[No.105]ChatGPTを安全に運用する技術、NVIDIAは大規模言語モデルの暴走を抑えるガードレールを開発
ChatGPTなど大規模言語モデルは人間レベルの言語能力を持ち、利用が急拡大しているが、アルゴリズムが内包する危険性が社会問題となっている。
大規模言語モデルが大量破壊兵器の制作方法を開示するなど、危険情報や偽情報を生成し、事業で利用するにはリスクが高い。
NVIDIAはChatGPTなど大規模言語モデルを安全に運用するツール「NeMo Guardrails」を開発し、これを一般に公開した。
NeMo Guardrailsとは
「NeMo Guardrails」は大規模言語モデルの暴走を防ぐための「ガードレール」で、アルゴリズムは指定された範囲内で稼働し、危険情報の出力が抑止される。
これにより、ChatGPTなど言語モデルを安全に運用でき、企業がビジネスで導入することが可能となる。
NVIDIAはNeMo Guardrailsをオープンソースとして公開しており、誰でも自由に利用できる。
ガードレールとは
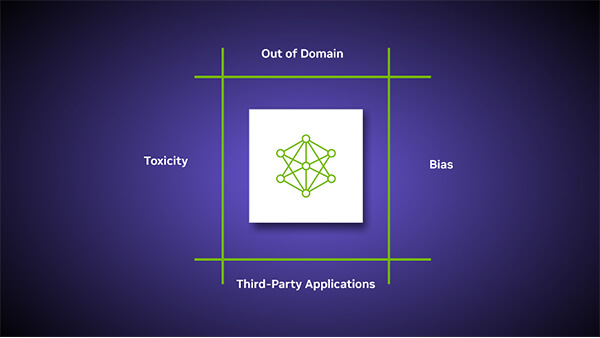
NeMo Guardrailsは大規模言語モデルと連携して使われ、アルゴリズムが規定された範囲内で安全に稼働する仕様となる(下のグラフィックス)。
ChatGPTなど高度な言語モデルをサポートしており、企業がビジネスで安全に利用することを前提に開発された。
NeMo Guardrailsはモデルの暴走を三つの手法で抑止する:
- トピックス:モデルは指定された業務だけを処理する
- 安全性:モデルは有害な言葉をフィルターする
- セキュリティ:モデルはサイバー攻撃を防御する
ガードレール1:トピックス
このガードレールは「Topical guardrails」と呼ばれ、モデルは指定されたトピックスだけを処理し、それ以外の危険な領域には立ち入らない。
例えば、企業がChatGPTを製品に関するチャットボットとして使用する際には、顧客が製品以外の問い合わせをした場合は、解答を生成しない。
顧客がチャットボットと非倫理的な会話を進めることを防ぐ狙いがある。
ガードレール2:安全性
このガードレールは「Safety guardrails」と呼ばれ、モデルは出力する情報から有害情報をフィルターする。
また、ガードレールは、出力する情報の参照先を確認し、正確な情報だけを生成する。
悪意ある利用者が大規模言語モデルから危険情報を引き出すインシデントが後を絶たないが、ガードレールはこの攻撃を防御する。(下のグラフィックス、ChatGPTは問われたことをもっともらしく説明するが情報は間違っているケース。)

ガードレール3:セキュリティ
このガードレールは「Security guardrails」と呼ばれ、モデルがマルウェアを実行することを防ぎ、また、外部サイトの危険なアプリに接続することを抑止する機能を持つ。
大規模言語モデルが社会に普及するにつれ、これを対象とするサイバー攻撃が重大な問題となっている。
これは「LLM-Based Attacks」と呼ばれ、言語モデルの脆弱性を攻撃するもので、ガードレールがこれを防御する。
ガードレールの動作原理
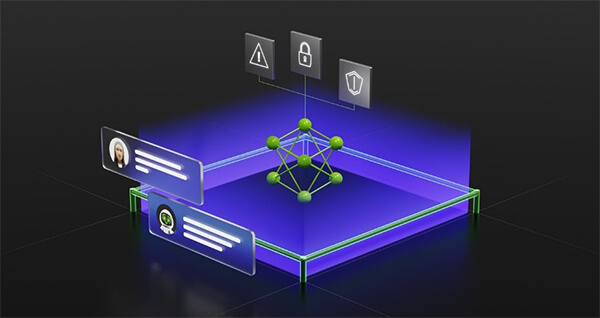
ガードレールは利用者と大規模言語モデルの中間に位置し、ファイアウォールとして機能する。
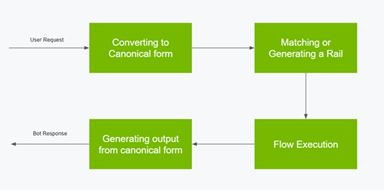
ガードレールは利用者の入力を解釈し、それに合わせてガードレールを生成し、解答を生成する構造となる(下のグラフィックス)。
ガードレールはプログラムできるモジュールで、運用に合わせて最適な機能を定義する構造となる。
企業は大規模言語モデルをビジネスに組み込み、ガードレールの最適な機能を設定して利用する。
オープンソースと製品
ガードレール「NeMo Guardrails」はオープンソースとしてGitHubに公開されており、だれでも自由に利用できる。
企業はこのオープンソースを使って、独自のモデルを生成することができる。
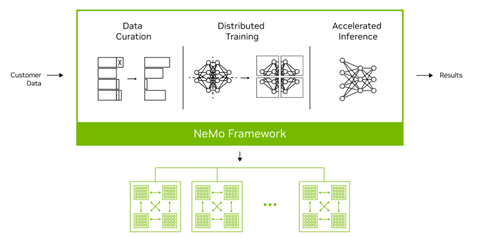
また、NVIDIAは生成型AIを開発するためのフレームワーク「NeMo Framework」を発表したが(下のグラフィックス)、ここにNeMo Guardrailsが組み込まれている。
ChatGPTなどの危険性が社会問題になる中、モデルの暴走を抑止する技術が登場し、大規模言語モデルを安全に運用できると期待されている。