[No.167]大規模言語モデルは性能向上の限界に近づく、トランスフォーマの効率の悪さが顕著になる、次のアーキテクチャの探求が始まる
サンフランシスコで開催されたAIエンジニアリングのイベントで「トランスフォーマ(Transformers)」の限界について議論が交わされた。
トランスフォーマとは大規模言語モデルの心臓部で、高度なインテリジェンスを発現し、AI開発のブレークスルーとなった。しかし、トランスフォーマが発表されてから7年たち、その問題点が顕著になってきた。
大学の研究室を中心に、トランスフォーマの次のアーキテクチャを探索する動きが活発になってきた。

トランスフォーマとは
トランスフォーマは大規模言語モデルのコア技術で、ChatGPTなど言語モデルに搭載され、高度な能力を示し、AI開発にブレークスルーをもたらした。
トランスフォーマは言語翻訳のために開発されたが、モデルの規模を拡大すると多彩な能力を発現し、テキスト生成、チャットボット、イメージ生成など、幅広いアプリケーションで使われている。
トランスフォーマの問題点:ビジネスの観点
しかし、言語モデルのサイズの拡大に伴い、トランスフォーマの問題点が顕著になってきた。
フロンティアモデル(最先端AIモデル)の開発では、巨大な計算施設が必要となり、AI開発が一部の企業に集中している。データセンタは「AIファクトリ」と呼ばれ、GPT-4など大規模モデルの開発ではAIスパコンが使われている。
フロンティアモデルの開発は数社が市場を制御し、技術や利益が偏在し、寡占状態が顕著になってきた。
トランスフォーマの問題点:テクノロジーの観点
技術の観点からは、トランスフォーマはアーキテクチャに起因する問題点が顕著になってきた。
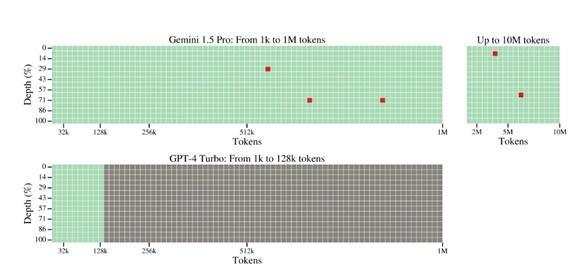
これはコンテクスト・ウインドウのサイズに関わるもので、入力するトークンの数(文字の数)が増えると、処理速度が急激に低下する。これは、「Long Sequences」問題と呼ばれ、長い文章を入力すると計算時間が急激に長くなる。
特にビデオなどマルチメディアの処理では、入力されるデータ量は巨大で、トランスフォーマの限界が議論されている。
下の写真上段、Googleの最新モデルGemini 1.5 Proのコンテクスト・ウインドウは1Mトークンで、最大で10Mトークン処理できる。言語モデルのコンテクスト・ウインドウのサイズが急速に拡大。
トランスフォーマ開発経緯
トランスフォーマは2017年に、Googleの研究チームが言語翻訳のために開発したモデルである。
この成果は論文「Attention Is All You Need」(下の写真)として発表され、世界の研究者はこのアーキテクチャに着目し、言語モデルの開発でトランスフォーマを導入し、技術革新をもたらした。
OpenAIはこのアーキテクチャをベースとする言語モデル「GPT」シリーズを開発し、これが大ヒット製品となった。

トランスフォーマの性能が低下する理由:Quadratic Scaling
トランスフォーマの問題はアーキテクチャに起因するもので、次のトークンを算出するメカニズムにある。
トランスフォーマは入力されたコンテキスト(文字列など)を解析し、その結果をストアする方式を取る。このため、長い文字列を入力すると、記憶容量と計算量が増大し、処理速度が急速に低下する。
これは「Quadratic Scaling」と呼ばれ、コンテキストの長さがN倍になると、計算量がN^2 (Nの二乗)となる。つまり、コンテキストの長さが10倍になれば、計算量は10倍ではなく、10の二乗の1024倍となる。
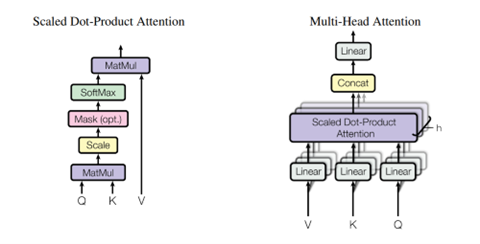
これが原因で、長いコンテキストやマルチメディアの処理で、インファレンス速度が急速に低下する。(下の写真、トランスフォーマの概念図、入力されたトークン(N)に対し、Attention (K(Key)、V(Value)、Q(Query))を計算するためにN x Nのマトリックス計算を実行する。このため、トークンの数(N)が増えると計算量はNの二乗となる。)
