GPUの起源と進化

GPUの起源と進化
柿本 正憲 先生
東京工科大学 教授、プロメテックCGリサーチ 研究員
1. はじめに
GPUの源流は、1982年に発表されたジオメトリーエンジン(Geometry Engine)です。
本稿ではGPUがどのように誕生し進化したかを振り返ります。
筆者は1990年代後半にシリコングラフィックス(Silicon Graphics, Inc.)の日本法人にシステムエンジニアとして勤務し、ハイエンド3D CGのコンピューターシステム(ワークステーション)の導入やインハウスのプログラマーへの支援を担当していました。
顧客は主に、国内の大手メーカーや研究所で、ときにはアジアの拠点に赴き、中韓台シンガポールの顧客を支援することもありました。
GPUの機能がボードや筐体に分散していた頃で、フレームメモリを積んだ追加ボード1枚が2000万円から4000万円もしていました。ハードウェア構成をどうするかは顧客にとって重大問題でした。アプリも少なく、顧客は自らプログラムを組んで問題解決を行う場合が多い時代でした。
ハード、ソフトの両方を業務とし、技術製品開発者と顧客との橋渡しをした者の視点で、多少の人間ドラマも交えて、GPUの発展を振り返ってみたいと思います。
2. GPU以前の実時間描画のシステム
3D CGの基本的処理として、三次元の仮想空間に配置した形状モデルを二次元の画面上に対応づける座標変換があります。
多数の頂点座標に対して同じ処理を行うため、この座標変換を高速化することは描画処理全体を高速化することに直結します。
1982年にスタンフォード大学のジム・クラークは座標変換に特化したチップ(ジオメトリーエンジン)を考案しました[1] 。
彼はこの技術を広めるために、大学院生とともにシリコングラフィックスを1982年に起業しました。
80年代はCG分野で現在の基盤となる高度なアルゴリズムが多数研究された年代で、光線追跡法(レイトレーシング)、ラジオシティ法、ボリュームレンダリング、レンダリング方程式、経路追跡法(パストレーシング)、フラクタルなどが紹介されました。
動力学シミュレーション、流体シミュレーションがCGで研究されるようになったのもこの時期です。
そしてこの80年代は、CG処理を高速で実行する多数のハードウェアシステムが研究され、商品化された時期でもあります。
その中でシリコングラフィックスの「IRISシリーズ」というラスター処理のシステムが市場で優位を占めるようになり、90年代前半にはCGの研究開発や応用を行う者にとって同社のワークステーションは必須の道具となりました(ちなみに、最盛期の同社営業は電話を受けて注文を断ることがその業務だと言われるくらい市場を占有しました)。
シリコングラフィックスのカート・エイクリーらは、1988年に三角形の塗りつぶし処理を行う方式を発表しました[2] 。
彼のラスター化方式は、後年のGPUの処理そのものであり、現在でもこの方式が使われています。エイクリーは同社の創業メンバーであり、ジム・クラークの研究室の修士学生でした。
またエイクリーは、CGプログラマーが同社のワークステーションで描画処理を記述するためのグラフィックスライブラリとしてIRIS GLを提供しました。
