深層学習による地形画像解析

深層学習による地形画像解析
著者:佐藤 周平 先生 / 法政大学 准教授
はじめに
近年のGPUや生成AIの飛躍的な進歩は、単一画像に潜む形状・材質・照明などの潜在情報を高精度に推定する技術を急速に発展させており、様々なタスクへ利用されています。
屋外建築や室内空間では、再照明やセグメンテーションが既に実運用可能なフェーズに入っており、XRやデジタルツインへの応用も進みつつあります。
しかし、山岳風景の場合、霧や大気散乱の影響が強く、また、植生や岩場などが複雑に混在するため、アルベド(物体固有色)や深度の推定精度が大きく低下するという課題があります。
本コラムでは、こうした自然地形固有の困難さを克服するために筆者らが取り組んでいる2つの研究事例について紹介します。
1つ目の研究[1,2]は、単眼地形画像を対象に、GANに基づく2段階モデルによりアルベドを推定し、また同時に深度を推定することで、任意の時間帯や天候条件へ再照明を行う手法です。合成データセットによりネットワークモデルを学習させることで、霧や影を含む実写地形に対しても高品質なアルベド推定を実現しています。
2つ目の研究[3]は、地形画像を植生と岩場という属性単位で分割するセグメンテーションフレームワークです。
手作業でのアノテーション負荷を避けるため、CGを利用した合成データセットを構築し、SAM2 (Segment Anything Model 2) [4]を地形専用にファインチューニングしています。
また、再照明用に推定したアルベド画像を入力とすることで、陰影の影響を除去した状態で属性を識別できる点が特徴です。また、両者を組み合わせた際に得ることが期待できる効果と今後の展望についても考察します。
1. 単眼地形画像の再照明
再照明とは、ある照明環境下で撮影された対象が、別の照明条件のもとでどのように見えるかを再現する技術です。
単一画像を対象とする場合には、入力画像から照明の影響を取り除いたアルベドと、形状を示す深度あるいは法線情報を同時に推定する必要があります。この推定を深層学習で行う流れが近年の主流ですが、既往研究の多くは都市景観や屋内シーンを対象としており、山岳風景のような自然地形では十分な頑健性が得られていません。これは、地形画像に含まれる霧や大気散乱の影響を考慮していないことや、自然地形に特化したデータセットが少ないことが原因として考えられます。
そこで筆者らは、霧や大気散乱を考慮した大規模合成データセットを作成し、TransformerベースのGAN [5]を用いた二段階モデルを訓練してアルベドを推定する手法を提案しました。また、最新の深度モデルを用いた3次元再構成を組み合わせることで、単眼地形画像の再照明を実現します。筆者らの手法の概要を図1に示します。
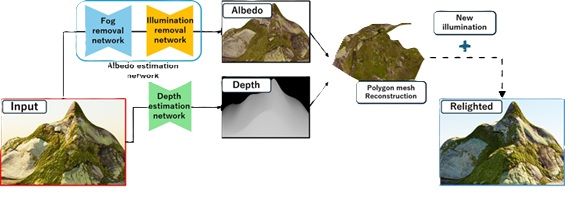
1-1. 合成データセット
深層モデルの性能はデータセットの品質に強く依存します。自然地形では入力画像と正解アルベドのペア収集がほぼ不可能であるため、筆者らはコンピュータグラフィックス技術を利用した完全自動の合成パイプラインを構築しました。
まずフラクタルノイズに基づいて得られる高さマップから地形メッシュモデルを生成し、その表面の法線に基づいて崖や地面など計4領域に分割します。そして、それぞれに166種のテクスチャをランダムに割り当て、さらに、岩石や植生といったアセットモデル10種を地形モデル表面に配置することで、山岳地形の複雑な見た目を再現します。
照明環境にはNishitaらの大気散乱モデル[6]を用い、あわせてカメラからの深度に基づいて霧を合成することで、霧や大気散乱による青みを除去できるようにします。そして、これらの地形テクスチャとアセット分布、および大気や霧のパラメータをランダムに決定し、BlenderのCycleを使用してレンダリングすることで、多様でフォトリアルな地形画像を自動で大量に得ることを可能としました。
1-2. 2段階のアルベド推定モデル
霧と照明効果の両方を除去するために、GANベースの影除去モデルであるSpA-Former [5]のネットワークアーキテクチャを採用しました。SpA-Formerは、TransformerエンコーダとGANネットワークで構成されています。
まず、入力された陰影付き画像は特徴マップに変換され、Transformerエンコーダに挿入されます。Transformerはシーケンス内の遠隔依存関係のモデリングを容易にする一方、局所的な情報を無視してしまう傾向があります。
そこで、空間注意メカニズムを持つTWRNN (Two-Wheel RNN Joint Spatial Attention)の採用によって特定領域の特徴量を評価し、局所的な精度を補完します。
また、一般的な陰影除去アーキテクチャでは影画像と非影画像の差分を学習するResBlock層を使用しますが、従来のResBlockは高周波成分に比べて低周波成分を捉えることが困難です。
そこで、低周波と高周波の両方の残差情報を統合するFTR (Fourier Transform Residual Network)が導入されています。このような特徴により、SPA-Formerは陰影の検出と除去という2つのステップを1つに統合し、相関や依存関係を考慮した陰影除去システムを実現しています。
筆者らは、このSpA-Formerを2つ並べた2段階モデルを構築し、前節の合成データセットを用いて事前学習済みのモデルをファインチューニングすることで、霧と照明効果を順に除去可能なアルベド推定モデルを実現しました。
1-3. 深度推定と3次元再構成
再照明では形状情報も不可欠です。筆者らは Depth Anything V2 [7]を用いて深度推定を行いました。
Depth Anything V2は訓練に用いるすべてのラベル付き実画像を合成画像に置き換え、さらに教師モデルの容量を拡大することで、より堅牢なZero-Shot単眼深度推定を実現しています。
推定した深度をディスプレイスメントマップとして利用したポリゴンメッシュに3次元形状を再構成し、大気散乱を考慮したシェーディングでレンダリングすることにより、単眼の山岳地形画像に対する再照明を実現しました。
1-4. 結果
大気散乱モデルのパラメータを変えて異なる時間帯を再現した3種類の照明環境を作成し、それらを用いて生成した再照明結果を図2に示します。
モデルの学習には、NVIDIA RTX A6000を搭載したコンピュータを使用しました。筆者らの2段階モデルにより推定されたアルベドおよび、Depth Anything V2により得られた深度から、異なる時間帯の地形画像を表現できています。
特に、再照明後の画像はどれも入力画像の色や形状といった特徴が保たれており、提案したデータセットと手法は、地形画像への再照明に適していると言えます。

