LLM/RAGの導入を、より簡単に、よりスムーズに。
生成AIの活用が進む中、LLMを自社環境で運用したい、社内データを活用したRAG(検索拡張生成)を構築したい という企業が増えています。しかし、LLMやRAGの導入には、ハードウェア準備・モデル選定・環境構築・開発ツールのセットアップ など、多くの時間と手間がかかるのが課題です。また、クラウドでは機密データの管理が難しい ケースもあり、ローカル環境での運用 が注目されています。
「LLM/RAGシリーズ」 は、これらの負担を大幅に削減し、すぐに使える環境と構築スタートを支援するオールインワンソリューション です。用途に応じて選べる 「LLM/RAGスターターセット」「LLM/RAG業務活用セット」 の2製品をご用意。
業務活用セットには、RAGの初期回答精度80%を達成※1した自社開発の「G-RAGon(ジー・ラグ・オン)」を搭載。

「G-RAGon」は、Chunking(文書分割)とプロンプトの自動最適化 により、RAGの初期回答精度を向上させ、手作業での調整を大幅に削減 します。また、ナレッジデータのバックアップ機能を搭載し、RAG運用の負担を軽減することができます。
当社のGPUハードウェア専門家とAIエンジニアが連携し、ワンストップでLLM/RAG構築の立ち上げをサポート。
すべて一貫して当社で対応するため、スムーズかつ安心して導入いただけます。
これひとつで、ローカルLLM/RAGの構築をスピーディーに開始できます。
※1当社社内チャットボット検証結果
【メディア掲載】『ASCII×AI』LLM/RAGシリーズ インタビュー記事
IT・テクノロジー系メディア『ASCII×AI』にて、弊社の「LLM/RAGシリーズ」および開発ツール「G-RAGon」について、インタビュー記事が掲載されました。本記事では、生成AI導入における現場の課題や、それを解決するための弊社のアプローチ、G-RAGonの特長、GPUワークステーションとの組み合わせによる運用のポイントなどをご紹介しています。
ぜひ以下より記事をご覧ください。
ASCII.jp:「買ってすぐ業務に使える」ローカル完結型のRAGが生まれた背景 (1/3)
「ビジネスで本格的に生成AIを使うには、やはり社内にある自社固有の情報が必要になります。ただ、そういった情報は、守秘義務があったり、そもそもクラウドに出せないも…

LLM/RAGシリーズの概要