シリコングラフィックスのハードウェアが普及した理由の一つがこのIRIS GLの使い易さです。
1990年代には関数名などを整理してオープン化し、OpenGLとして普及しました。
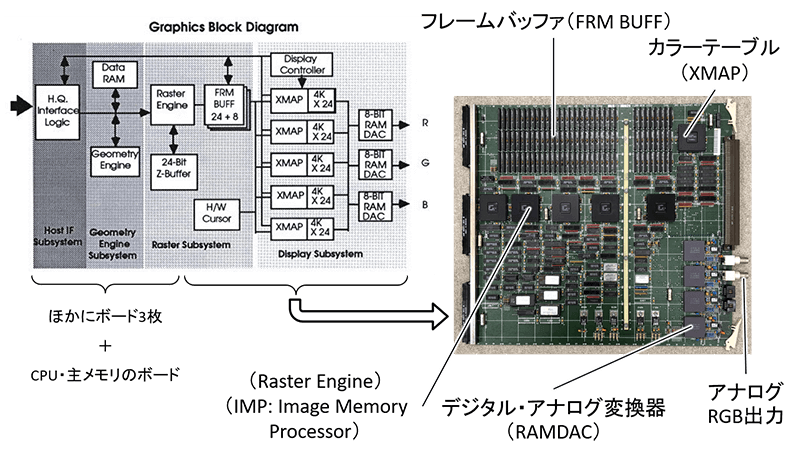
図1は、同社のワークステーションPersonal IRIS(1990年頃)のグラフィックス部分のブロック図とボードの一部です[3] 。
このブロック図全体のうちフレームバッファ(”FRM BUFF”)を除く部分が概ね現在のGPUチップに相当します。当時はこのブロック図に相当する部分が大きなボード4枚で構成されていました。
ブロック図の最初の主な処理は頂点処理で、ジオメトリーエンジンのチップが載ったボード(”Geometry Engine Subsystem”)で実行されます。
CPUの主メモリから転送されてきた3D空間内の三角形の頂点座標に4×4行列を乗じていき、最終的にはスクリーン座標の値を得ます。後年の頂点シェーダーの処理です。
写真のボードは、処理の最終段階を担うもので、フレームバッファに塗りつぶし結果を格納する”Raster Subsystem”と、画像のRGB出力を行う”Display Subsystem”が載っています。後年で言うと、ラスタライズ処理部分とフラグメントシェーダー(ピクセルシェーダー)処理部分です。
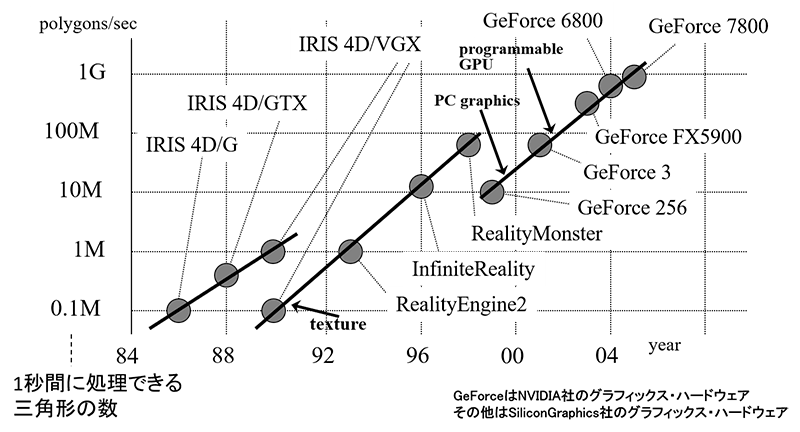
図2は、1980年代後半から2000年代中頃までのグラフィックスハードウェアの処理性能のグラフを示しています。
一つの目安として、1秒間に座標変換処理を何頂点に対して実行できるか、という頂点処理性能を縦軸に対数軸で示しています。
グラフが2か所で不連続になっているのには理由があります。
1990年で性能が一桁下がったのはテクスチャマッピングの機能が標準的に加わったことがその理由です。
1998年頃で一桁下がったのは、それまでは高価なワークステーションのシステムだったのが、GPUチップ登場によりPCベースの安価なシステムが標準になったためです。
ちなみにこのときコストは、1~2億円から20万円程度と三桁下がっています。つまりこの時点でコストパフォーマンスは100倍になったということです。
また、このグラフ全体を見ると、ほぼ一貫して3年ごとに十倍程度の性能向上が実現されていることがわかります。2005年頃までで、このグラフは終わっていますが、頂点処理性能という指標が意味をなさなくなったためで、詳細は後述します。
3. GPUの登場とプログラマブル化
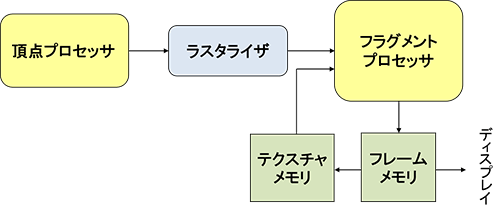
1990年代前半には、CGの実時間描画(リアルタイムレンダリング)処理であるラスタライズ方式が確立しました。
後年プログラマブルGPUの登場後には「固定機能パイプライン」と呼ばれるもので、その処理の流れを図3に示します。
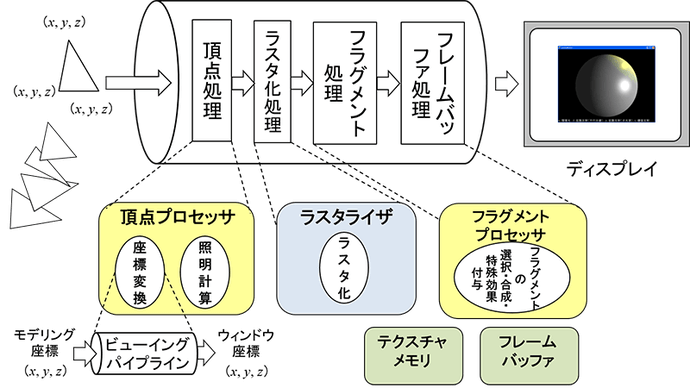
