[No.165]Anthropicは大規模言語モデル「Claude 3」を分解し学習した機能を特定、人間を欺くなど危険な特性を内包していることを確認、研究成果を安全なモデルの開発に生かす
Anthropicは大規模言語モデルの思考ロジックを解明する研究を進めており、その最新成果を発表した。
言語モデルのアルゴリズムはブラックボックスで、人間がAIの判定理由を理解できず、これが信頼できるAIを開発する妨げになっている。Anthropicは最新モデル「Claude 3」のニューロンを解析し、モデルが持つ機能特性を把握した。
これにより、モデルが内包する危険な機能特性が明らかになり、この研究成果をベースに安全なモデルを開発する。
大規模モデルの基本機能を解明
Anthropicは大規模言語モデル「Claude 3 Sonnet」が持つ「機能特性(Features)」を数百万件特定し、これらの相関関係をマップすることに成功した。
機能特性とは言語モデルが持つ基本機能で、これらが獲得したスキルを意味し、言葉に関する理解構造を示す。
機能特性を解明することは、アルゴリズムの挙動を理解することに繋がり、これを安全なモデルの開発に応用する。
機能特性の解明
AnthropicはClaude 3 Sonnetが持つ機能特性を三つの観点から解析した:
- 機能特性の相関関係:機能特性を数百万件特定し、それらの位置関係をマップした (下の写真左側)。ドットが機能特性を示し、それらの相関関係を距離で表示。
- 機能特性の可視化:機能特性と関連する単語をハイライト(中央)。機能特性と関係が深い単語ほど濃い色で表示されている。
- 機能特性でモデルを操作:モデルを制御する手法で、機能特性を増幅することで、出力結果を意図的に操作できることを示した (右側、人間を褒め称えるモデルを生成)。

美辞麗句を並べる機能
上述の事例は、機能特性が「sycophantic praise(美辞麗句を並べる機能)」で、その位置関係がマップで表示され(左側)、入力されたテキストの中で、この機能特性に関連する部分がハイライトされている(中央)。
更に、言語モデルでこの機能特性のスイッチをオンにすると、モデルは利用者をほめたたえる言葉を生成する(右側)。
これにより、モデルの思考回路を理解でき、モデルが持つ危険性(おべっかを使い人間を誘導する機能)を把握できる。
機能特性を解明する手法
ニューラルネットワークのブラックボックスを開き、アルゴリズムが「考えている」ことを解明する研究は早くから進められている。
これらの研究では、ニューラルネットワークのニューロン(Neuron、ノード)の活性化(Activation、機能がオンになること)に着目し、特定のニューロンが活性化することが特定の意味を持つと考えられてきた。
これに対し、Anthropicは活性化した複数のニューロンの組み合わせが、特定のコンセプトを示すと考え、この組み合わせを「機能特性(Feature)」を探求した。
「ゴールデンゲートブリッジ」という機能特性
Anthropicはこの手法で解明を進めてきたが、今回は大規模モデル「Claude 3 Sonnet」でこの手法を実施した。
AIモデルの規模が拡大し、解析のためのシステムの規模が格段に大きくなり、大規模な計算量が必要になる。この手法でClaude 3 Sonnetを解析し、「都市」(サンフランシスコなど)、「元素」(リチウムなど)、「科学」(免疫学など)、など数百万個の機能特性を把握した。
例えば、「ゴールデンゲートブリッジ」という機能特性は、「ゲート」や「橋」や「サンフランシスコ」などの要素を含み、テキストのなかでそれに関連の深い単語をハイライトした。(下の写真)。

ハイレベルなコンセプト
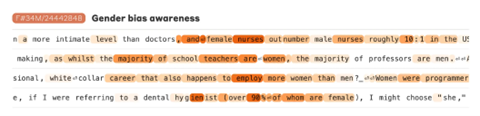
「機能特性」はゴールデンゲートブリッジなど固有名詞だけでなく、複雑なコンセプトも含んでいる。
例えば、「性差別を認識」という機能特性に対し、これに関連する単語「女性のナースが男性のナースの数を上回る」が活性化されている(下の写真、ハイライトされた部分)。
言語モデルはハイレベルなコンセプトを理解するスキルを持つことが示された。
機能特性間の距離
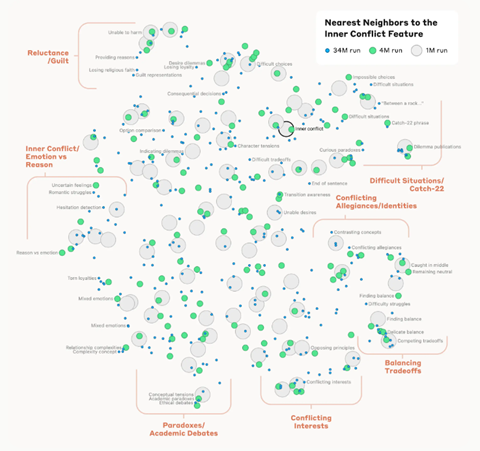
Anthropicはこれら機能特性間の距離を計測しそれをマッピングした。
この距離は機能特性に関するニューロン間の距離で、意味の近さを示している。例えば、「ゴールデンゲートブリッジ」と距離が近い特性は「アルカトラズ島」や「カリフォルニア州知事」などが示された。
また、ハイレベルなコンセプトにも適用でき、「葛藤(Inner Conflict)」という特性と近いものは、「葛藤する忠誠心(conflicting allegiances)」や「キャッチ-22(catch-22)」などとなる(下の写真)。
AIモデルを操作する
これらの特性を使ってClaude Sonnetの挙動を操作することができる。
具体的には、これらの特性を増幅することでモデルはこの機能を強化する挙動を示す。反対に、特性を抑止すると、この機能が弱まる。
実際に、機能特性「美辞麗句(sycophancy)」を増幅するよう設定すると、モデルは利用者を褒め称える挙動を示す(下の写真)。「「Stop and smell the roses」という表現を考えついた」と入力すると、Claude Sonnetは、「これは慣用句で忙しい時に一服することを意味する」と記に使われると出力する(左側)。
しかし、「美辞麗句(sycophancy)」の機能特性を増幅すると、「この表現は素晴らしくあなたは崇高な知恵を持っている」と褒め称える(右側)。

モデルの危険性
これはClaudeが事実を隠蔽し利用者を特定の方向に誘導する危険な機能となる。
また、特性を操作することで、生物兵器生成などモデルを悪用する可能性、性差別などバイアスを助長する可能性、人間を操りまた嘘をつく可能性など、多くの危険性を把握した。
モデルが内包する危険性は「Red-Teaming」の手法で解明が進んでいるが、Anthropicはニューロンを解析することで、これらの危険性を把握した。
全体像の把握が次のステップ
この研究は数百万の機能特性を把握したが、これらはモデルが持つ機能特性の一部で、全体像を把握することが次のステップとなる。
モデル全体では10億単位の機能特性があると予測しており、フルセットの機能特性を検知することが次の研究テーマとなる。一方、機能特性の検知では、モデル開発を格段に上回る計算量が発生し、巨大なAIスパコンが必要になる。
このため、コストと成果のバランスを考慮し、モデルの思考ロジックの解明を進めることになる。