LLM/RAGシリーズは、NVIDIA GPU搭載ワークステーション に、Llama や Gemma などの最新の大規模言語モデル(LLM) や、RAG開発ツール「Dify」などをプレインストール・セットアップ したオールインワンソリューションです。
さらに、業務活用セットには、RAG回答精度改善・運用支援ツール「G-RAGon」 を標準搭載。RAGの回答精度向上をサポートし、チューニングの負担を大幅に軽減します。
また、「使い方マニュアル」や「Q&Aチケット」 も付属し、導入後のサポートも充実。
LLM/RAGシリーズを導入することで、構築作業の手間を削減し、スムーズにLLM/RAGの開発・運用を開始できます。
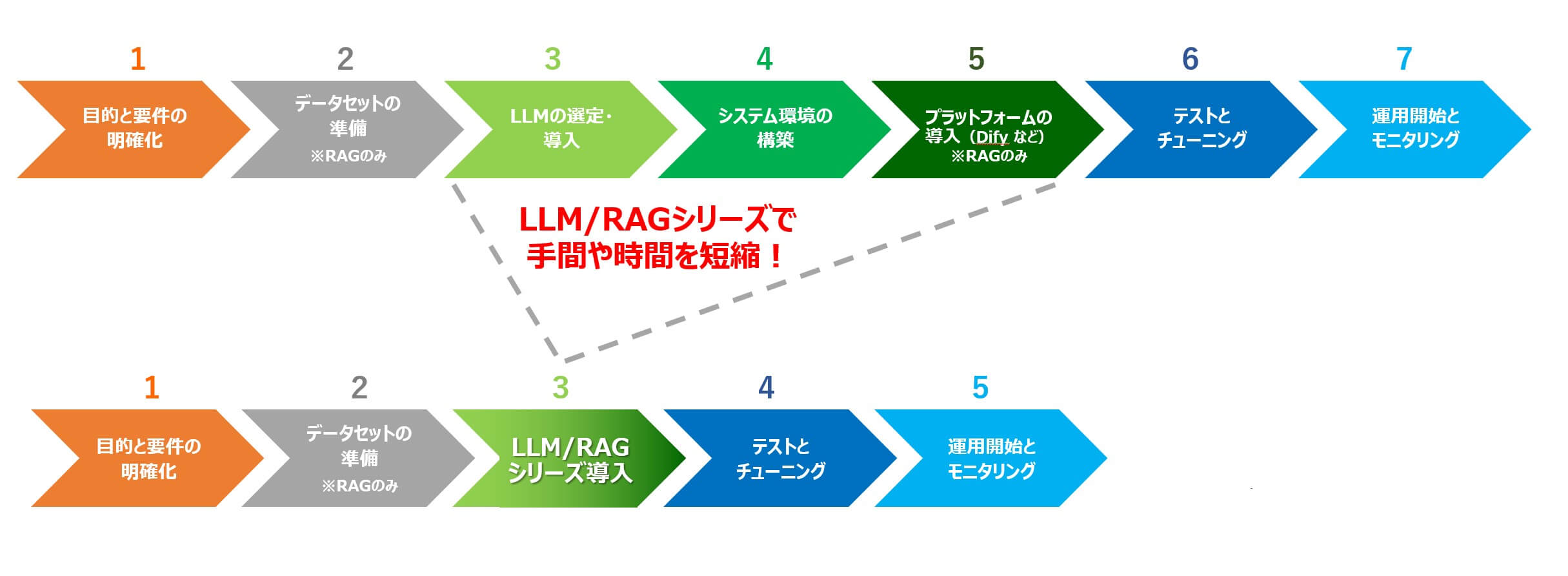
--- LLM/RAG構築作業の流れ ---
LLMやRAGの導入には「LLMモデルの選定」「ハードウェア準備」「開発環境のセットアップ」など、
多くの工程が必要で時間とコストがかかります。
LLM/RAGシリーズなら、これらの手間を削減し、スムーズに開発・運用を開始可能。
「RAGの導入を効率化したい」「システム構築の負担を減らしたい」と考える企業に最適なソリューションです。
LLM/RAGシリーズの特長
セキュアなローカル環境
オンプレミスで運用するため、機密情報の流出リスクを最小限に抑え、安全なAI環境を実現します。
GPU搭載で高性能処理
最新のNVIDIA GPUを搭載し、大規模言語モデル(LLM)の推論やRAGのデータ検索・処理をスムーズに実行できます。
LLM/RAGに必要なツールをプレインストール
Llama や Gemma などのLLMモデル、RAG開発ツール「Dify」などをセットアップ済み。
導入後すぐに開発をスタートできる環境を提供します。
「G-RAGon」により初期回答精度80%を実現!※1
独自開発した「G-RAGon」は短期間でRAGの精度を向上させることが可能です。
RAGの調整にかかる手間を削減し、より正確な応答を実現します。※1当社社内チャットボット検証結果
目的や用途に応じたラインナップ
以下のモデルをご用意しています。
1. LLM/RAGスターターセット:LLM/RAGの試験導入に最適なスタンダードモデル
2. LLM/RAG業務活用セット:RAG初期回答精度80%達成!「G-RAGon」搭載モデル
システム構築から初期導入サポートまでワンストップ
システム環境構築からツール設定、初期導入のサポートまで一貫対応。
「使い方マニュアル」と「Q&Aチケット」により、導入後も安心してお使いいただけます。
LLM/RAGシリーズ こんな方におすすめ!
