[No.185]大規模言語モデルの開発ペースが大幅にスローダウン!!OpenAIの次期モデルの性能が上がらない、開発戦略の見直しを迫られる
OpenAIは次期フラッグシップモデルを開発しているが、性能が上がらないという問題に直面した。
次期モデルのコードネームは「Orion」といわれ、GPT-4の後継機種となる。当初は今年末までにリリースされるといわれてきたが、これが来年にスリップした。
Orionは巨大なモデルであるが、規模を拡大してもそれに応じて性能が伸びない。生成AIモデルの性能が限界に達したという解釈もあり、この壁を乗り越えるためのイノベーションが求められる。

OpenAIの次期フラッグシップモデル
OpenAIは次期モデルについて何も発表していないが、CEOのSam Altmanはこのモデルを近いうちにリリースすると示唆している。
Xに「冬の星座が近いうちに上昇する」と書き込んだ(下の写真)。冬の星座は「Orion(オリオン座)」(上の写真)であり、そのリリースが近いことを暗示している。
次期モデルのコードネームは「Orion」といわれ、今年中に公開されるとみられてきた。

性能が上がらない
Altmanは次期モデルは博士号取得者に相当する知能を持ち、現行のGPT-4から機能が大きく飛躍すると述べてきた。
しかし、次期モデルの開発は9月に完了したが、目標の性能に到達することはできず、OpenAIはこのモデルの出荷を見合わせた。アメリカのメディアが報道した。
GPT-3とGPT-4の間には大きな性能差があるが、GPT-4から次期モデルの間では大きな性能の伸びを達成できなかった。
性能が伸びない原因
次期モデルの性能が上がらない原因はアルゴリズムを教育するデータといわれている。
モデルのプレ教育では、ソーシャルメディアや書籍やウェブページなどをインターネットからスクレイピングして使っている。しかし、公開されているデータの量や質には限りがあり、次期モデルの開発では高品質なデータを充分収集することができなかった。
特にプログラムのコーディング機能に関しては問題は深刻で、次期モデルの性能はGPT-4と大きな違いはない。
インターネット上のデータを使い尽くしたとも解釈される。
研究テーマ1:教育データ
OpenAIはこの問題を解決するためチームを創設し、性能向上のための技法を検討している。
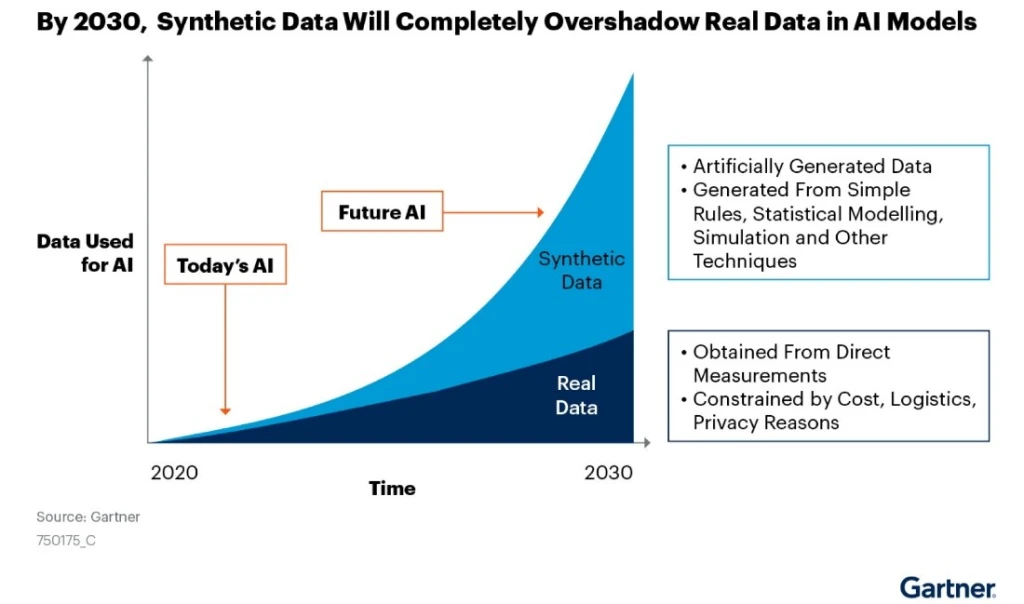
最大の原因が教育データの不足で、高品質なデータを取り揃えるための技法を模索している。その一つがデータを人工的に生成する手法で、合成データ(Synthetic Data)と呼ばれる。
AIモデルでデータを生成し、これを次期モデルの教育で利用する。これからのAIモデル開発では合成データが主流になるとの予測もある(下のグラフ)。
また、OpenAIは主要な出版社とライセンス契約を締結しており、これらの企業から高品質なデータの供給を受ける。
研究テーマ2:ポスト教育
OpenAIはプレ教育したモデルをファインチューニング(Fine-Tuning)することで性能を改良するアプローチを研究している。
これはポスト教育と呼ばれ、プレ教育されたモデルを高品質なデータで再教育することで性能を上げる。また、人間がインストラクターとなり、モデルに正しい回答を教える。
この手法は「Reinforcement learning from human feedback(RLHF)」と呼ばれ、現行モデルに適用されているが、このプロセスを強化する。
ベンチャーキャピタルの評価
OpenAIだけでなく他社モデルも含めて、大規模言語モデルの性能が限界に到達したとの解釈が広がっている。
大手ベンチャーキャピタルAndreessen HorowitzのBen Horowitzは大規模言語モデルがスケーリングの限界(point of diminishing returns)に到達したと述べている。
プロセッサGPUの性能は定常的に向上しているが、ここで開発されるモデルの性能が伸びないことは、原因はアルゴリズムにあるとの解釈を示している。
Googleのアプローチ
この問題に関し、言語モデル開発企業はAIモデルのボトルネックを考察し、これを改良する研究を進めている。
Googleはモデルがデータから学習するメカニズムを解析し、人間のように少ないデータで効率的に学習する手法を研究している。アルゴリズムを最適化する手法は「ファインチューニング(Fine-Tuning)」と呼ばれ、プレ教育したモデルを再教育して、特定のタスクを効率的に実行させるために実施される。
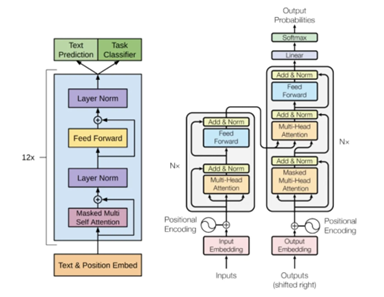
これに対し、Googleはプレ教育を効率的に行うため、モデルの構造自体を最適化するアプローチを取る。
これは「ハイパーパラメータ・チューニング(Hyperparameter Tuning)」といわれ、トランスフォーマの構造を改良する作業となる。(下の写真、トランスフォーマの基本構造)
スケーラビリティの壁を乗り越える
大規模言語モデルはスケーラビリティを示してきたが、2024年は規模を拡大しても性能が伸びないポイントに差し掛かっている。
この状況を打開するには、規模拡大というアプローチだけでなく、モデルの構造を最適化する手法や、ファインチューニングの新技術を模索するなど、新たな研究開発が求められる。
スケーラビリティの壁を乗り越えるため、2025年はAI開発でイノベーションが求められる年となる。

