[No.116]OpenAIは性能の壁に突き当たる、GPT-4の規模を拡大しても性能が伸びない、新たなアーキテクチャを開発中、GPT-4は小型モデルを組み合わせた複合型AIか
大規模言語モデル「GPT-4」は、サイズを拡大しても、それに応じて性能が伸びない、という問題に直面している。
ニューラルネットワークのパラメータの数を増やしても、モデルの性能が向上しない、ということを意味する。
OpenAIのCEOであるSam Altmanは、この問題を認め、「AIの規模拡大競争の時代は終わった」と述べている。
この発言は、OpenAIは大規模言語モデルの新しいアーキテクチャの開発を進めている、ことを示唆している。

大規模言語モデルの性能問題とは
これは「Diminishing Returns」と呼ばれ、言語モデルのサイズを大きくしても、その成果(リターン)が得られない事象で、性能が伸びない問題を指す。OpenAIは言語モデルとして「GPTシリーズ」を開発してきたが、GPT-3までは規模を拡大すると、それに伴って性能が向上した。
特に、GPT-3では、人間レベルの言語機能を習得し、社会に衝撃を与えた。しかし、最新モデルGPT-4ではこのトレンドが崩れ、もうこれ以上ニューラルネットワークの規模を拡大できない地点に到達した。
言語モデルの限界

大規模言語モデルが限界点に到達したとは、今のプロセッサでは処理できない規模になったことを意味する。
技術的な観点からは、GPT-4は「Transformers」というアーキテクチャで構成されたモデルで、規模を拡大するとは、パラメータの数を増やし、教育データの量を拡大することを意味する。
GPT-4を教育するためには巨大なシステムが必要で、Altmanはモデルの開発で1億ドルを要したと述べている。
更に、開発した巨大なモデルを実行するには、大量の計算機が必要になり、運用費用が巨額になる。つまり、巨大な言語モデルを開発し、それを運用するには、技術的にもビジネスの観点からも、現実的でないというポイントに到達した。
新たなアーキテクチャの研究
このため、Altmanは言語モデルの性能限界を突破するために、新たなアーキテクチャを探求する必要があると述べている。
しかし、そのアプローチについては何も語っておらず、研究者の間でその手法に関する議論が白熱している。
研究者の推論を纏めると ##未確認情報##
ネットではGPT-4のアーキテクチャについて様々な議論が交わされている。
OpenAIは、これらの推測に関し何もコメントしておらず、議論の過程の情報となる。
これらの議論を纏めると、GPT-4は単体のモデルではなく、16の小型モジュールを組み合わせた、複合型の言語モデルとなる。
アーキテクチャの観点からは、このモデルは「Mixture of Experts」と呼ばれ、16の専用モジュールから成り、プロンプトに対しモジュールの中の「エキスパート」が回答を生成するという構図となる。
具体的には、GPT-4のシステム構成は:
- モジュール構成:GPT-4は16のモジュールから構成される。モジュールのパラメータの数は1110億で、GPT-3程度の規模となる。GPT-4全体では、パラメータの数は1.8兆個となる。GPT-4はGPT-3を16ユニット結合したサイズとなる。
- エキスパート機能:この構成は「Mixture of Experts (MoE)」と呼ばれ、各モジュールが分野のエキスパートとなる。問われたことに関し、最適のモジュールが解答を生成する。例えば、科学に関する質問には、それ専門のモジュールが稼働し解答を生成する。
- 教育データ:GPT-4は13兆のトークン(Token、単語などの基本単位)で教育された。極めて大量のデータで教育された。教育データはテキストやプログラムのコードが使われ、また、ツイッターやRedditなどのソーシャルメディアのデータが使われた。更に、YouTubeのビデオと、書籍などの著作物が使われた。
- インファレンス(実行):開発された巨大なモデルを如何に効率的に運用するかが課題となる。モデルを実行するプロセスは「Inference」と呼ばれ、Mixture of Experts構成を取ることで、運用コストを低減できる。プロンプトに対し、GPT-4全体を稼働させる必要はなく、専用のモジュールを2つ稼働させる。これにより、GPT-4を実行するコストはGPT-3の3倍と予測される。
Mixture of Expertsとは
Mixture of Expertsは早くから開発されている技法で、Googleはこのアーキテクチャに基づくモデル「GLaM」をリリースした。
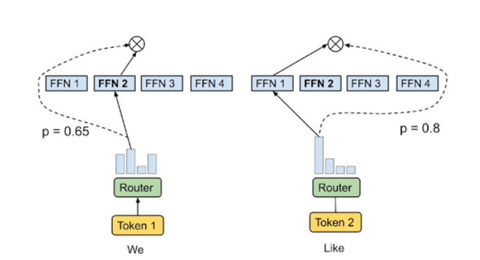
Googleは、このアーキテクチャを「Mixture-of-Experts with Expert Choice Routing」として発表している(下のグラフィックス)。
これは、Transformersの「Feed Forward Neural Networks(FFN)」というネットワークを「Mixture-of-Experts」(FFN 1からFFN 4の四つのモジュール)で置き換えることにより、モデルの処理を効率化できるとしている。
Googleはこのアーキテクチャに基づく言語モデル「Generalist Language Model (GLaM)」を開発し、言語モデルの規模を拡大できることを示した。具体的には、「GLaM」と「GPT-3」を比較すると、教育したモデルを実行するプロセス(Inference)で、計算量を大きく削減することができることを示した。
規模拡大からアイディアを競い合う時代に
大規模言語モデルは「Transformers」で構成されたニューラルネットワークで、その規模を拡大することで、性能が向上し、新たな機能を獲得してきた。
しかし、このトレンドは限界地点に達し、これ以上規模を拡大しても大きな性能の伸びは期待できない。
これからは、言語モデルのアーキテクチャを改良することで、スケーラビリティを探求することとなる。この分野では既に、GoogleやDeepMindが新技術を開発しており、OpenAIとの競合がより厳しくなる。