・ クラウドではなく、安全なローカル環境でLLM/RAGを運用したい方
・ RAGの精度を向上させたい方
・ 企業の業務効率化に生成AIを活用したい方
・ 製造業・金融・医療など、高度なセキュリティが求められる業界の方
・ Ubuntu環境でLLM/RAGを運用・管理できる方
LLM/RAGシリーズ ラインナップ
LLM/RAGスターターセット
LLM/RAGの試験導入に最適なスタンダードモデル

1,628,000 円 ~
LLM/RAG業務活用セット
RAG初期回答精度80%達成!「G-RAGon」搭載モデル

2,128,000 円 ~
LLM/RAGプレインストールソフトウェア
推論に最適なNVIDIA GPUを搭載したワークステーションに、OS、GPUドライバー、ユーザインターフェース、AIモデルを含むAI実行ツールまでをプレインストールし、導入後すぐに利用を開始できる環境を提供します。
エントリー/ミッドレンジモデルによって、プレインストールされているソフトウェアが異なります。詳細は各製品ページよりご確認ください。
今後も順次、対応アプリを追加予定です。インストール内容のカスタマイズをご希望の場合は、お気軽にご相談ください。
| プレインストール AIアプリケーション フレームワーク | ユーザインターフェース/ AIアプリケーション開発ツール | Dify OpenWebUI |
| AIモデル実行ツール | Ollama Xinference | |
| 生成AIモデル | Meta Llama 3 [8Bモデル / 70Bモデル] Google Gemma 2 [9Bモデル / 27Bモデル] Microsoft Phi-4 [14Bモデル] Qwen2.5 [14Bモデル / 32Bモデル] QwQ [32Bモデル] | |
| Embeddingモデル | nomic-embed-text | |
| Rerankingモデル | bge-reranker-v2-m3 | |
| RAG検索精度改善支援ツール ※業務活用セットのみ | G-RAGon | |
| パートナーアプリ | blueqatRAG | |
| Q&Aチケット | チケット 3 枚 | |
・Dify:RAG型のAIアプリケーションの開発に適したユーザ向けツール
・Open WebUI:ChatGPTライクなOllama用のユーザ向けツール
・Ollama, Xinference:ローカル環境で様々なAIモデルを動かすことができるツール
・生成AIモデル:テキストなどの新しいコンテンツを生成することを目的としたAIモデル
・Embeddingモデル:RAGを利用する際に文や単語を数値ベクトル(埋め込みベクトル)に変換するモデル。これにより、類似度計算を効率的に行えるようにします。
・Rerankingモデル:検索結果を再評価・再ランキングするために使用されます。検索結果を、よりユーザーの意図に合った形で並び替える役割を持ち、精度向上を目的とします。
よくある質問(FAQ)
Q1. LLMとRAGの違いは何ですか?
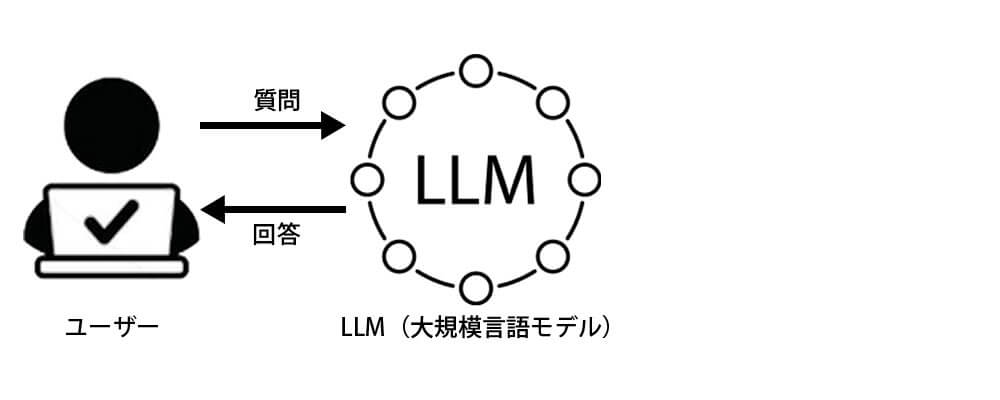
LLM
LLM(大規模言語モデル:Large Language Model)は、膨大なテキストデータを学習し、文章の生成・要約・翻訳・コード補完などを行うAI技術です。
