[No.195]推論モデル「DeepSeek-R1」はOpenAI「o1」の性能に到達、イノベーションかそれとも知識の”コピー”か、米国市場で議論が盛り上がる
中国のAI企業DeepSeek-AIは推論モデル「DeepSeek-R1」を公開した。DeepSeek-R1はOpenAIの推論モデル「o1」に匹敵する性能を示し、再び、米国市場に衝撃をもたらした。
DeepSeekは先進モデルを手本に、これを改良して低コストで高度な性能を達成し、米中間のAI開発競争がヒートアップしている。一方、開発技法を検証すると、DeepSeekはOpenAIのモデルから知識を吸い取る手法で「R1」を開発した可能性が濃厚となってきた。
この手法は「Distillation」と呼ばれ、AI開発で一般的に使われており、IPの盗用とは異なり、必ずしも違法な手法とは言えない。
しかし、米国のフロンティアモデルから知識が吸い取られると、安全保障の観点からリスクが高まる。
先端技術のIPを如何に守るのか、技術移転に関する議論が始まった。

DeepSeek-R1とは
DeepSeek-R1は高度な推論モデルで、問われたことを即座に回答するのではなく、熟慮して最適な解を生成するモデルとなる。
推論モデルは人間のように論理的な思考ができるAIで、与えられたテーマを分類整理して、筋道を立てて結論を導く。DeepSeekは先月、大規模言語モデル「DeepSeek-V3」を公開し、Metaのハイエンドモデル「Llama-3.1」の性能を追い越し、米国市場を震撼させた。
DeepSeek-R1はDeepSeek-V3の上に構築されたモデルで、今度はOpenAIの推論モデル「o1」に追い付いた。
ベンチマーク
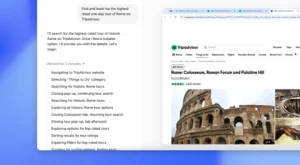
DeepSeek-R1は数学やコーディングの領域で高度な機能を持ち、ベンチマークテストで高い性能を示した(下のグラフ)。
数学の機能を試験するベンチマークテストでは、OpenAIの「o1」を追い越し、また、コーディングの試験では同等の性能を示した。
DeepSeekは米国企業の技術レベルに到達したことを示している。
オープンソース
DeepSeekは「DeepSeek-V3」と同様に、「DeepSeek-R1」をオープンソースとして公開しており、これをダウンロードして利用することができる。
AIオープンソースサイトHugging FaceにDeepSeek-R1が公開されており、ここからファイルをダウンロードする(下の写真)。
スタートアップ企業や研究者コミュニティがR1をダウンロードして独自のモデルを生成する動きが広がっている。
ホスティング
MicrosoftはDeepSeek-R1をホスティングすることを決定し、クラウド「Microsoft Azure」でこのモデルを使うことができる。
MicrosoftはAIモデルの開発環境「Azure AI Foundry」を運用しており、ここでDeepSeek-R1をベースとする独自のAIアプリケーションを開発する(下の写真)。
また、AmazonもAIクラウド「Bedrock」でDeepSeek-R1をホスティングすることを決定した。
DeepSeek-R1を使ってみると
DeepSeek-R1のホスティングサイトが広がり、実際にこのモデルを使うことができる。
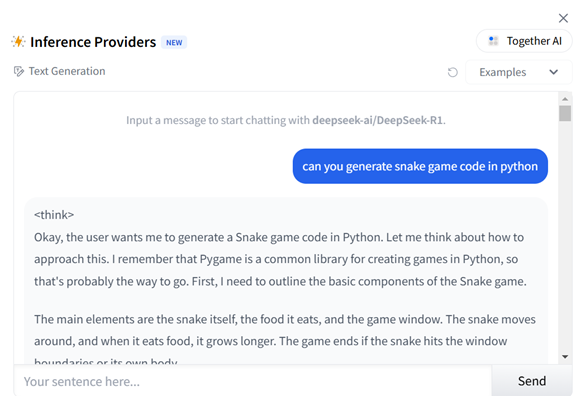
AI開発サイトTogether AIでDeepSeek-R1を使ってコーディングすることができる(下の写真)。R1に「Snake Game」をPythonでコーディングするよう指示するとコードを生成した。
