深層学習におけるアノテーションコストを抑えるための取り組み"Active Learning" について

深層学習におけるアノテーションコストを抑えるための取り組み"Active Learning" について
青木 義満 先生
慶應義塾大学 教授
1. 深層学習とアノテーション
近年、画像センシング分野における研究開発の成果は、深層学習の進化により、実社会の様々な場面で利活用されています。
機械学習、特に深層学習においては、ネットワークモデルの学習において、大規模な教師データ(ラベル付きデータ)が必要となります。
例えば、画像のクラス分類タスクにおいては、画像ごとにその意味内容を表すラベルを付与したり、物体検出タスクにおいては、物体を矩形で指定する作業が必要となります。
これらのラベル付きのサンプルを得るためのアノテーション作業は、時間とコストがかかるため、実用上大きな問題となります。
2. アノテーション作業を減らすための工夫
アノテーション作業のコストを減らすための方法として、教師なし学習、半教師あり学習、Active Learningなどの学習手法が近年、注目されています。
教師なし学習や、半教師あり学習はラベル付けされていないサンプルを十分に利用してモデルを学習させることを目的としています。
一方、Active Learningは教師データを作成する際、大量のデータの全てに対してアノテーションをするのではなく、モデルの学習に効果的なサンプルを優先するようにアノテーションを行うことによって、アノテーションの総量を少なく抑えながら教師データの作成とモデルの学習を行うことを目的としています。
ここでは、アノテーション作業を効率化するための、Active Learning研究の取り組みについて、紹介します。
3. Active Learningに関する取り組み事例
Active Learningには大きく3つの潮流があります。
- モデルの学習に有効なデータを生成するアプローチ(membership query synthesis)
- データに対してラベル付するか破棄するかのふるい分けを行うアプローチ(stream-based selective sampling)
- ラベル無しデータプールの中からモデルを学習させる上で最も効果が高いサンプルを選択するアプローチ(pool-based sampling)
これらの中でも図1に示すpool-based samplingは最も一般的な手法となっています。
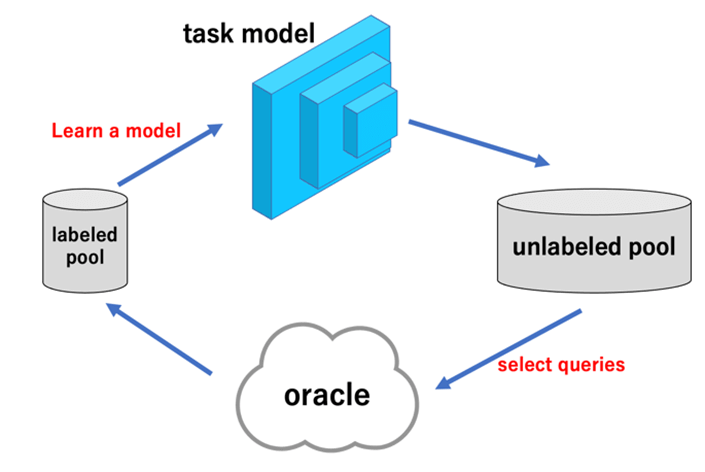
Pool-based samplingで主流になりつつある方法は敵対的学習を用いた方法です。
この手法ではVAE(Variational Auto Encoder)と呼ばれる方法で画像を低次元表現に一度落とし込み、得られた低次元表現がラベル付きサンプル由来なのか、ラベル無しサンプル由来なのかをDiscriminatorが判別します。
VAEとDiscriminatorを敵対的に学習させることにより、ラベル無しデータプールからモデルがまだ得ていない特徴を持つラベル無しサンプルを選択することができるのです。
この手法は画像特徴からサンプリングを行なっているため、分類やセグメンテーションといったタスクによらないActive Learningを行うことができる利点があります。
一方で、タスクの学習以上に時間がかかるという欠点もあります。
4. 不確実性サンプリング
私たちは、このActive Learningの課題に対し、新たなモデルで推論を行う際に推論結果の不確実性が最も高いデータからラベル付けをしていく、不確実性サンプリング指標を活用したアプローチをしています(図2)。
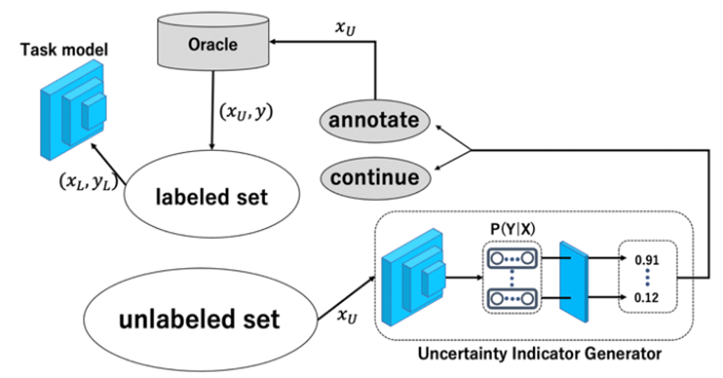
まず、少数のラベル付きプールのデータを用いてタスクモデルを一度、学習させます。
その後、学習済みのタスクモデルを用いた不確実指標生成器(図中のUncertainty Indicator Generator)にラベル無しプールのサンプルを入力して、サンプルごとの不確実指標を出力します。
この不確実指標の上位K個を選択し、それらを優先してアノテーションを行います。
モデルで推論を行う際に推論結果の不確実性が最も高いデータを優先してラベル付けするということです。
これは、これにより、最小限のアノテーションコストで高い性能を得ることができます。これは、テスト対策で「複数回解いた分かる問題」よりも「まだ観たことのない問題」を対策した方が成長に繋がるのと同じようなことです。
