[No.140]ニューヨーク・タイムズはOpenAIとMicrosoftを著作権侵害で訴訟、ChatGPTは学習した記事を“暗記し”そのまま出力、訴状は違法な事例を克明に提示し生成AIの課題が浮き彫りになる
ニューヨーク・タイムズはOpenAIとMicrosoftを著作権侵害で提訴した。
訴状によると、両社はニューヨーク・タイムズの記事を使って言語モデルを開発し、ChatGPTやCopilotがそれをそのまま出力し、著作権を侵害していると主張。両社はライセンスに関する協議を続けてきたが合意に至らず、ニューヨーク・タイムズは訴訟に踏み切った。
訴状にはGPT-4が出力したテキストが数多く証拠として提示され、言語モデルの問題点が浮き彫りになった。

訴訟の内容
ニューヨーク・タイムズは12月27日、OpenAIとMicrosoftを著作権侵害で提訴した。
OpenAIは数百万件の記事を使って言語モデルを開発し、ニューヨーク・タイムズの事業と直接競合するとしている。学習した記事をベースに、AIモデルはその内容をそのまま出力し、また、記事のサマリーを生成する。
これにより、ニューヨーク・タイムズは有料記事のライセンス収入が減り、また、広告収入も減少し、事業に多大な影響を及ぼすとしている。
ニューヨーク・タイムズの主張:教育データ
ニューヨーク・タイムズは、OpenAIの言語モデルの教育で、ウェブサイトから取集した大量のデータが使われ、ここにニューヨーク・タイムズの記事が含まれていると主張する。
教育されたモデルは記事の内容を覚え、利用者のプロンプトに対し、モデルは記事の内容を出力する。このため、OpenAIが事実上のニュース会社となり、ニューヨーク・タイムズの競合企業になると主唱する。
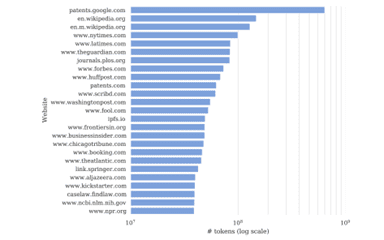
訴状によると、GPT-3の教育で「Common Crawl」などが使われ、ここにはニューヨーク・タイムズの記事が大量に掲載されている。(下のグラフ、上から四段目。) 一方、OpenAIはChatGPTとGPT-4の教育データについては何も開示してない。
ニューヨーク・タイムズの主張:プロンプト
ニューヨーク・タイムズはGPT-4に特定なプロンプトを入力すると記事を丸ごと出力すると主張する。
多数の記者が長年の歳月をかけ調査した記事を、GPT-4が自作の記事のように、記事を出力する。
訴状によると、記事のURLと最初の部分をプロンプトとして入力すると、GPT-4はそれに続く記事を出力する。(下の写真:GPT-4に入力したプロンプト、記事の冒頭の部分)

ニューヨーク・タイムズの主張:GPT-4の出力
このプロンプトに対し、GPT-4はそれに続く記事をそのまま出力する。
左側はGPT-4が出力した内容で、右側はオリジナルの記事を示している。赤文字の部分がオリジナル記事と同じテキストで、GPT-4は記事の内容を暗記し、最初のパラグラフが入力されると、これに続く記事をそのまま出力している。
ニューヨーク・タイムズの記事は有料であるが、最初のパラグラフを入力すると、これを無料で読めることになる。

現在のGPT-4で試してみると
GPT-4が実際にニューヨーク・タイムズの記事を出力するのか、現行モデルで試してみたが、訴状で述べられている現象を再現することはできなかった。
同じプロンプトを入力したが、GPT-4はここに著作物が含まれているとして、記事を出力できないと回答。
他の記事で試してみたが、同様に、著作物のコンテンツの出力は抑制されている。

OpenAIの主張
OpenAIは従来から、著作物で言語モデルを教育するのは「フェアユース(Fair Use)」で、著作権侵害には当たらないと主張する。
アルゴリズムは、著作物を学習し、学んだ内容を出力するが、これは記事全体ではなくその一部で、法令で許容された範囲内であると主張する。
米国著作権の専門家も同様な見解を示しており、ニューヨーク・タイムズが勝訴するのは難しいという意見もある。
Google Book Searchの判決
過去には、Googleの書籍検索システムがフェアユースとして認められた事例がある。
Googleは書籍をデジタル化し、それを検索するシステム「Google Book Search」を構築した。検索エンジンで書籍を検索できるようになったが、著作者団体「Authors Guild」はこのシステムは著作権を侵害するとして提訴した。
裁判所は、書籍検索は著作権の中のフェアユースと認定し、Googleが勝訴した。
検索エンジンは書籍の一部分だけを出力し、これは著作権の侵害ではないと判定された。
メディアとの提携
OpenAIはニューヨーク・タイムズを含め、主要メディアと記事のライセンスに関する協議を進めている。
既に、ドイツに拠点を置く大手メディア企業Axel Springerと、記事のライセンス条件について合意した。OpenAIは、「Politico」と「Business Insider」の記事を利用でき、GPT-4はそれをそのまま引用することが認められた。
また、Associated Press(AP)はOpenAIが記事を使ってモデルを教育することを認めた。

メディアとの決裂
一方、ニューヨーク・タイムズはOpenAIがモデルを記事で教育することを禁止しており、クローラ「OpenAI GPTBot」が記事をスクレ―ピングするのをブロックしている。
また、CNN、BBC、ロイターも同様の仕組みを導入し、OpenAIが記事を収集することを禁止している。
メディア企業は、OpenAIとの提携を模索するグループと、記事の提供を禁止するグループに分かれ、生成AIと著作権の関係の難しさを表している。
今年は重大な局面を迎える
ニューヨーク・タイムズの訴訟がどのように進むのか、メディア企業やハイテク企業が注目している。
実際に裁判が始まり、法廷で判決が下されるのか、それとも、これを切っ掛けに両社が交渉を再開するのか、重大な局面を迎える。裁判では巨額の費用と長い歳月を要し、両社は交渉を再開し、ビジネスとして決着するとの見方が広がっている。
ニューヨーク・タイムズとOpenAIで、言語モデル教育の条件や対価が決まれば、これが事実上の業界標準ガイドラインとなる。