[No.200]中国アリババ・ショック!!推論モデル「QwQ-32B」を投入、小型モデルで「OpenAI o1」の性能を凌駕、中国企業はモデルを改良し効率化を探求
Alibabaは最新の推論モデル「QwQ-32B」を公開した。
このモデルは32B(320億)のパラメータを持つ小型モデルであるが、その性能はOpenAIの「o1-mini」を凌駕し、「DeepSeek R-1」に匹敵する。DeepSeek R-1のパラメータの数は671B(6710億)で、20倍小さなモデルで同等の性能を達成した。
中国企業はモデルを改良して、小型モデルで高性能な性能を達成する、効率性を探求する道を歩んでいる。(下の写真、Alibabaのシリコンバレーオフィス)

QwQ-32Bの概要
QwQ-32Bは32Bのパラメータで構成される小型の推論モデルで、問題解決の機能が大きく向上した。
QwQは「Qwen-with-Questions」の略称で、Alibabaの言語モデル「Qwen」をベースに、強化学習の手法で推論機能が強化された。QwQ-32Bはオープンソースとして公開されており、これをダウンロードしてローカルで運用できる。
また、Alibabaのチャットサイト「Qwen Chat」でこのモデルを利用することができる。
Qwenの製品体系
QwenはAlibabaの大規模言語モデルのシリーズ名で、このアーキテクチャーをベースに様々なモデルが開発されている。
Qwen Chatのサイトで、Alibabaが提供する複数のモデルを利用することができる(下の写真)。
Qwenの主力モデルは:
- QwQ-32B:今回発表されたQwenをベースとする推論モデル。DeepSeek R-1やOpenAI o1-miniの対抗製品
- Qwen2.5-Plus:Qwenシリーズのベースモデルで高度な言語機能を持つ
- Qwen2.5-Max:Qwenシリーズのフラッグシップモデルでトップレベルの性能を持つ。Mixture of Experts(MoE)というアーキテクチャを採用。DeepSeek V3やAnthropic Claude 3.5 Sonnetなどフロンティアモデルの対抗製品
QwQ-32Bの開発手法
QwQ-32Bは大規模言語モデル「Qwen2.5-32B」をベースとし、これを強化学習の手法で機能をエンハンスしたモデルとなる。
Qwen2.5-32Bは汎用の言語モデルで、この基盤に推論機能を付加したモデルがQwQ-32Bとなる。強化学習は二つのステップで構成される:
- ステップ1:Pure Reinforcement Learning 純粋な強化学習の手法でモデルを教育。数学やコーディングの問題が教育データとして使われた
- ステップ2:General Reward Models 汎用的な推論機能を学習した。人間のフィードバック「Reinforcement Learning with Human Feedback (RLHF)」などの手法が使われた
これにより、QwQ-32Bは人間の指示を正しく理解し、人間の価値観に沿った出力をする機能を獲得した。また、モデルが自律的に稼働するAIエージェントの機能を得た。
ベンチマーク
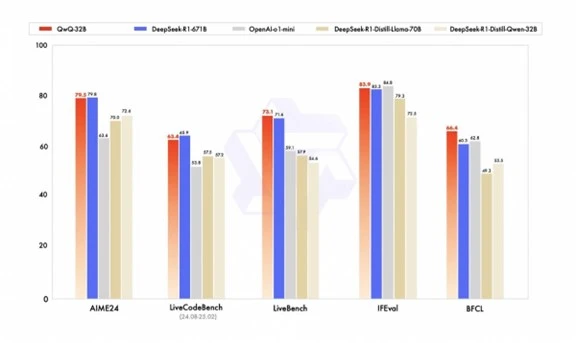
AlibabaはQwQ-32Bのベンチマークテスト結果を公表し、モデルは数学やコーディングやツールを使う機能で高い性能を示した。
数学の問題を論理的に解く機能を測定する試験「AIME24」でQwQ-32BはDeepSeek R-1(671B)に対して、それぞれ、79.5と79.8と同等レベルの性能をマークした(下のグラフ左端)。
QwQ-32BのサイズはDeepSeek R-1の1/20で、小型モデルが大規模モデルの性能レンジに到達した。
知識の移転
興味深いのはAIME24で「DeepSeek-R1-Distilled-Qwen-32B」の性能(72.6)がDeepSeek R-1の性能(79.8)の90%をマークした点である。
DeepSeek-R1-Distilled-Qwen-32Bは大規模言語モデル「Qwen2.5-32B」をベースとし、DeepSeek R-1の知識を転移(Knowledge Distillation)する手法で開発された。
Alibabaが推論機能を独自に開発するのではなく、競合機種DeepSeek R-1から知識を抜き取った形となる。

中国と米国の開発手法
Knowledge DistillationはAIモデルを開発する際に幅広く使われている技法であるが、国により法的な解釈が異なる。
米国においては、自社内で大型モデル(OpenAI o1)の知識を小型モデル(OpenAI o1-mini) に移転するために使われる。一方、中国市場では、企業を跨って大型モデル(DeepSeek R-1)の知識を小型モデル(Qwen2.5-32B) に移転するために使われている。
米国企業はAIモデルを利用する条件として、Knowledge Distillationを禁止しているが、中国市場ではこの手法に関する制約はなく、米中間で法的な解釈が分かれている。
実際に使ってみると
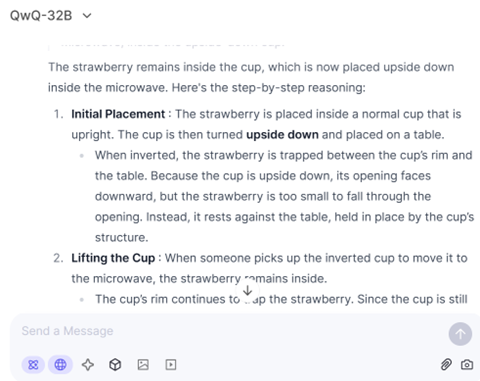
QwQ-32BはAlibabaのチャットサイト「Qwen Chat」でホスティングされており、実際にモデルを使うことができる(下の写真)。
QwQ-32B使ってみると、モデルは高度な推論機能を備えており、数学や物理などの問題に正確に回答する。一方で、QwQ-32Bは一般的な事項の質問に対しては、学習した知識が限られているのか、回答の精度が高くないように感じる。
正確な情報が求められる際には、モデルの出力を検証する必要がある。QwQ-32Bを含めQwenシリーズは、モデルが回答を生成するプロセス「Chain-of-Thoughts」を出力する点に特徴がある。
モデルがプロンプトを解釈し、利用者の意図を把握して、それに最適な解答を生成するプロセスを見ることができ、アルゴリズムの可視化に役立つ。
コストパフォーマンスの戦い
QwQ-32Bは高機能で低コストで極めてコストパフォーマンスの高い製品となっている。
DeepSeekショックが続く中、Alibabaは更に低コストのモデルを開発し、再び市場を驚かせた。AlibabaやDeepSeekなど中国企業は、既存のAIモデルを改良するスキルは極めて高く、米国企業がフロンティアモデルを投入し、これを中国企業が追随する構造が定着した。
チャイナショックはアメリカに波及し、米国企業は先端モデルを開発するだけでなく、これを低価格で提供することを迫られている。


