[No.64]Metaは200言語を翻訳するAIを開発、これをオープンソースとして無償で提供、最終ゴールはユニバーサル機械翻訳AIの開発
MetaのAI研究所Meta AIは、単一モデルで200言語を翻訳できるAIを開発した。
AI翻訳の対象は世界の主要言語に限られていたが、このモデルによりその数が一気に拡大した。
MetaはこのAIをFacebookやInstagramに適用し、多言語の利用者を呼び込む。また、MetaはこのAIをオープンソースとして公開し、企業や大学はこれをベースに独自の翻訳システムを開発できる。
Metaは社外の研究機関と共同で、ユニバーサル機械翻訳AIの開発を進める。

プロジェクト概要
このプロジェクトは「No Language Left Behind (NLLB)」と呼ばれ、英語や中国語などメジャー言語以外の、マイナー言語(少数言語)のAI翻訳技術を開発することを目的とする。
マイナー言語は、利用者数が少なく、AIを教育するためのデータが限られており、「Low-Resource Languages」とも呼ばれる。これがマイナー言語を対象とするAI機械翻訳技術の開発が進まない原因となっている。
マイナー言語はアジアやアフリカに多く存在し、ビルマ語(Burmese、ミャンマーで使われている言葉、上の写真)がこれに含まれる。
AI機械翻訳の仕組み
このプロジェクトは、単一のAIモデルで多言語を翻訳する、ユニバーサル機械翻訳(Universal Language Translator)を開発することを目指している。
2020年から開発を始め、今月、200言語を翻訳するモデル「NLLB-200」の開発に成功した。NLLB-200がマイナー言語を高精度で翻訳できる理由は、AIで教育データを創り出す技術にある。
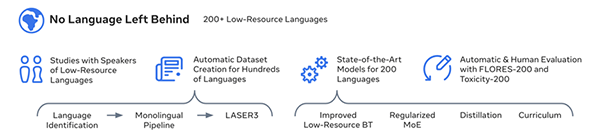
このシステムは、四つのコンポーネントから構成される(下のグラフィックス):
- マイナー言語を母国語とする開発者による研究
- 限られた言語情報からAI(LASER3)が大量の教育データを生成
- この教育データを元にAI機械翻訳モデル「NLLB-200」を開発
- NLLB-200の精度をベンチマークデータ(FLORES-200)を使って検証
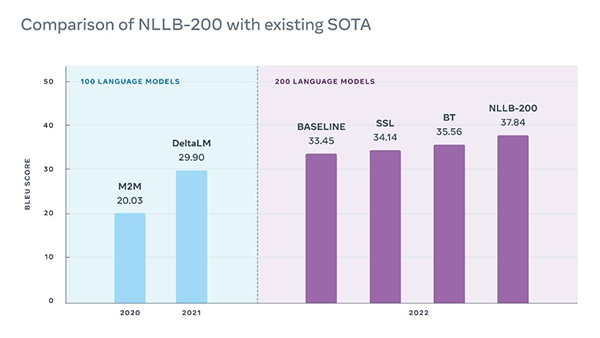
翻訳精度
この方式により、NLLB-200は従来モデルに比べ、翻訳精度が44%向上した(下のグラフ)。
MetaはNLLBモデルの開発を進めてきたが、当初は、100言語を対象にアルゴリズムを開発(水色の部分)。2022年は、対象言語の数を200に増やし、モデルを大幅に改良した(紫色の部分)。
その中で、最新モデルがNLLB-200(右端のグラフ)で、翻訳精度が大きく向上した。(機械翻訳の精度は「BLEU」という指標で示される。この数値が大きいほど精度が高い。)
機械翻訳の利用方法
Metaは、NLLB-200をFacebookやInstagramに適用し、マイナー言語を翻訳する計画である。
NLLB-200が、メジャー言語とマイナー言語の懸け橋となり、数多くの人がコンテンツを楽しむことができる。(下の写真、クメール語(Khmer language、カンボジアの国語)で書かれた物語を翻訳して読むことができる)。
また、メタバースでは世界各国の人々が、平等に交流する仮想社会の構築を目指しており、NLLB-200がコミュニケーションで重要な役割を担う。
更に、MetaはWikipediaと共同で、記事を多言語に翻訳するプロジェクトを進めている。

オープンソース
Metaは、ユニバーサル機械翻訳の開発を最終ゴールとし、社外の研究機関と共同でプロジェクトを進める。
これを目的に、NLLBで開発したAIモデルとデータセットをオープンソースとして公開しており、研究機関はこれを自由に利用して、独自の機械翻訳システムを開発できる。
また、Metaは、非営利団体を対象に20万ドルを上限に助成金を出し、開発を支援することを表明している。
オープンサイエンスの手法でAI機械翻訳技術を開発し、対象言語を増やす手法を取る。
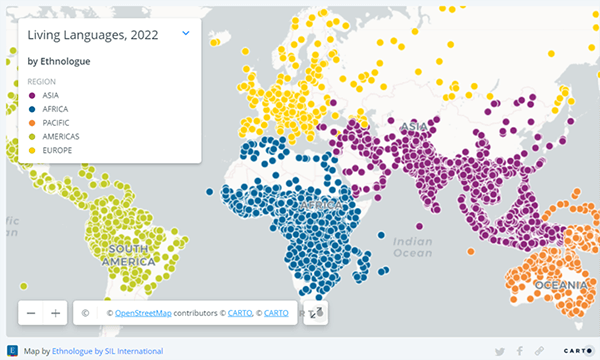
世界の言語
因みに、世界では7,151の言語が使われており、その多くが、アジアとアフリカに存在している(下のマップ)。これらの言語の40%は、継承者が少なく、絶滅の危機に瀕しているといわれている。
一方、23の言語が世界の半数以上の人により使われている。これらがメジャー言語で、英語、中国語・官話、インド・ヒンディー語がそのトップ3となる。
これらメジャー言語については、多くの企業からAI機械翻訳技術が提供されている。