[No.174]半導体カンファレンス「Hot Chips 2024」:OpenAIは生成AIの機能は伸び続けると主張、次世代大規模モデルを開発するためのGPUクラスタ技術を公開
今週、スタンフォード大学で半導体カンファレンス「Hot Chips 2024」が開催され、半導体設計に関する最新技術が開示された。
このカンファレンスは高性能プロセッサを議論する場であるが、今年はAI専用プロセッサに関するテーマが中心となった。OpenAIは基調講演で、大規模言語モデルのスケーラビリティ(拡張性)に関する研究を示し、モデルの機能は伸び続けると推定。
次世代モデルを開発するためには巨大な計算環境が必要で、そのコアシステムとなるGPUクラスタを解説した。

カンファレンスの概要
「Hot Chips」は半導体設計に関するカンファレンスで、業界の主要企業が参加し、高性能プロセッサ「High-Performance Processors」を中心に新技術が議論されてきた。
今年はその流れが変わり、AI処理専用プロセッサ「AI Processors」を中心に最新技術が公開された。AI処理の中でも大規模言語モデルを中心に、タスクを高速で実行するための様々なアーキテクチャが示された。
生成AIのコア技術であるトランスフォーマに特化した半導体回路設計などの研究が開示された。講演の模様はライブでストリーミングされた。
AIプロセッサの市場構造
大規模言語モデル向けのAIプロセッサはGPUが標準技術として使われ、Nvidiaの独走状態が続いている。
これに対して、主要各社はASIC(application specific integrated circuit、特定用途向けIC)を基盤とするAIプロセッサを開発し、GPUの代替技術となることを目指している。Googleは「TPU」を、Amazonは「Trainium」と「Inferentia」を、Microsoftは「Maia」を開発し、大規模言語モデルのアクセラレータと位置付けている。
スタートアップ企業は斬新なアーキテクチャでAIプロセッサを開発し、政府研究機関などで運用が始まった。
OpenAIの基調講演
基調講演でOpenAIは大規模言語モデルのスケーラビリティと大規模システム「GPUクラスタ」に関する最新技術を公開した。
OpenAIはAIプロセッサを利用する観点から、次世代大規模モデルを効率的に開発するための基盤としてGPUクラスタに関する技法を開示した。
AI開発ではNvidia GPUが使われるが、これを多数連結してクラスタを構成し、次世代モデルを開発・運用する技法を開示した。
Predictive Scaling:拡張性の予測
OpenAIはGPT-4など大規模モデルを開発しているが、言語モデルはこれからも機能や性能が伸び続けるとの研究成果を開示した。
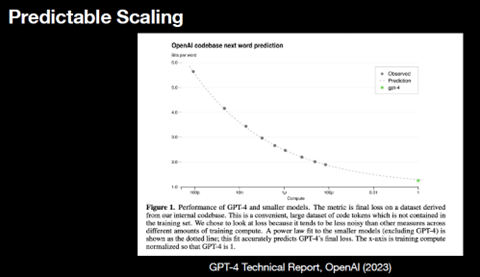
これは「Predictable Scaling」と呼ばれ、予測したペースで機能が拡張すると予測している。その根拠として「GPT-4」の開発事例を示し、モデルの規模を拡張すると(実行時間を長くすると)、機能が向上することを示した(下のグラフ)。
小型モデル(灰色の円、実測値)を多数検証し、モデルの規模と機能をプロットすると、その延長線上にGPT-4(緑色の円、予想値)が位置し、機能はこの曲線に沿って拡大している事実を示した。
AIモデルのスケーリング
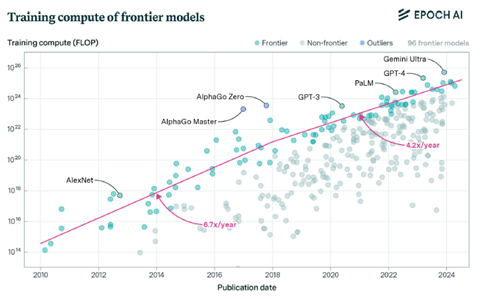
GPT-4だけでなく、他社の大規模言語モデルを検証すると、このスケーラビリティは言語モデル全般に適用できる。
主要モデルの規模(教育に要した計算量)とリリースされた時期をプロットすると、フロンティアモデルを教育するためのコンピュータ規模は毎年4-5倍となっている(下のグラフ)。
市場ではフロンティアモデルの性能は限界に達するとの見解もあるが、OpenAIは大規模言語モデルはこれからもこのペースで機能が伸びると予測している。
Mass Deployment:モデルを大規模に運用
OpenAIはこの仮定に基づき、フロンティアモデルの開発では計算環境の規模を継続的に拡大する必要があり、この需要に応えるためGPUクラスタを運用している。
