[No.121]ニューヨーク・タイムズはOpenAIを著作権侵害で訴訟するのか緊迫感が高まる、ChatGPTは学習した記事を出力し報道事業が脅かされる
ニューヨーク・タイムズはOpenAIを著作権侵害で提訴するのか、緊迫した状況となっている。
OpenAIは、ChatGPTなど生成AIの教育で、ニューヨーク・タイムズの記事を許諾を得ないで使っている。このため、両社でライセンスに関する協議が行われたが合意に至らず、ニューヨーク・タイムズは訴訟に踏み切る公算が大となった。
もしOpenAIが敗訴すると、生成AIの開発をやり直すこととなり、事業戦略に甚大な影響を及ぼす。

ニューヨーク・タイムズの主張
ニューヨーク・タイムズはOpenAIを著作権侵害で訴訟する構えを見せている。
米国のメディアが報道した。OpenAIはChatGPTなどの教育で、ウェブサイトから取集した大量のデータを使っている。この中には、ニューヨーク・タイムズの記事が含まれており、教育されたモデルはこの内容を覚えている。
利用者のプロンプトに対し、ChatGPTは記事の内容を出力し、著作権物が複製されることになる。このため、OpenAIが事実上のニュース会社となり、ニューヨーク・タイムズの競合企業になると主唱する。
GPT-4 (ChatGPT Plus) で試してみると
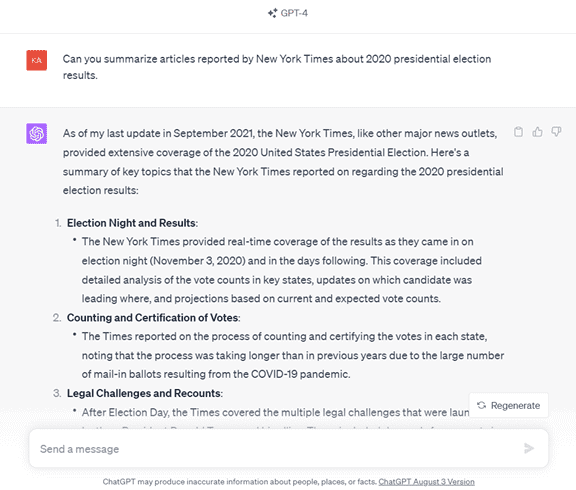
実際に、生成AIがニューヨーク・タイムズの記事を出力するのか、GPT-4で試してみた。
GPT-4はニューヨーク・タイムズの記事を出力することが確認できた。「2020年の米国大統領選挙の結果に関するニューヨーク・タイムズの記事」を要約するよう指示すると、GPT-4は「2020年の大統領選挙結果に関しニューヨーク・タイムズが報道した記事」として、包括的なレポートを生成した(下の写真)。
レポートは「選挙当日の結果」に始まり、「トランプ大統領の異議申し立て」、「連邦議会での選挙結果承認」、「連邦議会への乱入」まで、10項目にわたり記事の要約が出力された。ここにはニューヨーク・タイムズで学習したデータが含まれており、オリジナル記事の一部や、記事に基づく論評などが出力された。
OpenAIが利用しているデータ
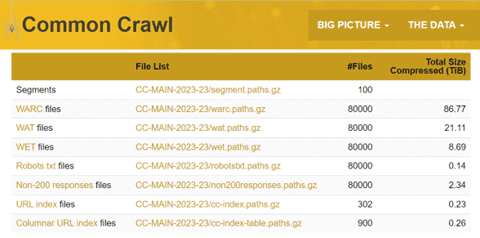
OpenAIはChatGPTなどのアルゴリズム教育で大量のデータを使っているが、その中心は「Common Crawl」である。
Common Crawlとは非営利団体が開発したデータセットで、ここにウェブサイトから収集したデータが格納されている。Common Crawlが収容しているデータ量はペタバイトを超え、クローラーは二か月ごとにデータを収集し、最新情報にアップデートする(下の写真、データセットの構成、最新版2023年5月/6月のアーカイブ)。
記事を学習したメカニズム
このデータセットはオープンソースとして一般に公開されており、だれでも無償で利用することができる。
OpenAIもこのデータセットを使い、ChatGPTなどを教育した。このデータセットにはニューヨーク・タイムズの記事を含め、世界の主要サイトの情報が格納されている。
このため、ChatGPTなどはニュース記事などの著作物で教育され、アルゴリズムは学習した内容を出力する構造となる。
ライセンスに関する協議
OpenAIとニューヨーク・タイムズは、この問題に関し協議を続けてきた。
ニューヨーク・タイムズは、記事を教育データとして利用することに関し、OpenAIにライセンス料の支払いを求めてきた。しかし、両社は合意点を見つけることができず、ニューヨーク・タイムズは記事の著作権を保護するため、訴訟に踏み切るといわれている。
OpenAIの主張
一方OpenAIは、著作物の一部だけを使っており、これは「フェアユース(Fair Use)」であり、著作権侵害には当たらないと主張する。
ChatGPTのアルゴリズムは、著作物を学習し、学んだ内容を出力するが、これは記事全体ではなくその一部で、フェアユースであると主張する。
生成AIの教育と著作権に関する明確な解釈は無く、もしニューヨーク・タイムズが提訴すると、裁判所はどう判断するのか、市場の関心が集まっている。
もしOpenAIが敗訴すると
ニューヨーク・タイムズが提訴し、OpenAIが敗訴すると、その影響は多岐にわたる。
米国著作権法によると、著作権の侵害が認められると、利用者に著作物を破棄することを求める。OpenAIのケースでは、Common Crawlを使って生成したデータベースから、ニューヨーク・タイムズの記事を削除することが求めれれる。更に、生成AIのケースでは、アルゴリズムから学習した内容を消去することも要求される。
つまり、ニューヨーク・タイムズの記事を含んでいないクリーンなデータセットを生成し、これを使ってChatGPTを再度教育することを意味する。ChatGPTを教育するためには数百億ドル単位のコストがかかり、企業経営に大きな重しとなる。
生成AIと著作権の関係
OpenAIは著作権侵害で複数の訴訟を受けている。
米国の著名な作家Sarah Silvermanは、OpenAIが著書「The Bedwetter」を著者の許諾なく使っているとして提訴した。これに加え、ニューヨーク・タイムズが実際に訴訟に踏み切ると、そのインパクトは甚大である。
生成AIが「フェアユース」で保護されないと判定されると、OpenAIは開発戦略の見直しを迫られる。また、他のニュースメディアが訴訟を起こす可能性は大きく、OpenAIは窮地に立たされる。
OpenAIや他の企業がAI開発を合法的に進めるためには、生成AIと著作権の関係を明確にすることが喫緊の課題となる。

