分な結果が得られたらデータセットを順次読み込ませていきますが、各データセット毎に、応答精度を検証していきます。
※RAGの応答精度が上がらない原因のほとんどがデータセットにあります。
7. 運用開始とモニタリング
十分な応答精度が得られることを確認したら、RAGの運用を開始します。運用中も、定期的にモニタリングを行い、必要に応じてモデルの更新やデータセットの拡充を行っていきます。運用後のメンテナンスもスムーズに行える体制を整えることが重要です。
RAGスターターセット 特長
すぐに始められるRAG体験!
Llama やGemma などの最新の大規模言語モデルや、RAG開発ツール「Dify」をプリインストールしています。
複雑なセットアップは不要で、届いたその日からRAGの構築検証をスムーズに始められます。
システム環境構築やアプリの動作確認など、場合によっては数か月以上かかる試行錯誤の手間を省き、すぐにRAGの構築に取り掛かりたい方に最適なソリューションです。
データセキュリティを万全に、安心のローカル環境!
ローカル環境に構築されているため、外部にデータを出す必要がなく、社内の機密情報や個人データも100%自社で管理可能です。
クラウドに依存しないため、情報漏洩のリスクを抑え、データセキュリティを重視する企業でも安心してお使いいただけます。
※別途お客様によるセキュリティ対策は必要となります。
GPU搭載で、高速かつ安定したパフォーマンス!
RAGスターターセットには、高性能なGPU(NVIDIA RTX 4500 AdaまたはRTX 6000 Ada)が搭載されており動作確認・検証済みです。
ワークステーション1台でスムーズにRAGの構築検証や小規模な運用から開始することが可能です。
高速な応答生成と安定したパフォーマンスを実現し、初めてのRAG構築に最適なソリューションです。
初期導入をしっかりサポート!
RAGスターターセットには、Q&Aチケットが付属しており、初期導入に必要なサポートが受けられます。※コンサルテーションミーティングは、Q&Aチケット2枚でご利用いただけます。
初めてのRAG構築でも、専門家によるアドバイスが受けられるため、スムーズに導入を進めることができます。
まずはRAGを試してみたいという企業は、安心して始めることができます。
RAGスターターセット
RAGスターターセットには、GPU搭載のワークステーションとRAGの導入をスムーズに進めるための「スタートアップサービス」が付属しています。
お客様のニーズに合わせて、エントリーとミッドレンジの2つのモデルをご用意しています。
エントリーモデルにはNVIDIA RTX 4500 Ada GPUを搭載し、最新のLlama 8Bモデルがプリインストールされています。
コストパフォーマンスに優れ、RAGを試すのに最適なモデルです。
一方、より高性能な環境をお求めの方には、ミッドレンジモデルがおすすめです。
ハイエンドGPUのRTX 6000 Ada GPUと、Llama 70Bモデルを搭載し、大規模なデータ処理に対応したモデルです。
「スタートアップサービス」には、事前に必要なソフトウェアの「プレインストール」と、サポートに役立つ「Q&Aチケット」が含まれています。
また、利用開始するまでのユーザマニュアルが同梱されています。
さらに、Q&Aチケットを利用することで、専門家によるコンサルテーションを受けることができ、初めての導入や設定に関するアドバイスを受けることができます。
プレインストールアプリは、今後も順次追加を予定しています。
| エントリーモデル | ミッドレンジモデル | ||
| 参考販売価格(税抜) | 2,288,000 円 | 4,688,000 円 | |
| プレインストール AIアプリケーション フレームワーク | ユーザインターフェース/ AIアプリケーション開発ツール | Dify OpenWebUI | |
| AIモデル実行ツール | Ollama Xinference | ||
| 生成AIモデル | Meta Llama 3 [8Bモデル] Google Gemma 2 [9Bモデル] Microsoft Phi-3 [3.8Bモデル] | Meta Llama 3 [8B / 70Bモデル] Google Gemma 2 [9B / 27Bモデル] Microsoft Phi-3 [3.8B / 14Bモデル] | |
| Embeddingモデル | nomic-embed-text | ||
| Rerankingモデル | bge-reranker-v2-m3 | ||
| スタートアップ Q&Aチケット | チケット 3 枚 | チケット 6 枚 | |
| ワークステーション | HP Z4 G5 Workstation | ||
| GPU | NVIDIA RTX 4500 Ada [24GB] × 1基 | NVIDIA RTX 6000 Ada [48GB] × 1基 | |
| CPU | インテル Xeon w3-2423プロセッサー (2.1GHz 最大4.2GHz / 6コア / 15MB / 4400MHz) | インテル Xeon w5-2445 プロセッサー (3.1GHz 最大4.6GHz / 10コア / 26.25MB / 4800MHz) | |
| システムメモリ* | 64GB DDR5 SDRAM (4800MHz / ECC / Registered / 16GBx4) | 128GB DDR5 SDRAM (4800MHz / ECC / Registered / 32GBx4) | |
| SSD* | 1TB HP Z Turboドライブ G2 (内蔵M.2スロット接続 TLC NVMe SSD) | 2TB HP Z Turboドライブ G2 (内蔵M.2スロット接続 TLC NVMe SSD) | |
| HDD* | 4TBハードディスクドライブ (SATA / 7200rpm) | ||
| OS | Ubuntu | ||
| 光 学ドライブ | DVD-RW | ||
| キーボード、マウス | 標準添付 | ||
| モニター | なし | ||
| 保守 | 3年間翌日オンサイト(休日修理付き) GPUに関してはセンドバック保証3年 | ||
| 筐体サイズ | 幅 169 mm × 奥行 445 mm × 高さ 386 mm | ||
| 消費電力 | 775 W (80PLUS認証電源ユニット、90%変換効率) | ||
* システムメモリ、SSD、HDDは増設することができます。
為替の変動により価格が変更になる場合がありますので、下記よりお見積をご依頼ください。
スタートアップサービスとは・・・
RAGスターターセットは、プロメテック・ソフトウェアが提供する「スタートアップサービス」と、GDEPが販売する「GPU搭載ワークステーション」がセットになっています。
「スタートアップサービス」は、最新のLLMモデルやChatGPTライクなユーザインターフェース、LLMアプリ開発プラットフォーム「Dify」などの公開された無償アプリケーションをお客様に代わって選定し・インストールします。また、利用開始するまでのユーザマニュアル※1が同梱されています。
「Q&Aチケット」は、ユーザマニュアルでは分からない場合に気軽に質問ができるチケットです。さらに、Q&Aチケットを使用して、専門家によるコンサルテーションを受けることも可能です。
このチケットを活用することで、導入初期の不明点や運用中の課題にも素早く対応でき、スムーズにRAG構築を始めることができます。
※1 ユーザマニュアルは、プレインストールされたローカルLLMをChatGPTのように使うための簡単なマニュアルです。
プレインストールアプリは、今後も順次追加を予定しています。
| エントリーモデル | ミッドレンジモデル | ||
| プレインストール AIアプリケーション フレームワーク | ユーザインターフェース/ AIアプリケーション開発ツール | Dify OpenWebUI | |
| AIモデル実行ツール | Ollama Xinference | ||
| 生成AIモデル | Meta Llama 3 [8Bモデル] Google Gemma 2 [9Bモデル] Microsoft Phi-3 [3.8Bモデル] | Meta Llama 3 [8B / 70Bモデル] Google Gemma 2 [9B / 27Bモデル] Microsoft Phi-3 [3.8B / 14Bモデル] | |
| Embeddingモデル | nomic-embed-text | ||
| Rerankingモデル | bge-reranker-v2-m3 | ||
| スタートアップ Q&Aチケット | チケット 3 枚 | チケット 6 枚 | |
コンサルテーションについて
- 1回のコンサルテーションミーティングは、1時間を予定しています。
ミーティング前に、事前に確認したい項目をお送りいただき、その後ミーティングで詳しくご説明いたします。 - 1回のコンサルテーションには、Q&Aチケット2枚が必要となります。
Q&Aチケットについて
- 1枚のチケットで1つの質問(インシデント)に対応いたします。
初めにいただいた質問に対して、疑問が解消されるまでしっかりサポートいたします。 - Q&Aのやり取りの中で、別の質問と判断される場合は、事前にご確認いただいた上で、別のチケットを使用させていただきます。
チケットの対象外の質問に関しては、チケットは消費されませんのでご安心ください。
RAGスターターセットの他に「LLMスターターセット」もあります。
LLMスターターセットは、純粋に大規模言語モデル(LLM)を活用して生成AIを導入したい企業向けのソリューションです。
LlamaやGemmaなどの最新のLLMがプリインストールされており、企業内での生成AIの活用を迅速に開始できます。
まずは標準的な生成AIを試してみたい企業におすすめです。
ワークステーション本体
HP Z4 G5 Workstation
HP Z4 G5 Workstationは、卓越した性能と拡張性を兼ね備えたプロフェッショナル向けのワークステーションです。
最新のIntel Xeonプロセッサを搭載し、高度な計算を要求するタスクもスムーズにこなします。
最大256GBのメモリと複数のストレージオプションにより、大容量のデータ処理も快適です。多彩なI/Oポートと拡張スロットで、様々な周辺機器やカードを簡単に接続できます。
信頼性の高い冷却システムと堅牢なシャーシ設計により、長時間の稼働にも耐える優れた耐久性を誇ります。
HP Z4 G5 Workstationは、クリエイティブプロフェッショナルやエンジニアに最適な、卓越したパフォーマンスを提供する一台です。





