[No.59] Googleはテキストをイメージに変換する技術「Imagen」を公開、AIがイラストレータとなり命令されたことを正確に理解し高解像度な画像を描き出す
Googleはテキストをイメージに変換するAI技術「Imagen」を公開した。
AIは言葉の指示に従ってイメージを生成するが、その機能が大きく進化した。
Imagenは、難しい指示を正しく理解し、それを高解像度のイメージに変換する。
「柴犬がカーボーイハットをかぶり庭でギターを弾く」と指示すると、Imagenはキュートな画像を高解像度で生成する。(下の写真、左側は写真のイメージで、右側は水彩画のスタイル)。
一方、Imagenは危険なイメージを高精度で生成するため、Googleは研究内容を非公開としている。

Imagenの概要
Googleは2022年5月、テキストをイメージに変換するAI「Imagen」を公開した。
Imagenは、OpenAIの「DALL·E 2」に対抗する技術で、その機能を上回るとアピールしている。
両者とも、言葉の指示に従ってイメージを生成するAIであるが、Imagenの特徴は、言葉の内容を正確に理解し、高解像度のイメージを生成できる点にある。
利用者の観点からは、Imagenは複雑な指示を正しく理解し、見栄えのするイメージを描くAIイラストレーターとなる。
素材の特性を理解
Imagenは、指示された言葉に沿って、リアルなイメージを生成する。
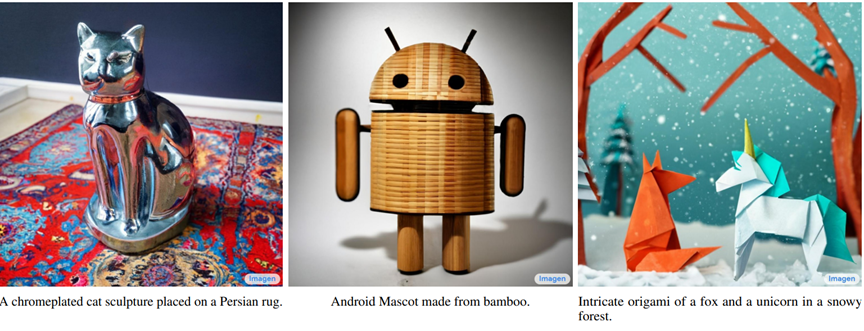
「ペルシャじゅうたんに置かれたクロムメッキの猫」と指示すると、金属面に写るじゅうたんを描きこみ、情景を写真撮影したように創作する(下の写真左側)。
「雪が降る森の中にいるキツネとユニコーンを折り紙で」と指示すると、紙の材質が現れたメルヘンの世界を生成する(右側)。
複雑な命令を理解
Imagenは、複雑な指示を正しく理解して、それを正確に描き出す。
「カーボーイハットをかぶり、黒色のレザージャケットを着たラクーンが、裏庭の窓の前にいる。
雨粒が窓を濡らす」と指示すると、全ての命令を漏らさず実行し、その情景を写真撮影したかのように、リアルに描き出す(下の写真中央)。

現実社会と仮想社会を合成
Imagenは、現実社会に仮想社会のシーンを投射し、不思議な空間を造り出す。
「モネの作品を展示しているギャラリーが浸水。この中をパドルボードに乗ったロボットが移動する」と指示すると、Imagenはメタバースのような現実と仮想が複合した社会を描き出す(下の写真右側)。
また、「トロントの街並みで花火を背景にGoogle Brainのロゴ」と指示すると、トロントの夜景にロゴが浮かび上がる(左側)。