様々な利用法を試してみたが、DeepSeek-R1の際立った特性として、推論の過程を出力することにあり、モデルがどうしてこの結論に達したのかを理解することができる。
開発プロセスと手順
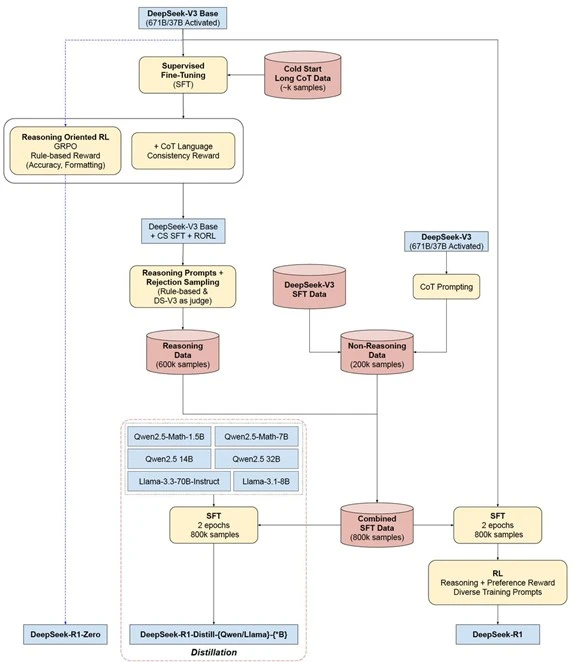
「DeepSeek-R1」(推論モデル)は「DeepSeek-V3」(言語モデル)をベースに、これを強化学習やファインチューニングの手法で推論機能を付加する形で開発された(下のフローチャート)。
実際には、DeepSeek-V3を強化学習だけでエンハンスし「DeepSeek-R1-Zero」(推論モデル・原型)を開発した(フローチャート左端)。同時に、DeepSeek-V3を強化学習とファインチューニングで改良し「DeepSeek-R1」(推論モデル・最終版)を開発した(フローチャート右端)。
また、DeepSeek-R1から知識を移転する方式「Distillation」でMeta Llama 3とAlibaba Qwen 2.5を言語モデルから推論モデルに拡張した(フローチャート下段中央部)。
開発手法に関する疑問
開発手法が明らかになる中で、DeepSeekはOpenAIのモデルから知識をDistillation(抜き出し)したとの解釈が広がっている。
トランプ政権下のAIと暗号通貨責任者のDavid Sacksは、DeepSeekがOpenAIのモデルから知識を抽出したことは明らかであると述べている。また、OpenAIは、DeepSeekがOpenAIのモデルから知識を抽出した明らかな証拠があり、調査を開始したとコメントしている。
OpenAIは利用規約でAIモデルを他のモデルを開発するために使うことを禁止している。
Distillationとは
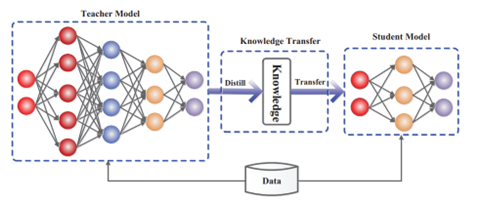
Distillationとは大規模モデルの知識を小型モデルにトランスファーする技法を指す(下のグラフィック)。
大規模モデルが有している知識を抽出し、これを小型モデルに移植する方式で、短時間でモデルのスキルを向上させることができる。大規模モデルが教師モデルとなり、小型モデルの生徒モデルに知識を移転する。
このケースでは、教師モデルがOpenAIのモデルで、生徒モデルがDeepSeek-R1となる。
グレーエリア
DistillationはAIモデル開発の常套手段でオープンソースのAIモデルから知識を吸収して様々なモデルが開発されている。
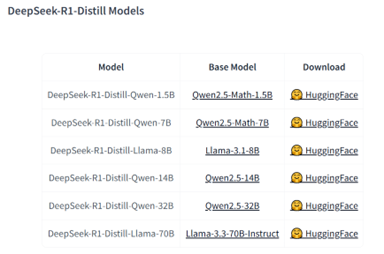
実際に、DeepSeekは、DeepSeek-R1を教師モデルとして、「DeepSeek-R1-Distill-Llama」や「DeepSeek-R1-Distill-Qwen」を開発している(下の写真)。
DeepSeek-R1の知識をMeta LlamaやAlibaba Qwenに移転したもので、元のモデルの機能を簡単にアップグレードできる。
フロンティアモデルの知識をどう保護する
一方、OpenAIは大規模な開発費を費やしフロンティアモデルを開発するが、この知識が吸い取られDeepSeekに移転されると、AI技術情報の転移となり、国家安全保障の重大なリスクとなる。
米国政府はNvidiaのGPU最新モデルを中国に輸出することを禁止しているが、AIモデルの知識のトランスファーについては規定されていない。トランプ政権下でフロンティアモデルの安全管理についての議論が進むことになる。
DeepSeekはAI開発競争から安全保障問題まで、様々な検討課題を米国にもたらした。