- フロントハンドル
- 電源ボタン
- オーディオジャック
- USB3.1 Gen1 Type-A × 4

5. 電源ボタン
6. オーディオライン
7. 1GbE イーサネットスタンダードポート×1
8. USB3.1 Gen1 Type-A ×6
9. リアハンドル
10. 電源コネクタ
搭載GPU
NVIDIA RTX 4500 Ada / 6000 Ada
NVIDIA RTX は、AI・ディープラーニング、デザインや設計などのCAD制作、3DCG、映像編集、VRなど、プロフェッショナル向けのGPUです。
NVIDIA RTX は、負荷の高い処理を長時間、稼働できるように設計されています。
NVIDIA RTX 6000 Ada は、RTXシリーズのハイエンドGPUです。
| NVIDIA RTX 4500 Ada | NVIDIA RTX 6000 Ada | |
| GPUメモリ | 24GB GDDR6 | 48 GB GDDR6 |
| CUDAコア | 7,680 | 18,176 |
| Tensorコア | 240 | 568 |
| 単精度性能 | 39.6 TFLOPS | 91.1 TFLOPS |
| Tensor性能 | 634.0 TFLOPS | 1,457.0 TFLOPS |


見積依頼・お問い合わせはこちら
製品に関するご質問・ご相談など、お気軽にお問い合わせください。
NVIDIA認定のエリートパートナー「GDEPソリューションズ」は、
お客様の用途に最適な製品のご提案から導入までサポートします。