頂点プロセッサで座標変換と頂点の輝度を計算し、線形補間で三角形内部の画素を塗りつぶしたラスタライズを行い、フラグメントプロセッサで画素ごとの処理を行いフレームバッファ(画像メモリ)に結果を格納します。
90年代半ばのシリコングラフィックスのハイエンド製品でも数枚のボードでこれらの処理を行っていました。
実は、当時から図3のプロセッサの部分をカスタマイズすることで、プログラマブルな処理は可能でした。そのやり方は、内部のEEPROM(書き換え可能な読み出し専用メモリ)に埋め込まれたマイクロプログラムを書き換えるという方法です。
図3のプロセッサ部分を詳細化したのが図4です。
マイクロプログラムは、チップ集積度が低く演算ユニットが少なかった時代の工夫で、一つの演算器を使いまわす方式です。
一つのまとまった処理(例えばベクトルと行列の乗算)の実行には複数回の演算器使用が必要になります。
使いまわしはマイクロコードのビットパターンに応じて演算制御回路内のスイッチを切り替え、各種レジスタ(高速キャッシュメモリ)の中間出力結果を次の入力にすることで多段階の処理を行います。
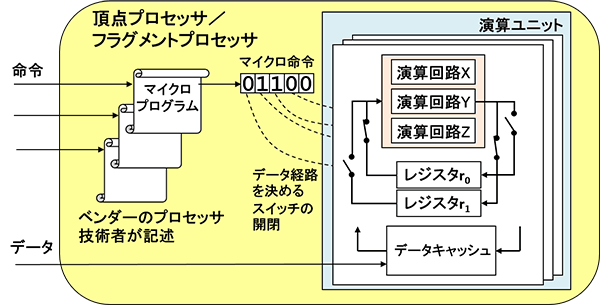
およびフラグメントプロセッサ(シリコングラフィックス社InfiniteReality)
当時のシリコングラフィックスでこのマイクロコード作成を担当していたのがエリック・リンドホルムです。
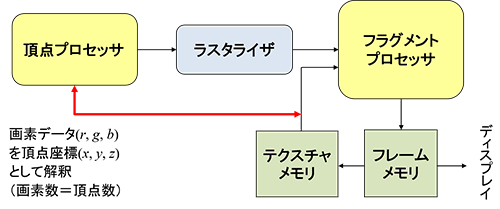
図5は、マイクロコード化を行う前にCPUプログラムで頂点処理をエミュレートした「シリンダーマッピング」という処理の結果です。
円筒状に線光源が配置された大きな部屋に、車の形状モデルを置いた場合の映り込みが頂点レベルで正確に計算できる機能で、頂点における反射方向を求め円筒内側との交点を求める計算を行います。
マッピング)は、MayaなどのCGソフトでも簡単に使えるようになっていますが、1997年当時のシリコングラフィックスのOnyx2 InfiniteRealityというハイエンドグラフィックス製品を使い、自動車会社の依頼を受けて作成されました。

マイクロコード化の予定であったが、実現することはなかった。
業界では90年代後半になると、PC用の3Dグラフィックスチップが開発されるようになりました。
1995年頃にはラスタライズとフラグメント処理を行うチップが市場に出て、1999年にはエヌビディア社(NVIDIA)が頂点プロセッサも載ったGeForce256を発売しました。固定機能パイプラインを1チップで処理するもので、GPUと呼べる最初のチップです。
残念ながらシリコングラフィックスは、ハイエンド製品にこだわり、1996年にスーパーコンピュータのクレイ・リサーチ社を買収したため、GPU開発の方向には進みませんでした。
その後シリコングラフィックスは、毎年のように赤字となり2000年代半ばには、2度に渡り会社更生法(Chapter 11)の適用を受けて倒産に至りました。
典型的な「イノベーションのジレンマ」による凋落です。
歴史に仮定は禁物ですが、1990年代半ばにクレイの代わりにエヌビディアを買収していれば、現在のAIブームに至ってもシリコングラフィックスがIT業界で活躍していた可能性が高いと思います。
