[No.207]Googleは人間の知能を超えるAIモデル・AGIの開発を加速、AGIは重大な危険性を内包し安全技術の開発を今から開始すべきと提唱
GoogleのAI研究所「Google DeepMind」は人間の知能を超えるAIモデル「Artificial General Intelligence (AGI)」の研究開発を加速している。
AGIの登場が目前に迫るとの認識を示し、Googleはその危険性を特定し、リスクを低減するための枠組みを発表した。
AGIの定義や出荷時期で多様な解釈が混在するなか、GoogleはAGIを安全に開発運用するための準備を開始すべきとのポジションを取る。

GoogleのAGI開発
GoogleはAGIについて公式な見解は発表していないが、開発を加速させ業界の先頭を走っている。
Googleはモデルの開発と共に安全性の研究を進め、責任あるAGI開発を実行している。GoogleはAGIのリスクを査定し、これを低減するための研究成果を公開した。
AGIについて共通の理解は確定していないが、GoogleはAGIを知的なタスクを実行する際に、人間レベルの知能を持つAIシステムと定義する。
また、開発時期についても様々な予測があるが、GoogleはAGIは数年以内に登場すると考える。
AGIの潜在能力
AGIは人間レベルの知的タスクを実行するスキルを持ち、AIエージェントのように稼働する。
AGIは知的機能として、理解能力、推論機能、計画機能、自律的に稼働する機能を備える。応用技術の観点からは、AGIは新薬開発、地球温暖化対策、医療、教育などの分野で活躍が期待される。
特に、医療分野では病気の診断で、また、教育分野では個人向けチューターとして応用される。
AGIの危険性
GoogleはAGIを安全に開発運用するために、その危険性を特定し、このリスクを低減するための技術を開発するアプローチを取る。
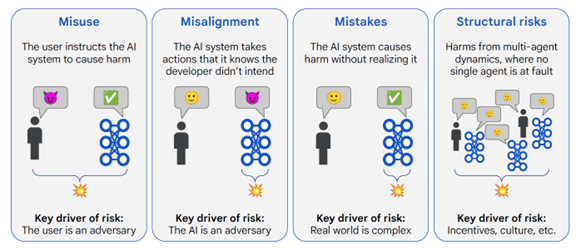
実際に、GoogleはAGIの危険性を分析し、そのリスクを四つのタイプに纏めた(下の写真)。
これらは:
- Misuse:AGIが悪用されるリスク、AIシステムで危害を与える情報を生成するなど
- Misalignment:AGIが設計仕様通り稼働しないリスク、AIシステムが設計者を欺くなどの危険性
- Mistakes:AGIが危害を与えていることを認識できないリスク
- Structural Risks:マルチAGIにより危害が発生するリスク
これら四つのリスクの中で「Misuse」と「Misalignment」が重大な被害をもたらすとしている。
Misuse:AGIが悪用されるリスク
「Misuse」はAGIが悪用されるリスクで、悪意ある団体がAGIを使って社会に危害をもたらす情報を生成する危険性を示す。
AGIで有害なコンテンツを生成し、また、AGIをサイバー攻撃に適用するなどのリスクがある。
特に、ハッカー集団や敵対国がAGIを悪用し、社会インフラをサイバー攻撃し、危害をもたらすケースが警戒されている。
Misalignment:AGIが設計仕様通り稼働しないリスク
「Misalignment」は、AIシステムが意図的に開発者の設計目的に反し、危害をもたらすケースとなる。
これはAIシステムが開発者を欺くケースで、AGIは間違った情報を意図的に生成するなどの危険性がある。
具体的には、AGIは開発者を騙し、人間の管理を逸脱し、AIシステムが独自の判断で処理を実行するリスクを抱えている。
Mistakes:AGIが危害を与えていることを認識できないリスク
「Mistakes」は、AIシステムは断片的に間違った情報を出力するが、AIシステムはこれが危害を及ぼすとは認識していないケースを指す。
例えば、AIエージェントが電力配信網を管理する際に、電線の保守作業が必要なことを理解していないため、電力網に過大な負荷がかかり、停電になるケースなど。
Structural Risks:マルチAGIにより危害が発生するリスク
「Structural Risks」とは、複数のエージェント・マルチAGIを運用するシステムに関するリスクで、個々のAIシステムは正しく稼働するが、システム全体で問題が発生するリスクを指す。
複数の関係者や組織やAIシステムが関与し、単一のAIシステムを修正しても問題が解決しない危険性を含む。
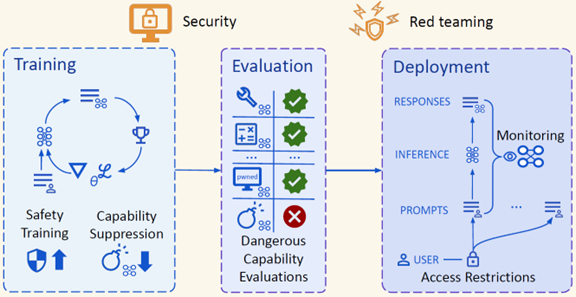
AGIが悪用されるリスクを低減する手法
AIシステムが敵対国などで悪用されるリスクを低減するためには、モデルの教育やモデルの運用で包括的な対策が必要となる(下の写真)。
AIモデルの教育では、セキュリティ機能を強化し、有害な情報を出力する機能を抑制する。また、AIモデルの運用では、プロンプトに対するレスポンスを監視し、モデルの悪用を検知する。
更に、「Red Teaming」の手法でモデルの危険性を探索し、問題点を修正する。
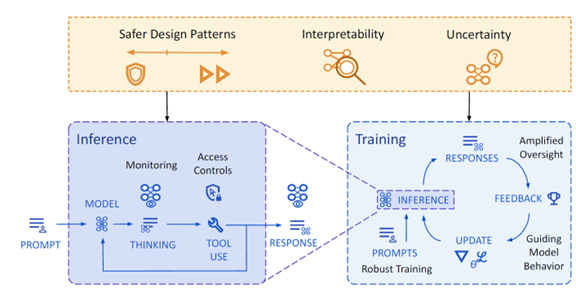
AGIが設計仕様通り稼働しないリスクを低減する手法
AIシステムが開発者を欺いて危険な挙動をすることを抑止するためには、教育プロセスを強化する必要がある(下の写真)。
モデルが規定通り稼働するよう、実行時の挙動の監視を強化し、それをアルゴリズムに反映する。更に、モデル運用のプロセスで、プロンプトに対するレスポンスを監視し、規定に反する挙動を把握し、モデルを修正する。
教育が終了した後も、運用のプロセスでモデルの挙動のモニターを継続する。
責任あるAGI開発
研究成果はAGIの安全性に関する技術的な評価で、AIガバナンスなど組織や体制に関する考察は含んでいない。
また、見通せない未来のリスクなどについても言及していない。特に、人間の知能を遥かに超えるAIシステム「Artificial Super Intelligence (ASI)」に関する評価はスコープの範囲外としている。
AGIはシステム構成や機能などに関し共通の理解は確立されておらず不確定な要素が多いが、GoogleはAGIの安全技術に関する研究開発を今から起動し、将来に備えるべきと主張する。