新しいアーキテクチャの探求
この問題を解決するため、大学研究室やスタートアップ企業が、トランスフォーマに代わる新たなアーキテクチャの研究開発を進めている。
スタートアップ企業Cartesiaは、新しいアーキテクチャを開発し、この概要を公表した。これは「State Space Models(SSMs)」と呼ばれるアーキテクチャで、長いコンテキストを効率的に処理できるメカニズムとなる。トランスフォーマが「Quadratic Scaling」であるのに対し、State Space Modelsは「Linear Scaling」で、長い文字列を高速に処理する。これにより、長い文字列やマルチメディアを高速で処理できる。
Cartesiaは大学の研究者で構成されたスタートアップ企業で、スタンフォード大学やカーネギーメロン大学の研究者が創業した。
State Space Modelsの概要
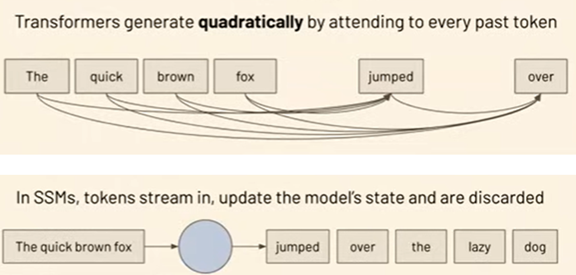
State Space Modelsは入力されたトークンを凝縮して「State」とし、次のトークンの算出では、このStateだけを参照する。
ちょうど、入力された音楽を圧縮してMP4ファイルを生成し、これをストリーミング配信して、高品質なサウンドを実現する技法に似ており、State Space Modelsは入力されたトークンを圧縮して「State」ファイルを生成する。
アーキテクチャの比較
アーキテクチャの観点から、トランスフォーマは入力されたプロンプトから次の単語を予測するために、全ての単語を参照する(下の写真上段)。
これに対し、State Space Modelsは入力されたトークンを「State」に凝縮し(下段、円の部分)、次のトークンを計算するために、Stateだけを参照する。
このため計算量が入力されたトークンに比例する。
最初の製品「Sonic」をリリース
CartesiaはState Space Modelsを実装した最初の製品として「Sonic」をリリースした。
SonicはリアルタイムのAIボイス(Generative Voice)で、自然な会話を実現する基礎技術となる。処理に要する時間は135 マイクロ秒で、人間と同じ速さで反応する。
CartesiaはこれをVoice APIとして公開しており、これをアプリに組み込んでコールセンターのAIアシスタントやゲームのキャラクターなどを構成する。また、「Playground」でボイス機能を使うことができ、異なる特性や英語以外の言語で試してみることができる。
(下の写真) 実際に使ってみたが、Sonicの反応速度は早く、OpenAIのGPT-4oと遜色は無いと感じた。
ロードマップ
Cartesiaは「会話型AI(Conversational Inference)」の他に、State Space Modelsをデバイスに搭載し、エッジ・コンピューティングの開発を計画している。
State Space Modelsはトランスフォーマと異なり、軽量で高速に実行できるため、スマートフォンなどのデバイスでの活用が期待されている。また、ヘッドセットなどのウエアラブルに搭載し、実社会でのAIエージェントを構成する。
更に、ロボットに搭載することで、インテリジェントなモデルを生成する。
若い頭脳が研究開発の中心
トランスフォーマに代わるアーキテクチャの探求では、アカデミアを中心に若い研究者の活躍が目立つ。
若い世代の研究者がフレッシュな視点から、AIモデルを見直し、斬新なアイディアを生み出している。今すぐにトランスフォーマを置き換えるわけでは無いが、トランスフォーマの弱点を補完する技術となる。
長期的には、State Space Modelsでイノベーションが生まれ、トランスフォーマの対抗基軸を形成すると期待されている。