さて、前述のリンドホルム氏は90年代後半、他の多くのシリコングラフィックスの優秀な技術者と同様にエヌビディアへ移籍しました(その後カート・エイクリーも同社に移籍)。
初期のGeForceシリーズでもリンドホルムはプロセッサのカスタマイズを担当していましたが、社内からのカスタマイズ要求は多く、その対応は多忙を極めたと推測されます。
リンドホルムは、ついにはいくつかの基本的な命令を処理する演算ユニットをそれぞれ用意し、それらを自由な順番で呼び出すためのアセンブラ命令体系を公開しました。
GPU処理のカスタマイズはアプリケーションのプログラマーが自由にやってくれということです。2001年に発表されたプログラマブル頂点シェーダーです[4] 。
同年、頂点シェーダー機能が搭載されたGeForce 3が発売され、ラスタライズ処理後の各画素での処理を行うフラグメントシェーダーもその後のGeForce 4で実現されました。
4. 汎用の並列計算チップへの発展
半導体チップの集積度向上により、2002年頃になるとマイクロプログラム制御で演算器を使いまわしする必要がないくらい多数の演算器をGPUに搭載できるようになりました。
機械語命令一つに対して演算器を複数つなげた専用回路(Wired Logic)が使用されるようになりました。RISC(Reduced Instruction Set Computer)方式です(図6)。
しかも一通りの命令セットに対応できる演算ユニットがさらに多数並列に同時計算を行います。基本的にはこれであとは集積度に応じて並列度を上げられるようになりました。
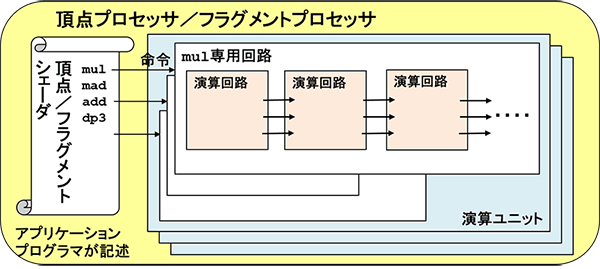
さらにGPUチップ外のフレームバッファとテクスチャメモリのアクセスについても改良が行われました。
2004年には、頂点プロセッサからテクスチャメモリに直接アクセスができるようになり、さらにはテクスチャメモリとフレームメモリが一体化して描画結果を転送なしでそのままテクスチャとして使用できるようになりました。
図7はこれらの変遷を示すブロック図です。
図7: GPUのプロセッサと画像メモリアクセスの変遷

2006年には、頂点シェーダーとフラグメントシェーダーで利用する演算ユニットを共通化するユニファイド・シェーダー(Unified Shader)が実現しました(図8)。
それまでは両シェーダーがそれぞれに演算ユニット群を持っていたため、処理負荷が偏るとグラフィックスパイプラインの流れ作業でいずれかが資源を遊ばせてしまう事態になっていました。
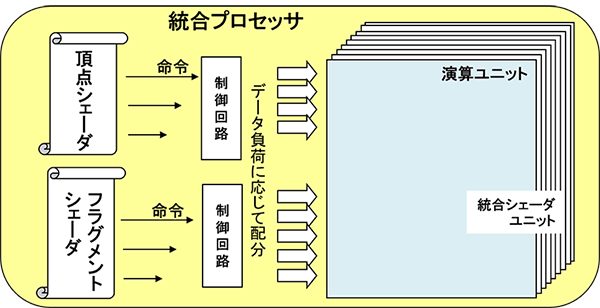
多数の演算ユニットを一つのグループとして共有することにより、負荷に応じて演算ユニットを再配分する負荷分散が実現されました。
前述の図2のグラフが2006年以降プロットされないのは、頂点処理性能が指標として適さなくなったためです。
頂点処理に最大性能を費やすことは、他の処理が演算ユニットを使えない結果になり、明らかに無意味な処理です。
