[No.177]小規模言語モデル「Small Language Model(SLM)」の利用が急拡大!! 生成AIシステムの99%はSLMで構築できる、効率的なモデルへの期待が高まる
小規模言語モデル「Small Language Model (SLM)」の研究開発が進み、アメリカ市場で利用が拡大している。
この背景には、大規模モデル「Large Language Model (LLM)」の機能や性能への不信感があり、市場はLLMとSLMの二つのハブに分化している。プロセッサに例えると、LLMはスパコンに匹敵し巨大プロジェクトを実行する。
SLMはデータセンタのサーバやPCやスマホとなり、日常のタスクを実行するために使われる。
SLMの機能や性能は向上を続け、AI利用シーンンの99%をカバーするとの解釈が広がっている。

LLMとSLMの性能が接近
技術進化でSLMの性能がLLMに急接近している。LLMの開発が進むがそのペースは緩やかで、一方、SLMの性能は急ピッチで伸びており、両者のギャップが狭まりつつある。
LLMは規模を拡大することで、機能や性能を改良してきたが、そのスケーラビリティが限界に近づいている。LLMの開発では巨大な計算環境が必要で、モデルの教育は大量のデータを要する。
また、開発されたLLMは構造が複雑で、内包するリスクが大きく、これらのモデルを安全に運用するには高度なスキルを要す。
これに対し、SLMは構造がシンプルで、目的に特化したデータで最適化され、業務に特化した専用AIシステムとして使われる。
SLMの定義
モデルのサイズはパラメータの数で規定され、SLMは「小型言語モデル」で、少ない数のパラメータで構成される。
明確な定義は確定していないが、パラメータの数が10B(Billion)から20B以下のモデルをSLMと呼んでいる。企業はSLMの開発を進め、Metaは「Llama 3.1 8B」を投入した。
Google DeepMindは「Gemma 2 9B」をMicrosoftは「Phi-3-mini 3.8B」をリリースした。
これらは効率性を追求したモデルで、クラウドだけでなくローカルのサーバやPCで運用できることが特徴となる。
SLMのベンチマーク性能
SLMは技術開発が進み、LLMには及ばないが、両者の性能ギャップは急速に縮まっている。
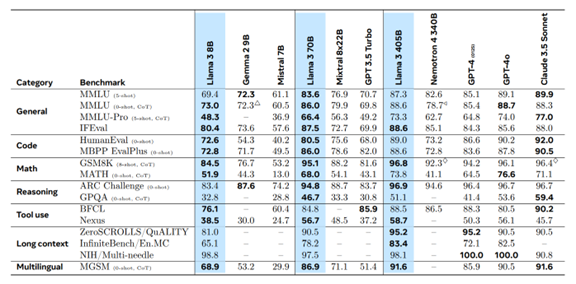
Metaのベンチマーク結果によると、「Llama 3.1 8B」の言語性能(MMLU、0-shot)はOpenAIの「GPT-4」に接近している(下のテーブル、二段目)。また、Google DeepMindの「Gemma 2 9B」の言語性能(MMLU、5-shot)もGPT-4に迫っている(下のテーブル、最上段)。
因みに、GPT-4はMixture of Experts(MOE)というアーキテクチャで、8つの専用モジュールから構成され、システム全体でパラメータの数は1,760B (220B x 8)となり、SLMに比べて約200倍の規模となる。
SLMが注目される理由:専用AIシステム
SLMは小型モデルで、特定のタスクに特化したAIシステムとして利用されるケースが多い。
一方、LLMは大規模モデルで、多種類のタスクを実行でき、汎用AIシステムとして展開される。
SLMは開発されたモデルを最適化「Fine-Tuning」して、特定のアプリケーションを実行するAIシステムとして利用される。
SLMが注目される理由:セキュリティとプライバシー
SLMはモデルのサイズがコンパクトでエッジコンピューティングを実現する。
モデルを企業内のサーバやPCで稼働させることで、機密情報が外部にリークするリスクが激減する。また、エッジデバイスで個人情報を処理するため、プライバシー保護を厳格に実行できる。
このため、SLMは強固なセキュリティが法令で義務付けられている業種で利用が広がっている。
例えば、金融機関や医療機関は、個人情報保護で法令に順守する必要があるが、SLMでこの要件を満たすことができる。

