深層学習に基づく人物画像の再照明

深層学習に基づく人物画像の再照明
金森 由博 先生
筑波大学 准教授
1.はじめに
深層学習 (Deep Learning) によって、従来は考えられなかったような驚くべき成果が毎日のように世に現れています。
ニューラルネットワークの基本構成要素である畳み込み層が、規則的かつ密に並んだデータの扱いを得意とすることから、CGやコンピュータビジョンの分野では特に、画像を対象とした成果が多く報告されています。
深層学習 (Deep Learning) によって、従来は考えられなかったような驚くべき成果が毎日のように世に現れています。
本稿では画像を対象とした深層学習の応用事例のうち、我々にとって最も身近な人物画像を対象として、「再照明」という技術をご紹介します。

2. 再照明 (relighting) とは?
ある照明環境下で撮影された物体を、他の照明環境下に持っていった場合に、どのような陰影がつくかシミュレーションする技術を再照明 (relighting) と呼びます。
再照明を物理ベースで実現しようと思ったら、陰影を構成する3つの要素、つまり、光源、物体の色 (反射率)、そして物体の形状の情報が必要となります。
ゲームや映画などの3DCGであれば、事前に物体の形状や色の情報はソフトウェアで指定するなり計測するなりしておけばOKです。
後はロケ地などで撮影された、周囲から差し込む光の情報 (環境光源) を使って陰影計算を行えば、写実的な画像が得られます。
人物を対象とした色や形状の計測には、南カリフォルニア大 (現Google Research)のPaul Debevec ら [1] が開発したLightStageと呼ばれるドーム状の撮影装置 [2] が有名で、ハリウッド映画などで使われています。
しかし、再照明のたびに物体の色や形状を計測するのは大変です。
ましてやLightStageのような撮影装置は大変高価なので簡単には利用できません。
一方でもし、人物の画像だけで再照明ができれば専門知識のない人であっても、例えばハリウッド映画ばりの合成写真を作るといったエンタメ用途から、証明写真を撮影した後で陰影を調整するといった実用的な応用もできます。
さらに動画に適用できれば、Zoomなどの遠隔会議中に、単に仮想背景を変えるだけでなく一緒に人物の陰影を変えることで、没入感を高めることができます。
こういった応用を実現する人物画像の再照明が、深層学習によって実現しつつあります。
3. 逆レンダリングによる再照明
人物画像を入力として再照明を行う1つのやり方は、上述の3DCGでの再照明のように、陰影計算に必要な、被写体の色や形状を入力画像から推定する、というものです。
この推定計算は、通常のレンダリングで光源、形状、色の情報が既知の状態で計算するのとは逆に、描画結果に相当する画像から入力情報を得ようとするものなので、逆レンダリング (Inverse Rendering)と呼ばれます。
しかし逆レンダリングは、少ない情報からより多くの情報を得ようとする不良設定問題のため、解くのが難しいです。
深層学習が登場してからは、大量の教師データを使って事前に学習しておくことで、統計的にそれらしい推定をできるようになりました。
「陰影を計算するには光源、物体の色および形状の情報が必要」と書きましたが、より具体的にはこれら3要素についての積分を計算する必要があります。
物体表面の各点でまじめに積分計算をやると時間がかかるので、基底関数を利用して計算を効率化する、というアプローチが採用されています。
基底関数としてよく使われるのは球面調和関数 (Spherical Harmonics) です。
球面調和関数は球面上で定義されたフーリエ級数のようなもので、これを利用すると、基底関数の係数列からなるベクトルの内積を計算することで積分計算が実現できます。
ベクトルの内積計算ならGPUを使って高速に計算できます。
4. 人物画像に対する再照明
話を戻して、では人物画像に逆レンダリングを適用するにはどうするかというと、球面調和関数を利用できます。
前述の積分計算では、本当は「いろいろな方向から届く光が物体に遮られるか・遮られないか」という光の遮蔽に関する情報を考慮する必要があります。
この光の遮蔽を考慮すると積分計算が面倒になるのですが、ほぼ凸な形状なら光の遮蔽は発生しないものとして近似できます。
「ほぼ凸な形状」の典型例が人物の顔です。
なので顔画像を対象とし、球面調和関数に基づいて、光の遮蔽を無視して逆レンダリングを行う手法が多数提案されています。
顔でそれらしい再照明ができるからと、同じことを人物の全身画像でやろうとすると問題が起きます。
顔は (鼻の周りを除いて) ほぼ凸形状ですが、全身だと首の下、脇や衣服のシワの部分などは凹んでいます。よってそのような部位では、もはや光の遮蔽を無視できなくなります。
そこで、手前味噌ですが、我々は光の遮蔽まで考慮して逆レンダリングを行う手法 [3] を提案しました。
図 1 に光の遮蔽を考慮しない場合とする場合の数式と模式図を示します。
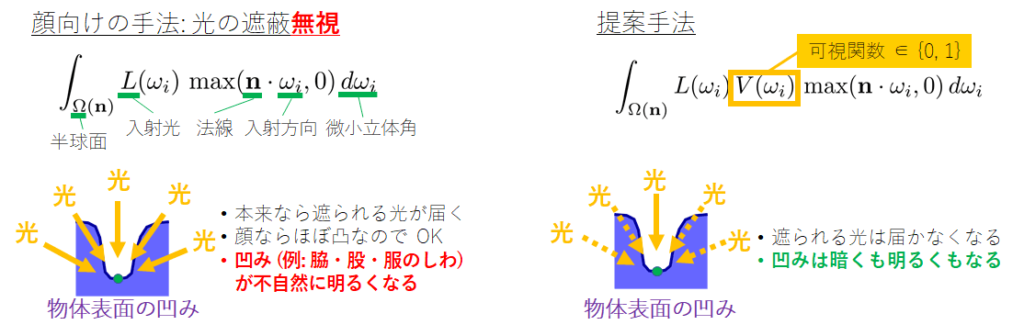
我々が解決すべき課題は「光の遮蔽を考慮すると積分計算が面倒」な点です。
どうやったかというと、光の遮蔽まで含めた球面調和関数の係数を予めがんばって計算しておいて、それを教師データとして学習する、というアプローチを採りました。
具体的には、3Dスキャンされた3D人物モデルを数百体購入し、そのデータに対し自作GPUレンダラを使って、光の遮蔽を考慮した球面調和関数の係数を計算しました。
図 2 に、逆レンダリングで得られる陰影マップ (物体の色を除外して光源と形状だけで決まる陰影画像) について、光の遮蔽を無視する場合と考慮する場合の結果画像を示します。
これらの結果を比較してみると、光の遮蔽を考慮しない場合は凹んだ部分が不自然に明るくなるのに対し、我々の結果では比較的自然な陰影になっています。

