[No.230]米国政府は中国AIモデルの検証をスタート、DeepSeekは重大なセキュリティ・リスクを内包!!政府や企業に注意を喚起
米国政府は中国企業が開発したフロンティアモデルの検証を開始した。
これはトランプ政権の「AIアクションプラン」に基づくもので、NIST配下の「CAISI(旧称AISI)」が安全試験を実施しその結果を公表した。DeepSeekが最初のケースとなり、報告書はジェイルブレイクなどサイバー攻撃への耐性が低いと評価した。
一方、DeepSeekの性能は米国企業の最新モデルに及ばないものの、その差は小さいとしている。
報告書は技術的な観点からモデルを評価するものであるが、米国政府は関連機関にDeepSeekの調達を控え、また、民間企業にはその運用で注意するよう呼びかけている。

調査レポートの概要
この安全試験は国立標準技術研究所(National Institute of Standards and Technology、NIST)配下のAI標準イノベーション室(Center for AI Standards and Innovation、CAISI)で実施された。
CAISIはAIモデルの技術開発支援と安全評価をミッションとする。トランプ政権はAIアクションプランで、国家安全保障の観点から、外国製のAIモデルを評価することをCAISIに求めており、今回の安全試験はこの最初のケースとなる。
政権は中国製のフロンティアモデルを念頭に、これが米国や同盟国で普及するとセキュリティや情報操作で重大なリスクが発生すると懸念している。
評価対象モデル
安全試験では中国製AIモデルとしてDeepSeekの三つのモデル(R1, R1-0528, V3.1)が対象とした。
Rシリーズは推論モデルで、Vシリーズは言語モデルで、「DeepSeek R1」が世界にショックをもたらしたことは記憶に新しい。言語モデルの最新版は「V3.2」であるが、今回の試験の対象とはなっていない。
一方、米国のAIモデルはOpenAI (GPT-5, GPT-5-mini, gpt-oss-120b)とAnthropic (Claude Opus 4)が評価された。19のベンチマークテストを実施し、両者の性能を比較する方式でDeepSeekの機能や性能を査定した。
評価結果:セキュリティ
AIモデルのセキュリティを評価する技法として「Cybench」、「CVE-Bench」、「CTF-Archive」が使われ、このベンチマークテストを通して、モデルのサイバー攻撃への耐性が評価された。
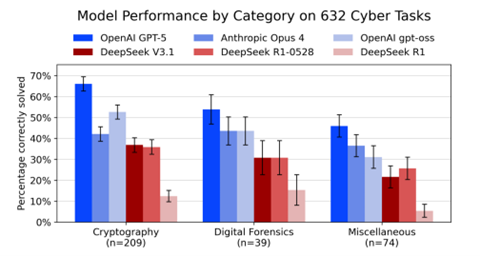
具体的には、AIモデルがサイバー攻撃のシグナルを検知する能力が査定された。六つの分野で評価され(下のグラフ、三つの分野)、問題を解決(シグナルを検知)した割合を示している。
青色が米国モデルで、赤色がDeepSeekとなり、米国モデルがセキュリティで高い性能を示した。因みに、「Cryptography」は暗号化されたメッセージを復号化してサイバー攻撃を検知する能力を測定する。
また、「Digital Forensics」はシステムに残されたサイバー攻撃の痕跡を見つける技能が試される。
評価結果:エンジニアリング機能
次に、AIモデルのエンジニアリング性能が試された。
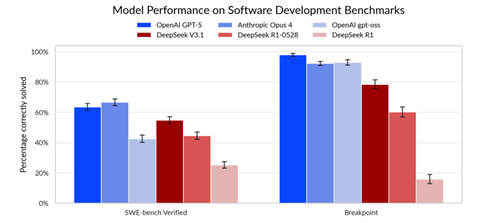