ベンチマーク
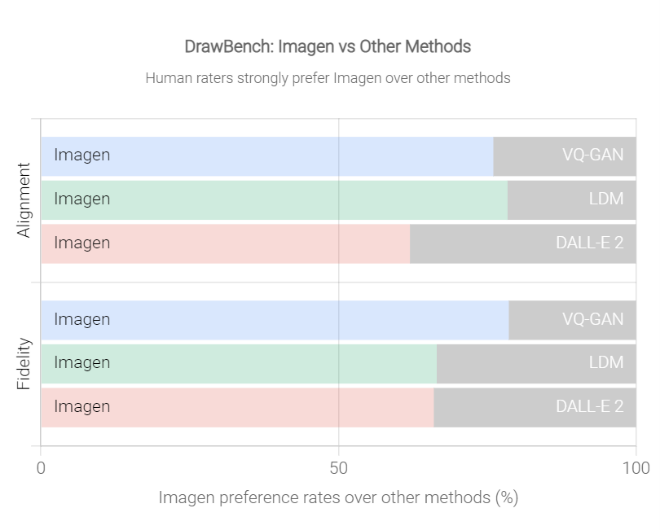
GoogleはAIが生成したイメージの出来栄えを評価するベンチマークテスト「DrawBench」を開発した。
いま、言葉で作画するAIの開発がブームになっているが、その機能を客観的に評価する目的で開発された。
ImagenやDALL·E 2などで生成されたイメージを、人間が判定してその機能を評価する。
ベンチマークは、言葉の指示をどれだけ正確に理解したかを判定する「Alignment」と、生成されたイメージがどれだけ正確かを評価する「Fidelity」で構成される。
Imagenが二つのカテゴリーでDALL·E 2など他社の技術を大きく上回った(下のグラフ)。
Imagenの応用分野
現在、イメージを生成するには、Adobe Photoshopなどのツールを使い、写真を編集するなどの手法が取られる。
これに対し、Imagenは人間の言葉を理解し、それを忠実に実行し、リアルなイメージを生成する。
誰でも簡単に、感覚的にグラフィックスを生成でき、アートやデザインの位置づけが大きく変わると予想される。
また、メタバースでは、Imagenは現実空間と仮想空間が融合した社会を生成するための重要な技術となる。(下の写真、Imagenは言葉の指示に従ってリアリスティックなオブジェクトを描き出す。)

Imagenの制限事項
一方、Googleは、ImagenはAI研究を目的として開発したもので、生成されるイメージは倫理的に許容できない内容を含んでいると警告している。
このため、GoogleはImagenを非公開とし、ソースコードなどは公開していない。
Imagenはウェブサイトのデータで教育され、不適切なコンテンツを含んでいる。このため、生成されるイメージは、人種問題や差別用語など社会的に許容できない内容を生成する。
更に、Imagenは、不適切なコンテンツを含むデータセット「LAION-400M」で教育されており、生成されるイメージはポルノグラフィや人種差別などNSFW(Not safe for work、不適切コンテンツ)を含んでいる。これらをImagenの制限事項として明らかにし、使用にあたり注意を呼び掛けている。
システム構成
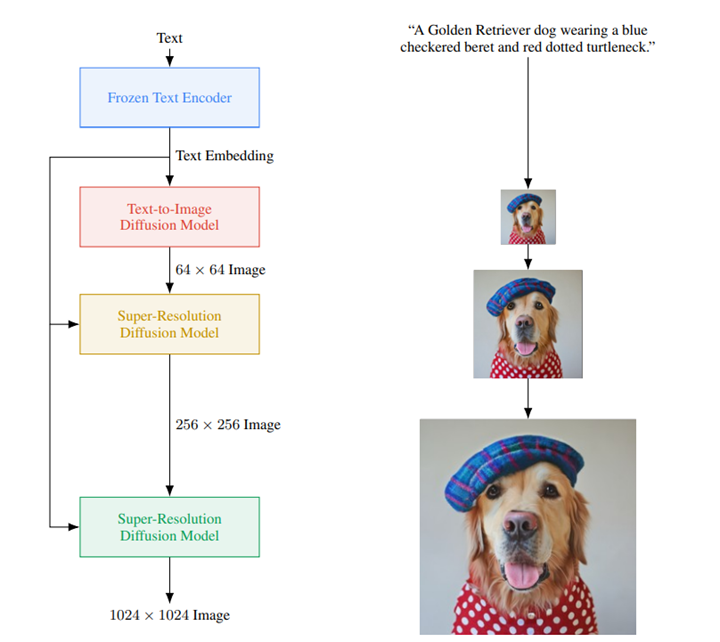
Imagenは二つのコンポーネントで構築され、それぞれ、「Text Encoder」と「Diffusion Model」となる(下のグラフィックス左側)。
Text Encoderは、入力された言葉の意味を理解する機能で、指示の内容を把握する。
ここではTransformerをベースに開発された「T5」という大規模言語モデルを使っている(最上段)。Diffusion Modelは、イメージを生成するモデルで、二種類のモデルから成る。
「Text-to-Image Diffusion Model」は、指示された言葉に沿ってイメージを生成する(上から二段目)。
「Super-Resolution Diffusion Model」は、生成されたイメージを高解像度のイメージにアップグレードする(上から三段目と四段目)。
システムの特徴
Imagenが複雑な指示を理解できる理由は、T5という大規模言語モデルを使っていることによる。
T5は人間並みの言語能力を備えており、命令されたことを正確に把握する。
Imagenに「青色のチェックのベレー帽をかぶり、水玉模様の赤色のタートルネックを着た、ゴールデンリトリバー」と指示すると、複雑な指示を正確に理解し、そのイメージを生成する。
更に、生成されたイメージの解像度は、二段階に分けてエンハンスされ、写真のようなリアルな映像を描き出す(上のグラフィックス右側)。

