[No.146]OpenAIは衝撃のAIビデオ「Sora」を公開!!テキストで写真撮影したように高品質な動画を生成、生成AIはマルチモダルの時代に突入
OpenAIは2月15日、テキストでビデオを生成するモデル「Sora」を公開した。
プロンプトで指示された内容でビデオを生成する技術であるが、生成された動画は写真撮影されたように鮮明で、AIとカメラの見分けがつかない。最も重要なポイントは、Soraは実社会で起こる物理現象を理解し、人間が指示しなくても物理法則に従ってビデオを描くことだ。
Soraは世界のシミュレータ「World Simulators」であり、この技法が人間レベルのインテリジェンス「Artificial General Intelligence(AGI)」の開発に繋がる。

Soraが描き出す世界
Soraはテキストで指示された内容に従って写真撮影したような高品質なビデオを生成する。
「雪の日の東京で。。。桜が満開。。。」と指示すると、Soraは東京・浅草の桜並木を彷彿させるビデオを生成する。OpenAIはテキストでイメージを生成するモデル「DALL-E」を運用しているが、Soraはこの技術を拡張し高解像度のビデオを生成する。
※上のビデオ、モデルは3D空間の意味を理解し、カメラのアングルを変えながら、対象物を追跡して撮影。
URL:https://cdn.openai.com/sora/videos/tokyo-in-the-snow.mp4
Soraの基本機能
SoraはAIモデルで、テキストから写真撮影したようなリアルなシーンを描き出す。
また、テキストから、アニメのような架空の世界を生成することもできる。Soraは生成AIのビデオモデルで、プロンプトに沿った高品質な映像を描き出す。
ビデオの長さは1分で、他社モデルの数秒を大きく上回る。
Soraを開発した理由
Soraは物理社会のモデルで教育され、物の動きを理解し、それをシミュレーションする機能を獲得した。
Soraを開発した 目的は、AIモデルが実社会における相互関係を学習することで、現実社会の問題を解決することが最終ゴールとなる。
このモデルが、人間レベルのインテリジェンス「Artificial General Intelligence」の開発に繋がる。
研究開発プロジェクト
Soraは研究開発プロジェクトで一般には公開されていない。
現在、モデルの安全性を検証する試験「Red-Teaming」が実施されている。生成AIがマルチモダルとなり、モデルが内包する危険性が格段に高まり、これらを洗い出す試験が実施されている。
また、ビジュアル・アーティストや映画製作者に限定して公開され、Soraをどのように利用すべきかなど、専門家の意見をヒアリングする。

※上のビデオ、プロンプトで女性のジャケットの色やサングラスの形や、背景の東京の通りの情景など詳細に指示することができる。
URL:https://cdn.openai.com/sora/videos/tokyo-walk.mp4
モデルは物理現象を理解
Soraは複雑なシーンを描き出すことができる。
複数のオブジェクトを対象に、指定された動きを忠実に再現し、対象物とその背景を高精度で描き出す。Soraはプロンプトで指示された内容を描き出すだけでなく、その対象物が物理社会でどう位置付けられるかを理解している。

※上のビデオ、「山道を走行する旧式のSUVをカメラが後ろから追いかけて撮影。。。」というプロンプトに沿ってビデオを生成。
モデルは、クルマは道路を走行し、舗装されていない道では小刻みに揺れるなど、物理法則を理解している。
URL:https://cdn.openai.com/sora/videos/suv-in-the-dust.mp4
プロンプトの理解
Soraは言語能力が極めて高く、言葉に関する深い理解を示す。
プロンプトで指示された内容を正確に描き出すだけでなく、対象物をリアルに描写し、生成されたビデオは説得力があり、躍動感を生み出す。
Soraはアーティストのように印象的な動画を生成する。

※上のビデオ、「ゴールデンリトリーバの子犬が、雪の中に頭を突っ込み、そこから雪を掻きわけて出てくる。。。」というプロンプトに対し、モデルは躍動感があり、印象的なビデオを生成する。URL: https://cdn.openai.com/sora/videos/snow-dogs.mp4
モデルの弱点
Soraは開発途上の生成AIマルチモダル技術で多くの弱点がある。
Soraは物理現象のシミュレータであるが、多くの制限事項がある。物理の法則を正しく理解しておらず、グラスが割れる事象や、食べ物を食べる行動などを正しく生成できない。
例えば、人間がクッキーをかじると、クッキーは欠けるが、モデルはそれを理解できない。これらがこれからの研究課題となる。
「Diffusion Transformers」という技術
Soraは「Diffusion Transformers」という技術をベースに構築された。
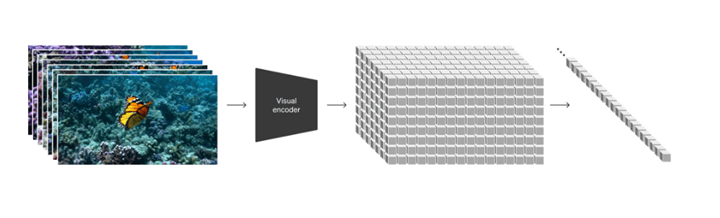
「Transformers」は大規模言語モデルの基礎技術で、テキストの基本単位「Token」をTransformersで処理し、次のTokenを予測する。Soraはこれを画像に適用し、イメージの基本単位「Patch」をTransformerで処理し、次のPatchを予測する(下の写真)。
更に、Soraは「Diffusion」という技法を使っており、これによりクリアなイメージを生成する。
イメージ生成技術の標準技法で、オリジナルのイメージにノイズを加え、これを除去する手法を学習し、最終的に高品質なイメージを生成する。
極めて危険なAI
Soraはプロンプトからカメラで撮影したようにハイパーリアルなビデオを生成する。
これを使えば、高品質な映画や動画を簡単に生成でき、エンターテインメントや広告ビジネスが激変する。また、Soraを悪用すると、現実と見分けのつかないフェイクビデオが生成され、社会が大混乱となる。
現行の生成AIと比較してその危険性は甚大で、これをどう活用するのか、安全対策など更なる研究が必要となる。

※上のビデオ、「イタリアのアマルフィ海岸の教会をドローンで撮影したシーン。。。」というプロンプトを入力することで、簡単に観光プロモーションビデオを生成できる。URL: https://cdn.openai.com/sora/videos/amalfi-coast.mp4