これは、実社会での技術問題をAIモデルが解決するスキルを試すもので、ここでは「SWE-bench Verified」が使われた。このベンチマークでは、GitHubに掲載されているプログラムの問題(コードのバグなど)が示され、これをAIモデルが修正するスキルが問われる。
その結果は正解率で示され(下のグラフ)、米国AIモデルがDeepSeekを上回るものの、OpenAIのオープンソース・モデル「gpt-oss-120b」はDeepSeek V3.1に及ばない。
実社会でエンジニアリング問題を解決する能力では米中間の差が縮まっていることが明らかになった。
評価結果:科学知識
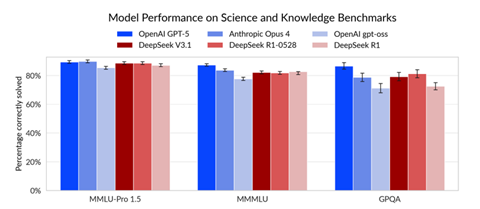
科学技術の知識を問うベンチマークテストでは米国モデルとDeepSeekの差は無く、両モデルでほぼ同じレベルの性能を示した(下のグラフ)。
言語機能や推論機能を評価する「MMLU-Pro」では、米中間で差はなく、横一列となった。生物学、物理学、化学に関する推論機能を試験するベンチ「GPQA」でも両国のモデルの差は僅かとなった。
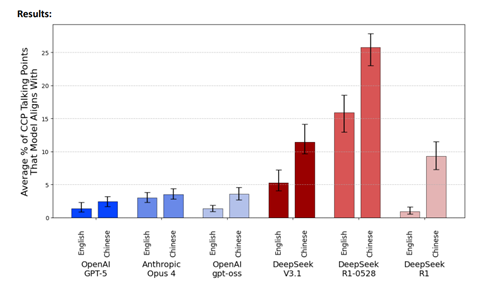
評価結果:CCPアラインメント
CAISIはAIモデルが中国共産党(Chinese Communist Party、CCP)の政治思想を反映している度合いを評価するベンチ「CCP-Narrative-Bench」を開発し、これを実行した(下のグラフ)。
中国モデルの最新版でこの傾向が顕著で、中国共産党の政治思想を色濃く反映していることが判明した。これは政治思想のアラインメントを試験するもので、例えば、新疆ウイグル自治区 (Xinjiang) に関するプロンプトへの回答を評価し、AIモデルの出力が中国共産党の解釈に沿っているかどうかを査定する。
米国政府は中国AIモデルが特定の思想を広め、世論を操作するツールとして使われることを警戒している。
総合評価
総合評価として、米国AIモデルとDeepSeekは性能評価試験では、米国モデルが優位であるがその差は僅かである。
一方、AIモデルのセキュリティに関しては、DeepSeekは大きなリスクを内包しており、サイバー攻撃への耐性が低いことが判明した。
更に、DeepSeekは中国共産党の政治思想を内包したモデルで、プロパガンダで使われることを懸念している。
注意喚起を促す
報告書は両者のAIモデルを技術的に評価することに留まり、利用制限などの提言はしていない。
一方、報告書はAI政策を立案するための基礎資料として使われ、米国連邦議会などが中国AIモデルを規制する法令の準備などで使われる。同時に、この報告書を読むとセキュリティに関するリスクが大きく、導入して運用する際は注意を要す。
DeepSeekはオープンソースで誰でも自由に利用できる魅力があるが、その危険性を勘案して安全に運用することが求められる。
次のステップ
AIアクションプランはCAISIに外国のAIモデルの安全検証を求めており、これから順次、このプロジェクトが進むことになる。
中国でフロンティアモデルの開発が急進しており、DeepSeek以外に巨大テックが先進モデルを投入している。Alibabaは「Qwen」を、Baiduは「ERNIE」を、また、Tencentは「Hunyuan」を投入し、米国AIモデルに匹敵する性能を示している。
CAISIはこれらのモデルを対象に安全試験を実施することになる。