2. 属性単位の地形画像セグメンテーション
続いて属性単位で地形画像をセグメンテーションする手法を紹介します。
材質の反射特性がまったく異なる植生と岩場を区別できれば、再照明の際により正確な材質を割り当てられ、結果のクオリティを向上させられる可能性があります。しかし、汎用的なセグメンテーションモデルでは、数十〜数百のラベルにより山肌の小片を過剰に分割してしまう、いずれのラベルも付与されない場合がある、といった問題があります。
そこで筆者らは、植生や岩場といった属性ごとにラベル付けした合成データセットを構築し、事前学習されたセグメンテーションモデルを訓練することで、地形に特化した属性単位のラベルによるセグメンテーションを実現しました。この手法の概要を図3に示します。
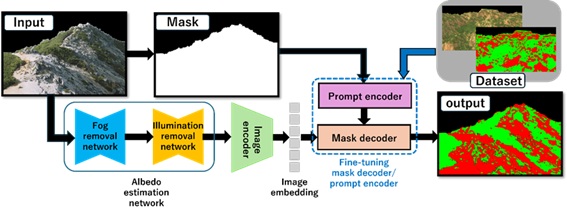
2-1. データセット
ノイズを基に地形のメッシュモデルを生成し、表面法線の垂直成分の勾配が閾値以下の領域を植生、それ以上を岩場に分類するルールを設定し、自動でアノテーションマップを生成しました。
このようにして1000組のデータセットを作成し、訓練データとして使用します。
2-2. セグメンテーションモデルと学習
セグメンテーションには、Segment Anything Model 2 (SAM2) [4]を利用します。
SAM2は、Meta AIによって開発された画像セグメンテーションのためのモデルです。SAM2は、画像内の任意の物体をセグメントすることができる汎用的なセグメンテーションモデルで、事前学習された重みを用いることで高い精度が得られます。
SAM2は高精度なセグメンテーションが可能ですが、多数のラベルが付与されてしまうため、筆者らの目的である属性ごとのセグメントはできません。
そこで、前節のようにラベル数を限定したデータセットを構築し、SAM2をファインチューニングすることで、属性単位にセグメンテーションできるよう改良します。入力画像には再照明手法の2段階モデルにより推定したアルベド画像を用い、陰影と霧の影響を事前に除去します。
ファインチューニングは100,000イテレーション実行しました。さらに、地形領域をマスクし、その座標をプロンプトエンコーダに渡すことで、地形の部分のみをセグメントすることができます。
2-3. 結果
図4に筆者らの手法を用いたセグメンテーション結果を示します。いずれの入力画像においても、地形領域を2つのラベルに分割できていることが確認できます。

