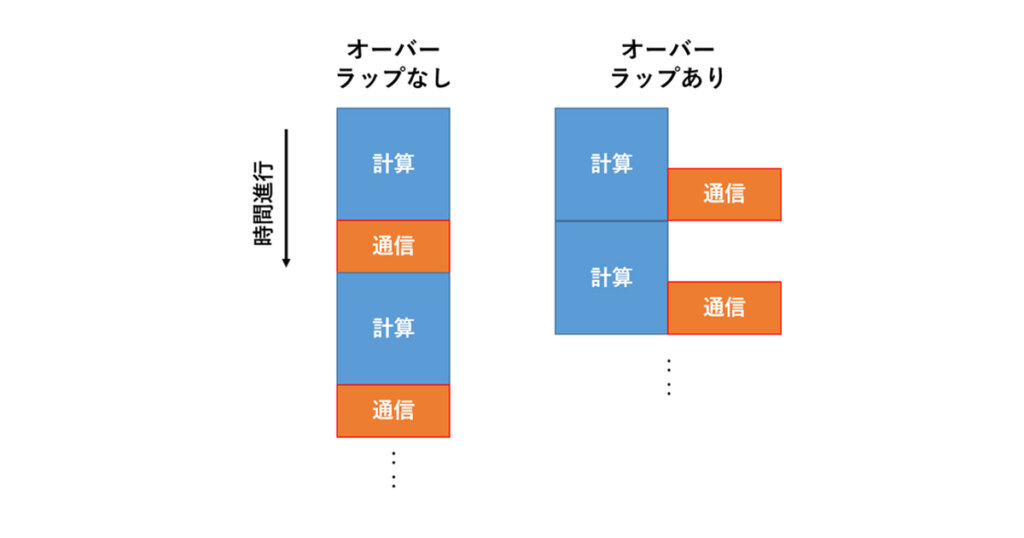
東京大学 助教 星野 哲也 先生にご執筆いただいているGPUコラム「OpenACCではじめるGPUプログラミング」は、中級編 第4回を掲載しました。MPI+OpenACC実装における計算と通信のオーバーラップ についてです。
著者:東京大学 助教 星野 哲也 先生
本文
前回はMPI + OpenACCによる拡散方程式のマルチGPU実装を行いましたが、性能向上できたのは4GPUまでで、8GPUでは逆に遅くなってしまったのでした。
今回はより高速化するためにはどうしたらいいのかについて解説していきます。