我々が研究成果を発表した2018年当時は、Chainerという深層学習ライブラリを用いて開発していましたが、その後、うちの研究室の学生がPyTorchというライブラリに移植してくれました。
PyTorch版で1024×1024画素の人物画像を入力した場合、逆レンダリングにかかる時間はGeForce RTX 2080 Ti とQuadro RTX 8000で試すと1枚あたり68ミリ秒程度でした。
逆レンダリングによって人物画像の色と形状の情報を抽出し終えれば、再照明は画素ごとにベクトルの内積を計算するだけなので、非常に高速に処理できます。
我々のプロジェクトページ http://kanamori.cs.tsukuba.ac.jp/projects/relighting_human/index-ja.html で訓練済みネットワークモデルを公開していますので、ご興味のある方は試してみてください。
さらに最近、我々の方法を拡張し、動画にも適用できるようにしました。
動画に適用する場合の単純なやり方は、入力動画を1コマずつ静止画に分解し、1コマずつ処理し、結果画像を連結して動画にする、というものです。
ただそうすると、前後のコマを考慮できず、チラつきが発生してしまいます。
我々の手法の拡張版では、そのチラつきを抑えて出力できるようになっています (図3)。
図 3: 我々の手法を動画に拡張してチラつき対策まで施した結果 (※動画)
5. 人物画像の再照明に関する最近の研究
我々が2018年に論文を発表したあたりから、人物の顔だけでなく衣服も含めた自撮り画像に対して再照明できる手法が登場しています。
特に、冒頭で述べたGoogle Research のPaul Debevecらのチームが、LightStageで撮影されたデータを使った高品質な再照明手法を次々に提案しています。
LightStageを使うと、ある1方向から光を照らした場合の被写体の画像を撮影することができます。
そのような画像を OLAT (One-Light-at-A-Time) 画像と呼びます。
OLAT画像には表面下散乱や相互反射なども含めたすべての光学効果が含まれており、いろいろな方向から光を照らした際のOLAT画像を重み付けすることで、理論上は任意の光源に対して写実的な画像を作ることができます。
例えば彼らの2019年の研究 [4] では、このOLAT画像をニューラルネットワークで推定する、ということを行っています。
6. おわりに
人物を対象とした再照明はCG分野で今ホットな研究テーマで、前述のGoogle Researchを始め、Facebook Reality Labなどが多数論文を発表しています。
高品質な結果は得られるようになってきたものの、まだ高品質かつリアルタイムな手法は現れていないように思います。
しかし近いうちに、Zoomなどであたかもリゾート地にいるかのような写実的な映像を、リアルタイムで合成できるような未来が来るかもしれません。
【参考文献】
[1] Paul Debevec Home Page. https://www.pauldebevec.com/
[2] LightStage. https://home.otoy.com/capture/lightstage/
[3] Yoshihiro Kanamori, Yuki Endo: "Relighting Humans: Occlusion-Aware Inverse Rendering for Full-Body Human Images," ACM Transactions on Graphics (Proc. of SIGGRAPH Asia 2018), 37, 6, pp.270:1-270:11, November 2018.
[4] Tiancheng Sun, Jonathan T. Barron, Yun-Ta Tsai, Zexiang Xu, Xueming Yu, Graham Fyffe, Christoph Rhemann, Jay Busch, Paul Debevec, Ravi Ramamoorthi: "Single Image Portrait Relighting," ACM Transactions on Graphics (Proc. of SIGGRAPH 2019), 38, 4, pp.79:1-79:12, July 2019. https://www.youtube.com/watch?v=yxhGWds_g4I
著者紹介

金森 由博 先生
筑波大学 システム情報系 准教授
2009 年 3月 東京大学情報理工学系研究科コンピュータ科学専攻博士課程修了.博士(情報理工学).
同年 4月より筑波大学に勤務し,現職は筑波大学システム情報系・准教授.
2014 年~2016 年にスイス連邦工科大学チューリッヒ校 (ETHZ),
2019 年にエディンバラ大学に客員研究員として滞在.コンピュータグラフィックス (CG) およびコンピュータビジョン (CV) に関する研究に興味を持つ.最近は特に,深層学習の CG や CV への応用に取り組んでいる.
情報処理学会, 画像電子学会, 芸術科学会各会員.