提案している方法では、ラベル無しプールのサンプルごとの不確実性を[0,1)の連続値を用いて異なる重要度で表すように設計しています。
不確実性指標生成器は、対象モデル(画像分類器、セマンティックセグメンテーションモデル)の予測ベクトルに基づいて不確実性指標を計算します。
具体的には、画像分類の場合、予測は各カテゴリの確率ベクトル、セグメンテーションでは、各画素は確率ベクトルを持ち、予測ベクトルは各確率ベクトルの平均値となります。
不確実性指標の定式化と計算方法については、ここでは割愛しますので、文献[1]を参照して下さい。
ここでわかりやすい例を示します。
犬,猫,虎の3クラス分類の問題を考えます。
ラベル無し画像Aに対してタスクモデルが(犬,猫,虎)=(0.6, 0.1, 0.3)と判断し、ラベル無し画像Bに対して(犬,猫,虎)=(0.4, 0.4, 0.2)と判断した場合、この不確実性指標生成器による出力は、前者が0.49, 後者が0.9となり、後者の画像Bの方が不確実性が高いと言えるので、こちらを優先的にアノテーションした方が効率が良いということになります。
5. Active Learningの効果は?
ここでは、画像分類とセマンティックセグメンテーションのタスクで、この手法の効果を確認します。
Active Learningの先行研究であるVAAL[2]、ランダムにサンプリングした際の結果と比較して評価してみました。
画像分類とセマンティックセグメンテーションでは、データセットの全体10%のサンプルをランダムにサンプリングしてラベル付きデータ、残りの90%をラベル無しデータとして実験を開始します。
ラベル付きデータが全体の40%になるまで5%ずつサンプリングを行い、各データセットにおける性能を先行研究、ランダムサンプリングの結果と比較します。
評価指標は、画像分類では正解率(Accuracy)、セマンティックセグメンテーションではmean Intersection Over Union (mIOU)を使用しています。
画像分類ではCIFAR-100[1]を用い、セマンティックセグメンテーションではCityscapes[6]を使いました。
図3にCIFAR100の結果、図4にCityscapesの結果を示します。
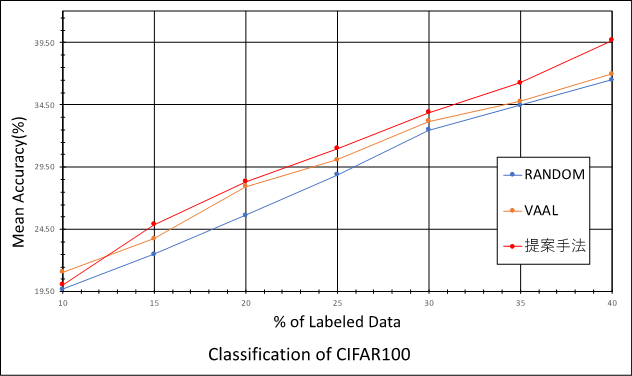
15%以降のサンプリングで、VAAL、ランダムサンプリングよりも提案手法は精度が高いことが分かります。
また、実行時間で比較すると提案手法は画像分類で約10分の1、セグメンテーションでは約2分の1の時間になっていることが分かりました。
6. まとめ
ラベル無しプールから最も情報量の多いサンプルを選択するために、タスクモデルの出力結果から最も情報量の多いラベル付けされていないサンプルを導出する不確実性指標生成器によって、使用するラベル付きデータの量を減らすことでアノテーションコストを低下させることができることを示しました。
また、モデルの実行時間も従来手法と比較してCIFAR-100では約10分の1に、Cityscapesでは約2分の1程度に削減可能なことを示しました。
深層学習におけるアノテーションコストを抑える取り組みは、実用上非常に重要なものとなっており、この取り組み以外にも様々な新手法が続々と提案されています。
今後のこの分野の研究の進展に是非、ご注目下さい。
【参考文献】
[1] Active Learningにおける不確実サンプル選択によるアノテーション効率化川野恭史,野田祥希,望月凜平,青木義満
第27回画像センシングシンポジウ(SSII2021),IS2-17, June 2021. [2] Samarth Sinha, Sayna Ebrahimi, and Trevor Darrell. Variational adversarial active learning. arXiv preprint arXiv:1904.00370, 2019.
著者紹介

青木 義満 先生
慶應義塾大学 理工学部 電気情報工学科 教授
慶應義塾大学理工学部電気情報工学科教授
2001 年早稲田大学理工学研究科にて博士(工学)取得
2002 年芝浦工業大学工学部情報工学科講師、准教授
2008 年より慶應義塾大学理工学部電子工学科 准教授
2017 年、同大学教授
現在、画像センシング技術,画像パターン認識技術に関する研究に従事
電子情報通信学会,画像電子学会,映像情報メディア学会,IEEE会員
日本顔学会理事
画像センシング技術研究会会長