OpenAIはGPT-4など大規模モデルの開発ではGPUサーバを大規模に結合したGPUクラスタを利用している。
実際には、GPT-5の開発ではMicrosoftのアリゾナ・データセンタの計算施設を使っており、GPUクラスタのサイズは巨大で、海洋生物に例えるとクジラの大きさになる(下の写真)。

GPUクラスタを運用する技術
GPUクラスタは巨大なシステムで、運用では様々な障害が発生し、安定的に稼働させるには高度なスキルが求められる。
GPUクラスタはマクロな観点から様々な弱点があり、システム全体の信頼性(RAS:Reliability, availability and serviceability)を高めるためのスキルが必要となる。
GPUクラスタで障害が発生しやすいポイントは:
- オプティカルネットワーク:GPUクラスタのモジュールは光ケーブルで結合されるが、このオプティカルネットワークの信頼性が低い
- 高速メモリ:高速メモリ「High Bandwidth Memory (HBM)」の信頼性が低い。HBMとは3D構造のメモリ(DRAM)で、GPUプロセッサと高速でデータ転送を行う。
- データに内在するエラー:「Silent Data Corruptions(SDC)」という問題。SDCとはデータに内在するエラーであるが、これが検知されないままでモデルの教育が進み、完成したモデルが誤作動するという問題。データに内在する問題は出現しないケースが多く、問題の切り分けが難しく、開発者を悩ませる。
GPUクラスタの障害からの復旧
GPUクラスタでこのような問題が発生するが、システムを障害から復旧させるためのテクニックが必要となる。
言語モデル開発への影響範囲を最小限に抑えることが必須要件で、そのためには復旧のシークエンスが重要となる:
- ソフトウェア:ソフトウェアで例外処理が発生したケースはソフトウェアを再起動する
- プロセス:上記の処理で問題が解決しない場合は、プロセス全体を再起動する
- GPU:ハードウェアレベルの障害ではGPUプロセッサを再起動する
- ノード:GPUクラスタを構成するノードを再起動する
- ハードウェア交換:GPUプロセッサなどハードウェアを交換する。影響範囲は多岐にわたりこれは最後の手段。
電力供給管理の技法
GPT-5など大規模モデルの教育では、GPUクラスタは大量の電力を消費し、これを効率的に制御する必要がある。
データセンタへの電力供給量は限られており、これを各プロセスで効率的に使用する。大規模モデルの教育では、GPUクラスタの各モジュールを同期して稼働させるため、電力消費量が急上昇したり急降下することになる。
このため、電力消費量を遠隔で監視する仕組み「Power Telemetry」などが必要になる。
これに応じて、データセンタ内の電力配分を動的に変更する技術「Dynamic Power Sloshing」が必要となる。
生成AIモデルの成長は続く
市場では、トランスフォーマの規模を拡張しても、モデルの機能や性能がこれに応じて伸びなくなる、との見解が広がっている。
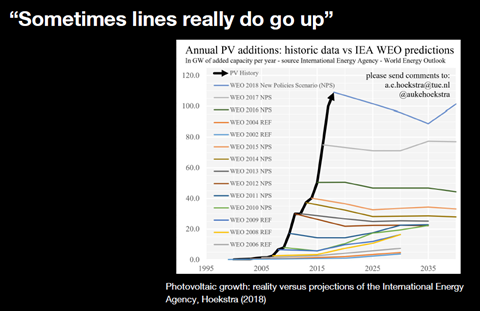
生成AIの成長のスピードが鈍化し、モデルは限界に達するという解釈である。これに対しOpenAIは、太陽光パネルの事例をあげ、モデルの機能や性能は恒常的に拡大するとの予測を示した。
太陽光パネルの生産量は、その成長率がフラットになると予測され続けてきたが、実際には成長のスピードは加速している(下のグラフ、カラーのグラフ;予測値、黒色のグラフ;実際のトレンド)。
フロンティアモデルも市場の予測に反し、成長を維持するとの予測を示した。
次世代モデル向け計算環境
生成AIはモデルの規模が恒常的に拡大し、次世代モデルの開発では巨大な計算インフラが必要になる。
また、開発した巨大モデルを稼働させるプロセス(インファレンス)においても、大規模な計算施設が必要になる。このため、プロセッサの性能を向上させるだけでなく、システム全体で障害発生率を低下させ、稼働率を向上させる技法が極めて重要となる。
OpenAIは巨大モデルを開発した経験から、システム運用にかかる問題点とその改良技術を示した。

