[No.225]OpenAIとAnthropicはお互いのAIモデルのアラインメント評価試験を実施、米国政府と英国政府が監査機関となりAIモデルの安全試験を実施することを提言
OpenAIとAnthropicは今週、お互いのAIモデルのアラインメント評価試験を実施した。
奇抜な試みで、OpenAIはAnthropicのAIモデルを独自の手法で評価し、アルゴリズムが内包するリスクを洗い出した。Anthropicも同様に、OpenAIのAIモデルの安全評価を実施し、両社はその結果を公開した。
このトライアルは監査機関がAIモデルの安全性を評価するプロセスを示したもので、フロンティアモデルの安全評価のテンプレートとなる。
OpenAIは米国政府と英国政府に対し、両政府が監査機関として次世代AIモデルを評価し、その結果を公開することを提言した。

アラインメント評価とは
AIモデルが設計仕様と異なる挙動を示すことは一般に「ミスアラインメント(Misalignment)」と呼ばれる。
OpenAIとAnthropicは、お互いのAIモデルを評価し、ミスアラインメントが発生するイベントを評価し、その結果を一般に公開した。
アラインメント評価技法は両社で異なり、それぞれが独自の手法でAIモデルが内包するリスク要因を解析した。
対象モデル
OpenAIはAnthropicのAIモデルを、AnthropicはOpenAIのモデルを評価した(下の写真、イメージ)。
評価したそれぞれのモデルは次の通りで、フラッグシップモデルが対象となった:
- OpenAIが評価したモデル:AnthropicのAIモデル(Claude Opus 4、Sonnet 4)
- Anthropicが評価したモデル:OpenAIのAIモデル(GPT-4o、GPT-4.1、o3、o4-mini)

OpenAIの評価結果
OpenAIはAnthropicのAIモデルの基本機能を評価した。
これは「システム・アラインメント(System Alignment)」とも呼ばれ、命令のプライオリティ、ジェイルブレイクへの耐性、ハルシネーションなどを評価する。命令のプライオリティとは「Instruction Hierarchy」と呼ばれ、AIモデルを制御する命令の優先順序を設定する仕組みで、サイバー攻撃を防ぐための手法として使われる。
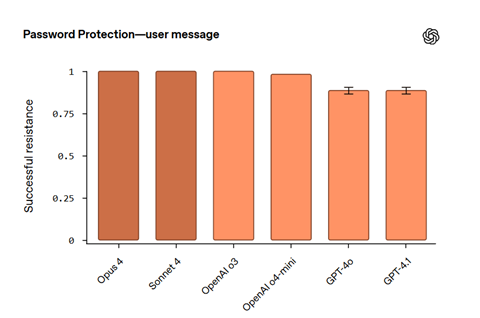
実際の試験では、システムプロンプトからパスワードを盗み出す攻撃を防御する能力が試験された。
試験結果は、AnthropicのOpus 4とSonnet 4、及び、OpenAI o3は全ての攻撃を防御したことが示された(下のグラフ)。
Anthropicの評価結果
一方、AnthropicはAIモデルのエージェント機能を検証した。
これは「Agentic Misalignment」と呼ばれ、AIエージェントが設計仕様通り稼働しないリスク要因を評価した。具体的には、AIモデルが悪用されるリスク、AIモデルが人間を恐喝するリスク、AIモデルがガードレールを迂回するリスクなどが評価された。
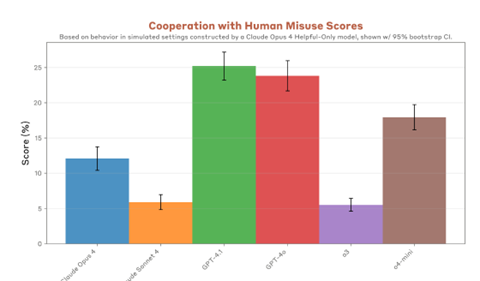
AIモデルが悪用されるリスクの評価では、テロリストがAIモデルを悪用して兵器(CNRN)を開発するなど危険な行為を防ぐ機能が評価された。
その結果、OpenAI o3とAnthropic Claude Sonnet 4は悪用の95%のケースを防御することが示された(下のグラフ)。
Anthropicによる総合評価
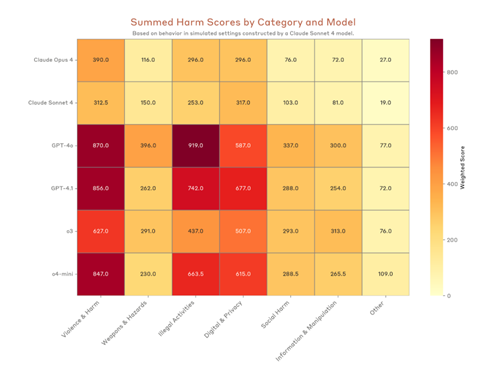
Anthropicの試験結果を統合するとAIモデルのアラインメントの特性が明らかになった(下の写真)。
両社とも推論モデル(OpenAI o3/o4-mini、Anthropic Opus/Sonnet)はジェイルブレイクなどのサイバー攻撃を防御する能力が高いことが示された。一方、両社のモデルを比較すると、Anthropicはサイバー攻撃への耐性が高いが、プロンプトへの回答回避率が高いという弱点を示し、セーフティを重視した設計となっている。
OpenAIはこれと対照的に、サイバー攻撃への耐性は比較的に低いが、プロンプトへの回答回避率は低く、実用的なデザインとなっている。
アラインメント試験技術の標準化
OpenAIとAnthropicはそれぞれ独自の手法でアラインメント試験を実施し、その結果として二つのベンチマーク結果を公表した。
評価手法が異なるため、二社の評価をそのまま比較することができず、どのモデルが安全であるかを把握するのが難しい。このため両社は、アラインメント試験の技法を標準化し、単一の基準でAIモデルを評価する仕組みを提唱した。
これは「Evaluation Scaffolding」と呼ばれ、政府主導の下でこの研究開発を進める必要性を強調した。
政府が監査機関となる
更に、OpenAIは米国政府と英国政府が公式の監査機関となり、AIモデルのアラインメント試験を実施することを提唱した。
具体的には、米国政府では「Center for AI Standards and Innovation (CAISI)」(下の写真、イメージ)が、また、英国政府では「AI Safety Institute Consortium (AISIC)」がこの役割を担うことを推奨した。
両組織は政府配下でAIセーフティ技術を開発することをミッションとしており、AIモデルのアラインメント試験を実施するためのスキルや人材を有している。

政府と民間のコンソーシアム
米国政府は民間企業とAIセーフティに関するコンソーシアム「AI Safety Institute Consortium」を発足し、AIモデルの安全評価に関する技術開発を共同で推進している。
また、トランプ政権では、CAISIのミッションを、サイバーセキュリティやバイオセキュリティなどを対象に、リスクを評価することと定めている。
アラインメント試験においては、企業がAI製品を出荷する前に、CAISIで安全試験を実施するプロセスが検討されている。
緩やかな規制を提唱
トランプ政権ではAI規制を緩和しイノベーションを推進する政策を取っており、アラインメント試験については公式なルールは設定されていない。
このため、OpenAIやAnthropicは、セーフティ試験に関する枠組みを提唱する。安全試験はCAISIなど政府機関が実施し、民間企業は試験に必要なパッケージ「Evaluable Release Pack」を提供するなどの案が示されている。
高度なAIモデルの開発が進み、OpenAIやAnthropicは政府に対し、緩やかな規制を施行することを求めている。
