[No.111]Metaは大規模言語モデル「LLaMA」を開発、これをオープンサイエンスの手法で公開し生成AIの危険性を解明する
Metaは大規模言語モデル「LLaMA (Large Language Model Meta AI)」を開発し、これを一般に公開した。
生成AIの開発が進み、OpenAIは「GPT-4」を、Googleは「Bard」を開発したが、これらはクローズドソースとして運用され、モデルに触れることはできない。
これに対し、MetaはLLaMAの内部情報を公開し、研究者はこれを使ってアルゴリズムの解明を進め、生成AIの危険性の解明が進むと期待される。

LLaMAとは
LLaMAはMetaが開発した大規模言語モデルで、アルゴリズムのサイズは小さいが、高度な機能を実現した。
このため、小規模なコンピュータシステムで稼働させることができ、大学などで言語モデルの開発が進むと期待されている。
生成AIの開発はOpenAIやGoogleが独占的に進めているが、LLaMAを利用することで研究機関でChatGPTに匹敵するモデルを開発することが可能となる。
実際に、スタンフォード大学は「LLaMA(ラマ)」(上の写真)をベースにした言語モデル「Alpaca(アルパカ)」(下の写真)を開発した。

AIモデルの概要
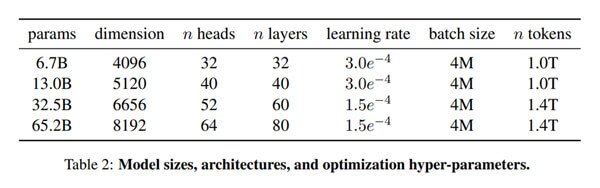
LLaMAは四つのモデルを提供しており、それぞれ、パラメータの数は67億、130億、325億、652億となる(下のテーブル)。
パラメータの数がアルゴリズムの規模を示し、その数が多くなるほどサイズが大きくなる。
OpenAIが開発したGPT-3のパラメータの数は1750億であるが、Metaによると、LLaMA-13B(130億)のモデルの性能が上回るとしている。
LLaMAの特長は、モデルの規模が小さいが高性能を達成することで、十分な計算施設を持たない研究機関で運用が可能となる。
ファウンデーションモデル
LLaMAは「ファウンデーションモデル(Foundation Models)」という種類のAIモデルとなる。
ファウンデーションモデルとは、プレ教育されたAIモデルを指し、これを目的に合わせて再教育(Fine-Tune)して利用する。
例えば、ファウンデーションモデルを金融データで再教育すると、フィンテックに特化したAIモデルを生成できる。
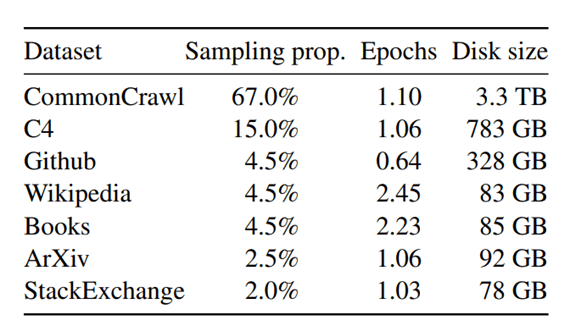
LLaMAはウェブサイトからスクレ―ピングしたデータ(Common Crawl)や、それを整備したデータ(C4)を使って教育された(下のテーブル)。
LLaMAのサイズは小さいが、大量のデータで教育されたため、高度な性能を示すことができる。
オープンサイエンスの手法
MetaはLLaMAを大学などに無償で提供しており、研究者はこのモデルを使って研究を進めることができる。
言語モデルは規模が大きくなると、アルゴリズムが内包する危険性が増大し、社会に甚大な被害を及ぼすことが問題となる。
LLaMAを公開することで、大規模言語モデルの仕組みや挙動の解明が進み、アルゴリズムのバイアスや有害な情報の出力を抑止できると期待される。
この手法は「オープンサイエンス」と呼ばれ、開発コミュニティでAIの研究を進め、アルゴリズムの危険性を解明する。
Metaは応募者を審査してソースコードにアクセスする権利を付与している。
LLaMAにアクセスするためには下記のサイトから申請する。
オープンソースの危険性
一方、大規模言語モデルをオープンソースとして公開することには危険性を伴う。
LLaMAのような高度なモデルが悪意ある団体の手にわたると、それが悪用され、社会に甚大な被害をもたらす。
特に、LLaMAを使うと個人に特化したスパムメールやフィッシングメールを大量に生成でき、サイバー攻撃広がると懸念される。
更に、LLaMAは高度な偽情報を生成し、国民世論を扇動する危険性も指摘される。
ソースコードがリーク
実際に、LLaMAの発表直後に、ソースコードがリークするという事件が発生した。
ソースコードのファイルがウェブサイト「4chan」に掲載され、誰でもが自由にアクセスできる状態になっていた。
具体的には、LLaMAをプレ教育した時のニューラルネットワークのパラメータ「Model Weights」がリークした。
これを使うと独自のAIモデルを開発でき、社会に害悪を与えるコンテンツが生み出される。
その後、LLaMAを悪用した被害は報告されていないが、オープンサイエンスの手法の弱点が露呈した。
リスクとメリットのバランス
生成AIの開発は完全にクローズドソースの手法で開発されている。
OpenAIはGPT-4を開発したが、API経由でモデルを利用することは認めているが、その内部情報は公開されていない。
これに対し、MetaはLLaMAを公開し、オープンサイエンスの手法でAI研究を進める。
モデルが悪用されるリスクはあるが、AI研究が進展するというメリットが大きいと判断し、公開に踏み切った。
生成AIを安全に運用するための規制が進んでいるが、Metaはこれを技術面から支えることになる。

