[No.202]Nvidia開発者会議レポート:推論コンピューティングの需要が爆発!!「AIファクトリ」でインテリジェンスを製造、100倍高性能なプロセッサが必要
Nvidiaは開発者会議「GTC 2025」を開催し、CEOのJensen Huangは基調講演で、「AIファクトリ」の構想を明らかにした。
AIモデルの主流は言語モデルから推論モデルに移り、推論モデルを稼働させるために大規模な計算環境が必要になる。推論モデルの実行に特化したデータセンタをAIファクトリと呼び、ここでの処理量が100倍拡張する。
言語モデルが性能の限界に達したとの議論があるが、推論コンピューティングで性能は伸び続け、データセンタの拡張が続くとの見通しを示した。

AIの基本単位
AIの基本単位はトークン「Token」で、言語モデルでは言葉の単位(単語など)を表現する用語となる。
トークンは言葉だけでなく、イメージを構成する最小単位となり、AIが写真や動画を生成する。科学技術の分野においては、トークンがイメージを物理情報に変換し、気象予報などで使われている(下の写真、ロスアンゼルスの大火災の解析)。
トークンがデータをインテリジェンスに変換し、新薬の開発や、自動運転車の開発や、ロボットの教育で使われる。
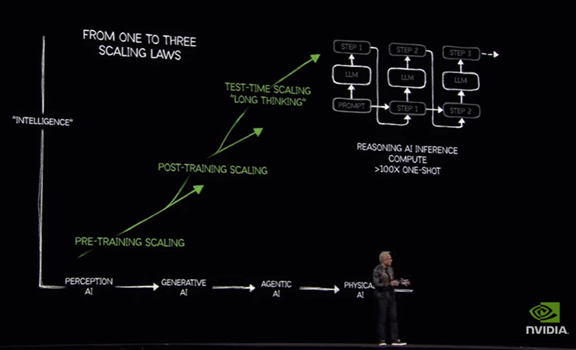
スケーリングの法則
言語モデルの開発では拡張性が限界に達し性能の伸びが鈍化したとの議論がある。
これはスケーリングの法則(Scaling Law)と呼ばれ、言語モデルの規模を拡大しても、それに従って性能が伸びないポイントに達した。これに対し、Huangはスケーリングの法則を三段階に分割し、性能は伸び続けていることを解説した。
プレ教育とポスト教育のあとに、インファレンス(モデル実行)のプロセスが続くが、ここで計算需要が急速に拡大している(下の写真、右上の部分)。
推論モデルの実行
AIモデルは言語モデルから推論モデルが主流となり、推論モデルの実行で性能が伸び続けている。
推論モデルの実行は「Long Thinking」という方式で処理が進み、問われたことにワンショットで回答を生成するのではなく、問題を考察し異なる思考法を試し、最適な解答を生成する。これは「Chain-of-Thoughts」など推論技法で、このプロセスを経ることでモデルはインテリジェンスを向上させる。
このプロセスでは大量のトークンを生成し、大規模なプロセッサが必要となる。
実際に、言語モデルに比べ推論モデルでは、生成するトークンの数が20倍となり、150倍高速なプロセッサが使われる(下の写真)。

推論モデルが注目される
DeepSeekショックで推論モデルへ注目が集まった。
DeepSeekは高度な推論モデル「DeepSeek R1」を低コストで開発し、AI開発競争の軸が米国から中国に広がった。OpenAIは推論モデル「o1」を公開し、最新モデル「o3」を開発している。
推論モデルは言語モデルを強化学習の手法でポスト教育したもので、論理的な思考機構を搭載し性能が格段に向上した。
推論モデルがこれからの基軸モデルとなり、モデルを実行するために大規模な計算機環境が必要となる。
AIファクトリのミッション
Nvidiaは推論モデルを実行するためのデータセンタを「AIファクトリ(AI Factory)」と命名し、ここでインテリジェンスを製造する。
AIファクトリは、クルマを生産する工場とは異なり、「トークン」を製造する施設となる。言語モデルでは文章やイメージなどのトークンを生成するが、推論モデルでは思考過程とその結果のトークンを生成する。
推論モデルではリアルタイムに大量のトークンが生成され、これは「Inference Problem」と呼ばれ、この需要を満たす大規模なデータセンタが必要となる。
上述の通り、インファレンスのプロセスでは、推論モデルは言語モデルに比べ100倍の処理量が要求される。(下の写真、AIファクトリのイメージ、推論モデルの実行でBlackwellはHopperに比べ40倍の性能をマーク)

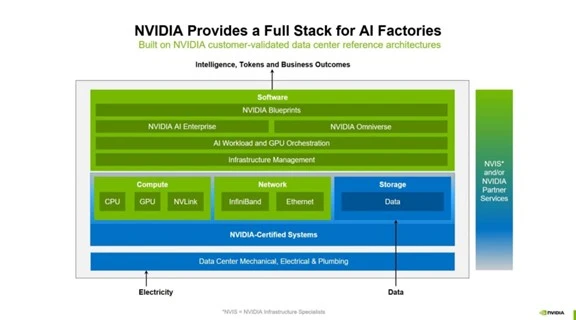
AIファクトリのシステム構成
AIファクトリはプロセッサだけでなくそれを制御するソフトウェアなどで構成される。
NvidiaはAIファクトリのテンプレートとして、必要なハードウェアやソフトウェアをパッケージしたモデルを公開した(下のグラフィックス)。
主な構成要素は:
- プロセッサ:Blackwellと Hopper
- ネットワーキング:NVLinkとQuantum InfiniBand
- ソフトウェア:TensorRT、NIM、Dynamoなど
ソフトウェア構成
NvidiaはAIモデルの実行を効率的に行うソフトウェアの開発に重点を置いている。
Nvidiaの特徴はツールやライブラリが充実しおり、開発したモデルをGPUで容易に稼働させることができる。
AIファクトリの主要ソフトウェアは:
- TensorRT:AIモデルをGPUで実行する環境、PyTorchやTensorFlowで開発されたAIモデルを稼働させる環境
- NIM (NVIDIA Inference Microservices):AI実行のマイクロサービス、AIモデルと実行環境を統合したパッケージ
- Dynamo:AIモデルの最適化エンジン、実行時にAIモデルを動的に最適化するツール
プロセッサのロードマップ
大規模AIファクトリを「Gigawatt AI Factory」と呼び、これに向けたプロセッサのロードマップを公開した。
今年から2028年までのレンジをカバーし、毎年新たなアーキテクチャのプロセッサが投入され、機能と性能が伸び続けることを明らかにした(下の写真)。
同時に、AIモデルを異なるアーキテクチャで稼働させるためのプラットフォーム「CUDA」についても、対象分野を拡大することを明らかにした。
プロセッサのアーキテクチャは:
- Feynman:2028年、その次のモデル
- Blackwell:2025年、208B トランジスタ、20 PFLOPSの性能
- Rubin:2026年、50 PFLOPSの性能、288GB HBM4メモリ
- Rubin Ultra: 2027年、Rubinの強化モデル

トークンの爆発
推論モデルのインファレンスでは言語モデルと比べ格段に多くのトークンが生成され、大規模な計算環境が必要になる。
AIファクトリはトークンの製造工場となる。トークンがAIの基本単位で、膨大なデータをインテリジェンスに変換する。推論モデルをベースにAIエージェントが開発され、更に、ヒューマノイド・ロボットなどフィジカルAIに繋がる。
基調講演の最後にはディズニーのロボット「Newton」が登場し、フィジカルAI技術の進化を示した(下の写真)。


