[No.55] Metaは大規模AI言語モデル「OPT-175B」を開発、これを無償で提供することを発表、オープンサイエンスの手法でAIの危険性を解明する
Metaは大規模なAI言語モデル「Open Pretrained Transformer (OPT-175B)」を開発し、これを無償で提供することを明らかにした。
世界の研究者は、最先端のAIを自由に使うことができ、これにより自然言語解析の研究が進むことが期待される。
AIモデルは、その規模が拡大すると、アルゴリズムが新たなスキルを習得することが知られている。
同時に、アルゴリズムが内包する危険性が増大し、社会に甚大な被害を及ぼすことが問題となっている。
Metaはオープンサイエンスの手法で研究を進め、AIの危険性を解明することを目指している。

OPT-175Bとは
Metaが開発したOPT-175Bとは大規模な言語モデルで、自然言語解析(Natural Language Processing)と呼ばれる言葉を理解する機能を持つ。
OPT-175BはTransformerベースの言語モデルで、MetaのAI研究所「Meta AI」で開発された。
OPTの規模はパラメータの数で示され、最大構成の175B(1750億個)から最小構成の125M(1億2500万個)まで、八つのモデルで構成される。
OPT-175Bの機能
OPT-175Bは、人間の指示に従って文章を作成し、数学の問題を解き、会話する機能を持つ。
OPT-175Bの特徴は、言語モデルの中でもパラメータの数が175Bと、世界最大規模のニューラルネットワークであること。
このため、アルゴリズムが人間のように高度な言語機能を発揮することができる。
OPT-175Bは人間の指示に従って文章を生成することができる(下の写真)。
OPT-175Bに、「人事評価面接をテーマとする詩を生成」するよう指示すると(下の写真太字の部分)、アルゴリズムはそれに沿って文章を生成する(細字の部分)。
「良い評価を得たが、上司は一層の改善が必要と述べた。自分でも分かっており、努力しているが、なかなか難し。」などと、人間の心情を綴る詩を生成。

ライセンス
MetaはOPTのコードと教育済みのモデルを無償で提供することを明らかにした。大学や政府や企業の研究者が対象となり、利用申請すると審査を経て、使用を許諾される手順となる(下の写真)。
また、教育済みの小型モデルは、既にGitHubに公開されており、自由に利用できる。
但し、利用目的は研究開発に限定され、OPTを使ってビジネスをする形態は認められていない。
AI開発の現状
GoogleやMicrosoftなど巨大テックは、大規模なAI言語モデルを競い合って開発しているが、これらは社内に閉じ、クローズドな方式で進められている。
研究成果は論文として公開されているが、ここにはコードや開発手法は記載されておらず、他の研究者が成果を検証することはできない。
つまり、現在のAI開発はクローズドソースの方式で進められ、巨大テックがその知的財産を独占している形態となっている。
AIを公開する理由
これに対しMetaは、OPT-175Bを無償で公開し、世界の研究者が自由に利用できる方針を選択した。
大学や政府や民間の研究コミュニティで、大規模AI言語モデルの研究をオープンな形式で進めることで、研究開発が加速するとみている。
特に、AIの危険性を解明する研究が進み、言語モデルの理解が深まり、責任あるAI開発が可能となると期待している。

GPT-3との対比
Metaが開発したOPT(Open Pretrained Transformer)は、OpenAIが開発したGPT(Generative Pre-trained Transformer)に対峙する構造となっている。
OPTという名称は、GPTをオープン化したもの、という意味を含んでいる。
また、OPT-175Bのパラメータの数は、あえて、GPT-3の175Bと同じ数字とした。
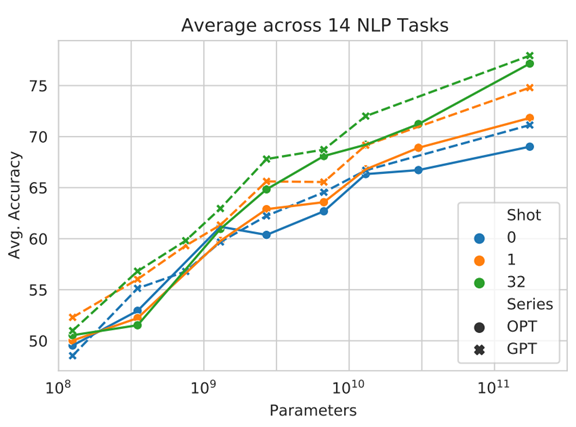
Transformerという同じアーキテクチャを採用し、その規模も同じとし、OPTは世界最先端のAI言語モデルを無償で公開することをアピールしている。(下の写真、OPTの性能(丸印)はGPTの性能(✕印)と互角であることを示している。)
オープンサイエンス
MetaはOPT-175B以前から、オープンサイエンスの手法でAI技術を改良するプログラムを展開してきた。
「Deepfake Detection Challenge」は、フェイクビデオを検知する技術をコンペティションの形式で競うもの。
「Hateful Memes Challenge」は、ヘイトスピーチなど有害なコンテンツを検知する技術の開発で、Metaは開発コミュニティと共同でこれを開発する。
OPT-175Bでは、コミュニティでアルゴリズムの研究を進め、AIの持つ危険性を理解する。
ヘイトスピーチ検知のコンペティション
Metaは「Hateful Memes Challenge」でヘイトスピーチのデータベースを公開し(下の写真)、研究者はこれを使ってヘイトスピーチ検知のアルゴリズムを開発した。
AIがヘイトスピーチを判別するのは難しく、これをオープンサイエンスの手法で開発した。
「Umbrella upside down (傘がひっくり返る)」という言葉は、状況に応じてヘイトスピーチとなる(下の写真最下段)。
これは「名声が内に向かってしぼむ」という意味もあり、使い方によって相手を傷つける表現となる。
ヘイトスピーチの判別は人間でも難しいが、アルゴリズム開発が進んでいる。

Facebookの教訓
AI言語モデルの開発は、巨大テックが企業内に閉じて進めており、外部の研究者は、開発内容をうかがい知ることはできない。
Metaは、AIコミュニティに大規模言語モデルを公開することで、信頼できるAIを開発できると目論んでいる。
この背後には、FacebookやInstagramのコンテンツ配信で、アルゴリズムが不透明で、偽情報が拡散し、社会が不安定になったという事実がある。
Metaはこれらの教訓を生かし、AI開発ではオープンな戦略を取り、信頼できるAIの開発を進めている。

