[No.102]バイデン大統領はハイテク企業に出荷前にAIの安全性の確認を要求、OpenAIはGPT-4など大規模モデルの危険性を低減する対策を公開
高度な会話型AI「ChatGPT」の利用が急拡大する中で、社会に及ぼす危険性が顕著になってきた。
バイデン大統領は声明を発表し、AIを開発する企業に対し、モデルをリリースする前にその安全性を確認することを求めた。
事実、開発企業は検証が終わる前にAIをリリースし、我々消費者が危険性を指摘する形態になっている。
バイデン大統領はこの仕組みを見直し、AI企業が責任を持って最終検証することを求めた。

バイデン大統領の会見
バイデン大統領は、科学技術諮問委員会「President’s Council of Advisors on Science and Technology」の冒頭でAIに関する所信を表明し(上の写真)、AIは気候変動対策などで社会に多大な恩恵をもたらすが、同時に、AIは社会や国家安全保障や経済に危険をもたらす可能性があることを認識する必要があると述べた。
ハイテク企業は、AIを出荷する前に、その安全性を確認する責任があるとの考え方を示した。
AI権利章典
ホワイトハウスはこれに先立ち、AIからアメリカ国民の権利を守るための章典「Blueprint for an AI Bill of Rights」を公開した。
これは「AI権利章典」と呼ばれ、AIが社会に普及する中で、アルゴリズムのバイアスなどに起因し、国民が持つ権利が侵害されており、章典はこれを守るための基本指針を定義している。
バイデン大統領は、声明の中で、ハイテク企業はAI権利章典の趣旨に沿って、信頼できるAIを開発することを促した。
OpenAIの安全性対策
ChatGPTなど高度な言語モデルを開発しているOpenAIは、声明の翌日、AIの安全対策「AI Safety」に関する指針を公開した。
OpenAIは、この指針の中で、高機能なAIを開発しているが、アルゴリズムは安全で社会に恩恵をもたらすことを、会社をあげて取り組んでいると記している。

安全性を確認するプロセス
そのために、OpenAIは安全性を担保するための機構を、システムの各レベルに実装している。
OpenAIはその安全機構について具体的な事例をあげて説明している。
出荷前に安全性を検証するプロセスは次の通りとなる:
- 社内で徹底して危険性を洗い出す
- 社会の専門家に検証を依頼
- アルゴリズムの挙動を改良
- 広範に安全性とシステム運用を監視
アルゴリズムの挙動を改良
この中で「アルゴリズムの挙動を改良」するプロセスでは、人間が関与し、AIの挙動を改良する技法を導入している。
これは「Reinforcement Learning from Human Feedback (RLHF)」と呼ばれ、AIの回答を人間が評価し、それをモデルにフィードバックすることで、アルゴリズムが正しく回答できるようになる。
これは強化学習(Reinforcement Learning)というモジュールで構成され、AIが正しく回答するスキルを学習する。
GPT-4のケース
OpenAIは、世界最大規模の言語モデル「GPT-4」について、その安全性検証のプロセスを明らかにした。
OpenAIは、GPT-4の開発(アルゴリズムの教育)を終了してから6か月間にわたり、外部の組織と共同で、安全性の検証と、回答結果が社会の倫理に沿っているかの検証を進めてきた。
社内の規定に沿って安全性を判定したが、OpenAIは政府による安全性のガイドラインの設立が必要で、AI規制の導入を求めた。
実社会での検証が必須
OpenAIは、社内で厳格な安全性確認作業を進めるが、これだけでは十分でなく、実社会でAIを検証することが必須としている。
人々がAIをどのように活用するか、また、AIをどのように悪用するかについては、製品をリリースしないと理解が及ばない。
このため、AIをリリースして、社会と協調しながら、AIの安全性を強化していく手法が重要としている。
このために、OpenAIは高度なAIの機能を制限し、徐々にリリースする作戦を取っている。(下の写真、ChatGPTの初期画面で一般に無料で公開されている)
プライバシー保護について
OpenAIは個人のプライバシーを保護している仕組みについて説明した。
言語モデルは大量のデータで教育されるが、それらは下記のリソースが使われた:
- インターネットに公開されているデータ
- ライセンスを得たデータ
- 検証者が入力したデータ
これらのデータを使って大規模なアルゴリズムを教育するが、インターネットに公開されているデータには、個人情報が含まれており、AIは特定個人についての知識を得る。
これにより、個人情報がリークすることになる。
これを防ぐために、OpenAIは次の対策を講じている:
- 教育データから個人情報を取り除く
- アルゴリズムが個人情報を出力しないように改良する
- 利用者からの個人情報削除に関する要求にこたえる
出力データの正確性
大規模言語モデルは、間違った情報を回答するケースが少なくなく、出力データの精度が問題となっている。
これはOpenAIに特化した問題ではなく、言語モデルが抱える共通の課題である。
OpenAIはこれを最大の開発テーマと位置付け、アルゴリズムの改良を進めている。
ここでは、利用者のフィードバックが重要で、これをもとにアルゴリズムを改良する。
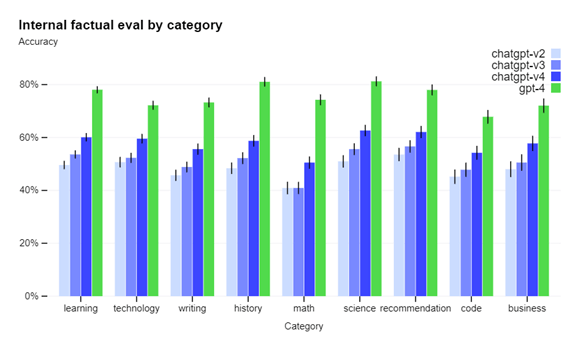
これにより、GPT-4の精度は各分野で大きく向上したとしている(下のグラフ、正解率を示したもので緑色がGPT-4)。
アメリカ社会が試験場
OpenAIは、もはや社内で100%安全なAIを開発することは不可能で、最終確認は一般利用者と共同で進める法式が現実的であると主張する。
消費者がテスターとなり、危険性をフィードバックする。これに対し、バイデン大統領は、ハイテク企業は安全確認を終えてから、信頼できるモデルを出荷すべきと要求する。
バイデン政権は国民の権利を守ることを第一義とするが、巨大テックは技術開発を優先し、アメリカ社会が大規模言語モデルの試験場となっている。