代表的なものとして「Llama」「Gemma」などのオープンソースモデルがあり、企業の業務効率化に活用されています。
一般的な知識に関する質問には対応できますが、社内文書や企業独自のデータに基づいた回答を生成するにはRAGを構築する必要があります。
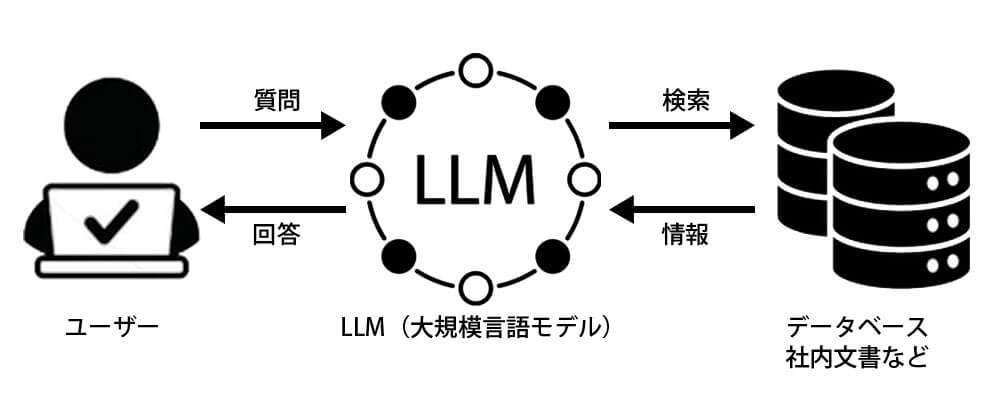
RAG
RAG(検索拡張生成:Retrieval-Augmented Generation)は、LLMに社内等のデータを参照させ、より正確な回答を生成する技術です。
LLM単体では学習データに基づいた一般的な回答しかできませんが、RAGを活用することで、企業の独自データを組み合わせ、業務に特化した精度の高い応答を可能にします。
Q2. クラウドとローカル環境(オンプレミス)の違いはなんですか?
A. クラウド環境とローカル環境(オンプレミス)の大きな違いは、データの管理方法、運用の自由度、コストのかかり方 にあります。
クラウド環境 は、クラウドサービスプロバイダーが提供するインフラを利用するため、初期導入が容易で、サーバー管理の手間が少なく、必要に応じてリソースを柔軟に拡張できる というメリットがあります。
しかし、データが外部に保存されるため、機密情報の管理が難しい ことに加え、長期的にはクラウド利用料やデータ転送コストが積み重なり、運用コストが増大するという課題があります。また、ネットワーク環境によっては通信遅延が発生する可能性 もあります。
ローカル環境(オンプレミス) は、機密情報を外部に送信することなく、社内のシステム環境で安全に運用できるため、医療・金融・製造業など、セキュリティ要件が厳しい業界で広く採用 されています。
また、ネットワークに依存しないため、低遅延で高速な処理 が可能であり、長期的にみるとコストを抑えられる というメリットもあります。初期導入にハードウェアの準備が必要ですが、一度環境を構築すればランニングコストを削減し、安定した運用 が可能になります。
Q3. ローカルLLM/RAGの導入でどのようなメリットがありますか?
A. ローカル環境でLLMやRAGを運用することで、企業独自のナレッジを活かしながら、高度なAIソリューションを安全かつ効率的に実現 できます。
特に、セキュリティ・パフォーマンス・コストの観点から、ローカルLLM/RAGの活用は今後ますます重要 になっていくと考えられます。
データセキュリティの向上
クラウドサービスとは異なり、オンプレミス環境(企業内部のワークステーションやサーバー)で運用するため、データが外部に漏れるリスクを大幅に低減 できます。
特に 機密情報や顧客データを扱う企業にとって、データセキュリティは最優先事項 です。
低遅延と高パフォーマンス
ローカル環境では、インターネット接続に依存せず、ネットワーク遅延を抑えながら高速処理が可能 です。
そのため、リアルタイムでのデータ処理や迅速な応答が求められる業務に最適 です。
長期的なコスト削減
クラウドサービスは、利用するほどランニングコストが増加 しますが、ローカル環境での運用なら、継続的なクラウド利用料金を削減し、より高いコスト効率を実現 できます。
初期投資は必要ですが、長期的にはコストを抑えながら、高性能なAIを活用し続けることが可能 です。
Q4. RAGの検索精度を向上させる方法はありますか?