SLMが注目される理由:安全性
SLMはモデルの規模が小さいことに加え、高品質なデータで教育されているケースが多く、バイアスした情報や有害なコンテンツを出力するリスクが激減する。
LLMはインターネット上のデータでプレ教育され、これを再教育して、品質を向上させるアプローチを取る。SLMの教育では大量のデータは不要で、厳選された高品質のデータで教育するプロセスを取る。
これにより、LLMを悩ませるハルシネーションの問題を大きく低減できる。
SLMを開発する手法:Knowledge Distillation
SLMはLLMと同様に、トランスフォーマ「Transformers」をベースとするアーキテクチャであるが、そのレイヤーの数は少なくコンパクトなネットワークとなる。
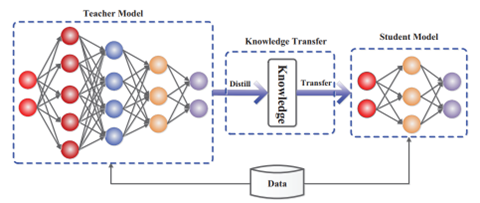
SLMは様々な手法で開発されるが、LLMの知識をSLMにトランスファーする「Knowledge Distillation」という技法が使われる(下の写真)。LLMが有している知識を抽出し、これをSLMに移植する方式で、短時間でモデルのスキルを向上させる。
実際に、Googleの言語モデル「BERT」から知識を抽出する手法で、小型言語モデル「DistilBERT」が開発された。
DistilBERTはBERTに比べてモデルのサイズは40%小さいが、言語能力の97%を有する。
SLMを開発する手法:Fine-Tuning
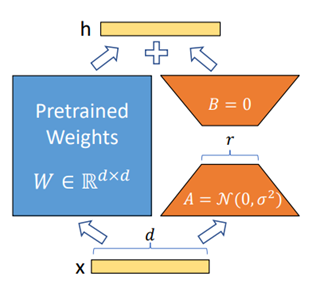
基礎教育されたSLMは、次のステップでFine-Tuning(最適化)される。
このプロセスでは、タスクに特化したデータでモデルのパラメータを最適化し、業務に特化したAIシステムを構築する(下の写真、Low-Rank Adaptationという手法の事例)。金融情報サービス会社BloombergはオープンソースのLLM「BLOOM」を金融データで教育した大規模モデル「BloombergGPT-50B」を開発した。
その後、Microsoftは小型モデルを業界に特化したデータで最適化した「AdaptLLM-7B」を公開した。AdaptLLM-7Bは金融業務専用のAIシステムで、ベンチマークでBloombergGPT-50Bを上回る性能をマークした。
1/7のサイズのモデルで大規模モデルの性能を上回った。
AIビジネスでの差別化
GPT-4oなどLLMでビジネスを構築する際に、他社とどう差別化するかについて、シリコンバレーで議論が広がっている。
LLMのAPIを利用し、このモデルの上にアプリケーション層を構築し、独自のAIシステムを構築する。このアプリケーション層は「Wrapper(被い)」と呼ばれ、ここが企業の差別化の鍵となる。
しかし、AIシステムの基盤は共通のLLMで、企業が他社に比べ大きな優位性を示すことができない。LLMでは他社に市場を奪われないための堀「Moat」を構築することが困難となる。

LLMとSLMの二極化
これに対し、SLMをベースに独自のモデルを創り上げることで、他社に対する防衛を強固にし、新たなビジネスを切り開けるとの期待が広がっている。
また、LLMは巨大テック数社がコントロールする世界であるのに対し、SLMで各社が独自のAIシステムを生み出すことで、技術革新が加速し、事業が拡大するとの解釈が示されている。
これからの生成AI市場は、クラウド経由でLLMのAPIを利用する形態と、各企業が独自のSLMを開発し運用するという、二つの陣営に分化することになる。

