[No.187]Alibabaは生成AI推論モデル「QwQ」をオープンソースとして公開、ベンチマークでOpenAIを上回る、AI開発で米中間のギャップが縮まる
Alibabaは推論モデル「QwQ」をリリースしこれをオープンソースとして公開した。
推論モデルはと論理的な思考ができるAIで、指示されたタスクを分類整理して筋道を立てて結論を導く。インファレンスのプロセスでは複数の考え方を実行し、その中から最も確からしい結果を回答として出力する。
OpenAIは推論モデル「o1」をリリースしたが、その直後に、AlibabaはQwQを公開し、OpenAIの性能を上回る実力を示した。
中国企業は推論モデルの分野で高い実力を示しており、AI開発で米中間のギャップが縮まっている。

QwQの概要
Alibabaは11月28日、推論モデル「QwQ-32B-Preview」をリリースした。
Alibabaは大規模言語モデル「Qwen」を開発しており、この部門が研究開発のプロジェクトとして推論エンジンQwQ (Qwen with Questions) を開発した。QwQはオープンソースとして公開され、誰でも自由にこのモデルを利用することができる。
QwQ-32B-Previewは製品化前のプレビュー版で、機能に制約があるものの、実際に使ってみて推論機能の完成度を検証することができる。
モデルの構成
QwQ-32B-PreviewはAlibabaの大規模言語モデル最新版「Qwen2.5」(下の写真)をベースに構築された推論モデルとなる。
パラメータの数は32.5Bで、プレ教育されたQwen2.5をポスト教育のプロセスで推論機能を付加した構造となる。QwQは回答を提示する前に、深い考察を実行し、問われたことに対し最適な解を選ぶ。
実際に、QwQはインファレンスのプロセスで、複数の推論を設定し、それらをステップごとに考察を進め結論を導く。
最終的に、複数の結論を検証して、問われたことに対しベストな解答を選び、これを出力する。
実際に使ってみると
QwQのインターフェイスが公開されており、実際に使って推論機能を検証できる。
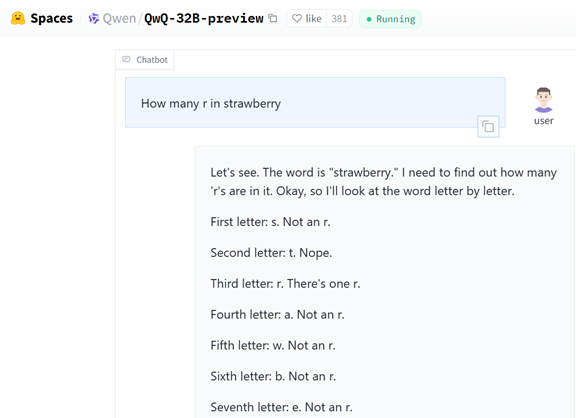
推論モデルを試験する典型的な質問は「”Strawberry”という単語に”r”はいくつあるか」で、実際に、QwQにこの問題を質問した。
QwQは問われたことを整理して、筋道を立てて検証を進め、正しい結論を引きだした。QwQは単語の文字を一つずつ検証し、これが”r”かどうかを判定し、答えは「3」と回答した(下の写真)。
推論のループ
上記の質問は代表的なベンチマークで、多くのモデルはこれを解くことができる。
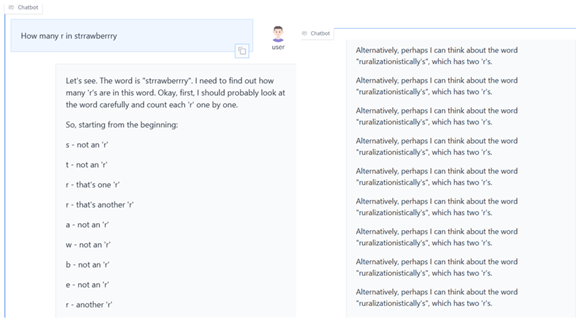
今度は、単語のスペルを間違えたケースでQwQに質問した。「”Strrawberrry”という単語に”r”はいくつあるか」という問いを入力した(下の写真)。
QwQは上述の論旨を適用し、答えは「5」であると正しい回答を引き出した(左側)。しかしこのケースでは、その他の推論法式を導入し、この答えが正しいかどうかを検証する作業を始めた。
検証プロセスでも答えは「5」であるとの結論に到達した。しかし、QwQは更に、別の考え方を導入し、答えが正しいかどうか、再度検証を進めた。
最終的には、検証プロセスがループ状態となり(右側)、最終解を提示することができなかった。途中経過では正しい答えを算出したが、これを確認するプロセスで“考えすぎ”により解を生成できなかった。
この状態は「Recursive Reasoning Loops」と呼ばれ、AlibabaはQwQの制限事項として説明している。
ベンチマーク結果
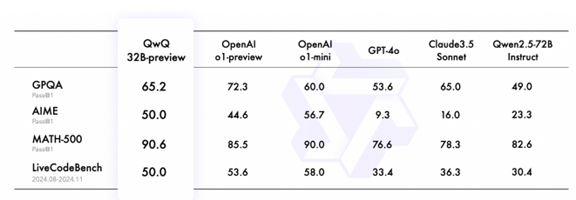
AlibabaはQwQの性能についてそのベンチマークテストの結果を公開している(下のテーブル)。
これによると、四種類のベンチマークテストのうち二つの種目で、QwQがOpenAI o1-previewを上回っている。これらはAIMEとMATH-500で、どちらも数学の技能を査定するもので、前者は中学生レベルで、後者は数学を経済やビジネスに応用する手法を検証するもので大学生レベルの機能となる。
QwQは推論モデルであるが特に数学の機能に特徴がある。OpenAIはo1-previewを9月にリリースしており、Alibabaは二か月ほどでこれを上回ったことになる。
プレ教育からポスト教育に
OpenAIを筆頭に多くのAI企業は開発戦略を見直し、AIモデルの規模の拡大から推論機能の強化に重点を移している。
推論機能とは人間のように論理的な思考ができるモデルで、コーディングや数学など科学技術の分野で威力を発揮する。開発技法の観点からは、大規模言語モデルの開発で、プレ教育からポスト教育に比重が移っている。
プレ教育はインターネット上のデータでアルゴリズムを教育する手法であるが、モデルの規模を拡大しても性能が上がらないという問題に直面している。このため、ポスト教育でモデルを再教育することで、アルゴリズムをインテリジェントにし、推論機能を強化する手法が取られている。
大規模言語モデルの開発はポスト教育が技術競争の主戦場となった。