A. はい、以下の方法でRAGの検索精度を向上させることができます。
- データの整理:検索対象となる社内文書やFAQを適切に整理し、情報をわかりやすく構成することで精度が向上します。
- ベクトル検索の最適化:RAGは文書を小さな単位(チャンク)に分割して検索します。適切なサイズで分割し、検索しやすい形に整えることが重要です。
- プロンプトエンジニアリング:質問の仕方を工夫し、LLMが適切な回答を出せるように調整することで精度を改善できます。
「LLM/RAG業務活用セット」には、RAG回答精度改善・運用支援ツール 「G-RAGon(ジー・ラグ・オン)」 が標準搭載されています。
G-RAGonは、RAGの検索精度向上をサポートする独自の機能を備えており、手作業でのチューニングにかかる時間と労力を削減し、より正確な回答が得られる環境を構築できます。
Q5. LLM/RAGスターターセットと業務活用セットの違いは?
A. 違いは、「G-RAGon」が搭載されているかどうか です。
- LLM/RAGスターターセット
→ LLMやRAGの試験導入や、基本的なRAG構築・運用を行いたい方向け
→ Difyなどの一般的なRAGツールをそのまま活用し、自社で調整できる方に最適 - LLM/RAG業務活用セット
→ RAG検索精度を向上させる「G-RAGon」を標準搭載!
→ RAGの精度向上に時間をかけたくない、すぐに業務適用したい方におすすめ
RAGの検索精度向上のノウハウがあり、手動で最適化できる方はスターターセットで十分!
効率よくRAGを調整し、高精度な検索システムを早期に構築したい方は業務活用セットがおすすめ!
どちらが最適か迷われる場合は、お気軽にご相談ください。
Q6. LLM/RAG構築の手順について教えてください。
LLMやRAGの導入にはいくつかの重要なステップがあり、それぞれの工程を適切に進めることで、より精度の高いAIシステムを構築できます。以下に、基本的な手順をご紹介します。
目的と要件の明確化
LLMまたはRAGを導入する目的と、システムに求める要件を明確にします。
LLM単体の活用例(文書の自動生成、要約、翻訳、コード補完 etc)、RAGの活用例(社内FAQシステムの自動化、製品サポートの応答精度向上 etc)目的に応じて、必要なデータや適切なモデルを選定することが重要です。
データセットの準備(※RAGの場合のみ)
RAGでは、生成AIが外部データを活用するため、適切なデータセットを準備します。
準備するデータの例(社内ドキュメント、FAQデータ、製品マニュアル、カスタマーサポートのログ、規約データ etc)
※ LLM単体の場合はこのステップは不要です。
LLMの選定・導入 → LLM/RAGシリーズ
LLMまたはRAGで使用する大規模言語モデル(LLM)を選定します。
業界や用途に適したモデルを選ぶことで、より正確でカスタマイズされた応答を実現できます。代表的なモデルには、LlamaやGemmaなどがあります。
LLM/RAGシリーズには、これらのモデルが導入済みで、すぐに利用できます。
システム環境の構築 → LLM/RAGシリーズ
LLMやRAGをスムーズに動作させるために、適切なハードウェア環境を構築します。
GPUを搭載したワークステーションやサーバーなどの高性能なインフラを準備し、モデルの実行やデータ処理に対応できる環境を整えます。
LLM/RAGシリーズでは、NVIDIA GPU 搭載ワークステーションをご用意しています。
開発プラットフォームの導入(※RAGの場合のみ) → LLM/RAGシリーズ
RAGを構築するためには、DifyやLangChainなどのRAG開発ツールを活用します。これらのツールを導入し、選定したLLMと連携させるための設定を行います。これにより、外部データをリアルタイムで参照する仕組みを構築します。
LLM/RAGシリーズには、これらのツールもプレインストール・セットアップ済み。
テストとチューニング
初期設定が完了したら、テストを行い、実際の応答精度やシステムのパフォーマンスを確認します。初めにテストケース用のデータセットを読み込ませて、想定した応答精度が得られるかを確認し、必要に応じてデータセットの修正やハイパーパラメータのチューニングを行います。十分な結果が得られたらデータセットを順次読み込ませていきますが、各データセット毎に、応答精度を検証していきます。
※RAGの応答精度が上がらない原因のほとんどがデータセットにあります。
運用開始とモニタリング
十分な応答精度が得られることを確認したら、運用を開始します。運用中も、定期的にモニタリングを行い、必要に応じてモデルの更新やデータセットの拡充を行っていきます。運用後のメンテナンスもスムーズに行える体制を整えることが重要です。