また、SAM2の事前学習済みモデルと筆者らの手法によってファインチューニングされたモデルによるセグメンテーション結果の比較を図5に示します。
SAM2では、多数のラベルを生成していることに加えて、ラベルが付与されていない部分が多くみられます。一方で、ファインチューニング後の筆者らのモデルは、植生と岩場の2つの領域に分割できていることが確認できます。

3. 今後の方向性
筆者らは今後、再照明モデルにセグメンテーションを統合し、属性ごとに高精度にアルベドや光沢情報を推定できるようなモデルについて検討を進める予定です。
セグメンテーションにより、各領域の属性が何か、という情報が得られるため、これまで以上にマテリアル推定の学習効率や精度を向上させられる可能性があります。
また、雪氷や水域、赤土など属性ラベルを拡張するため、それらに対応する合成データの自動生成や、データ数を最低限に抑えるためのパラメータ探索についても検討していく予定です。
4. おわりに
筆者らが取り組んでいる、深層学習に基づく山岳地形画像の再照明および属性単位のセグメンテーションについて紹介しました。
これら2つの研究はまだ萌芽段階ながら、単一画像から材質と形状を推定し、物理的にもっともらしい再照明を実現する未来像を示しています。
将来的には、霧が立ち込める山岳写真をユーザの求める時間帯や天候で再描画し、その上で材質ごとに適切な反射特性を自動で割り当てる、といったことも可能になるかもしれません。
参考文献
[1] Shun Tatsukawa, Syuhei Sato, A Relighting Method for Single Terrain Image based on Two-stage Albedo Estimation Model, SIGGRAPH Asia 2024 Posters, Article No. 97, 2024 [2] 立川 駿, 佐藤 周平, 属性の特徴を考慮した単眼地形画像の再照明に関する一実験, 情報処理学会 第87回全国大会, No. 2S-01, 2025 [3] 津田 康汰, 立川 駿, 佐藤 周平, 地形画像における属性単位のセグメンテーションに関する一検討, 情報処理学会 第87回全国大会, No. 4W-08, 2025 [4] N. Ravi et al., SAM 2: Segment Anything in Images and Videos, arXiv preprint, 2024, https://arxiv.org/abs/2408.00714. [5] X. Zhang, Y. Zhao, C. Gu, C. Lu, and S. Zhu, SpA-Former:An Effective and lightweight Transformer for image shadow removal, In IJCNN 2023, 1–8, 2023. [6] T. Nishita, T. Sirai, K. Tadamura, and E. Nakamae, Display of the earth taking into account atmospheric scattering, In Proceedings of SIGGRAPH ’93, 175–182, 1993. [7] L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, Depth anything v2, arXiv:2406.09414, 2024.著者紹介

佐藤 周平 先生
法政大学 情報科学部 准教授
プロメテックCGリサーチ 研究員
2009年,北海道大学工学部卒業.
2011年,同大学大学院情報科学研究科修士課程修了.
2014年,同大学大学院情報科学研究科博士後期課程修了.
同年,株式会社ユビキタスエンターテインメント UEIリサーチ 研究員.
2015年,株式会社ドワンゴ CGリサーチ 研究員.
2019年,プロメテック・ソフトウェア株式会社 CGリサーチ 研究員.
同年,富山大学学術研究部工学系 助教
2022年より現職.博士(情報科学).
主としてコンピュータグラフィックスに関する研究に従事.
Visual Computing VC Young Researcher Award他.