ユニファイド・シェーダーによって、現在のGPUの基本形ができあがり、あとは演算ユニットの並列度を高め性能を上げていくという流れができました。また、その頃から頂点シェーダーとフラグメントシェーダー以外にもパイプラインの途中に各種シェーダーが加わることになりました。
新たな頂点を生成するジオメトリーシェーダーはその代表例で、2011年のShader Model 5.0では7種類のシェーダーが利用できるようになりました。
さらに、GPGPU(General Purpose GPU)の分野が、2000年代半ばから徐々に広がりました。
もともとGPUがプログラマブルになった2000年代前半から、グラフィックス以外の汎用の並列計算にGPUを利用しようというGPGPUの概念はあったのです。そのための開発環境であるCUDAもエヌビディア社によって提供され利用されていました。
GPGPUの需要に拍車をかけたのが、2010年代前半からのディープラーニングを中心とした人工知能のブームです。
ニューラルネットワークの演算である並列の積和演算は、GPUがもっとも得意とする処理です。
いまやエヌビディア社は人工知能銘柄の代表格になっています。
5. おわりに
本来この記事のシリーズは、GPUに関連する最新の研究や動向を紹介するものですが、今回はGPUの歴史的な側面を紹介しました。
読者がGPUの起源を知ることにより、将来何かのきっかけで役に立つことがあれば幸いです。
筆者がいつか記録として残したいと思っていた内容で、このような記事を書く機会を与えて下さった西田友是先生はじめGDEPソリューションズ株式会社の関係各位に感謝いたします。
【参考文献】
[1] Jim Clark, “The Geometry Engine: A VLSI Geometry System for Graphics,” Computer Graphics, Vol. 16, Issue. 3 (Proc. ACM SIGGRAPH 82), pp. 127-133, 1982.
[2] Kurt Akeley and Tom Jermoluk, “High Performance Polygon Rendering,” Computer Graphics, Vol. 22, Issue. 4 (Proc. ACM SIGGRAPH 88), pp. 239-246, 1988.
[4] Eric Lindholm, Mark J. Kilgard, and Henry Moreton, “A User-Programmable Vertex Engine,” Proc. ACM SIGGRAPH 2001, pp. 149-158, 2001.
著者紹介

柿本 正憲 先生
東京工科大学 教授
プロメテックCGリサーチ 研究員
東京大学工学部電子工学科卒業後、富士通研究所、グラフィカ、ノバ・トーカイ、日本シリコングラフィックス(現 日本SGI)、シリコンスタジオを経て現職。この間、東京大学大学院情報理工学系研究科電子情報学専攻博士課程修了、情報処理学会グラフィクスとCAD研究会幹事・可視化情報学会理事等を歴任。
所属:東京工科大学 メディア学部 メディア学科、大学院 メディアサイエンス専攻 / 教授、メディア学部長