RTX 5090×2 液冷AquSysで検証|AI画像・動画生成ベンチマーク
100V環境・静音・液冷運用を前提に、
RTX 5090×2構成のAI性能・GPU温度・実運用性を実機検証。
高性能GPUの導入では、性能だけでなく発熱・騒音・消費電力への対応も重要です。
今回、合同会社MetAI様にご協力いただき、弊社独自開発の液冷GPUワークステーション「AquSys」に、NVIDIA® GeForce RTX™ 5090を2基搭載した構成で、ComfyUIを用いたAIワークフローのベンチマーク検証を実施しました。
RTX 5090は最大600W級の高消費電力GPUですが、本検証では400W動作設定で運用しながら、画像編集、ControlNet、4K動画アップスケール、動画カラー化など、実運用を想定した複数のワークフローをテストしています。
また、高負荷時でもGPU温度は30〜40℃台で安定動作を維持しました。
液冷AquSysによる静音性・冷却性能についても検証を行いました。
高負荷時でも静音性が高く、オフィス環境での実運用にも対応可能なレベルであることが確認されています。
1. 検証環境
1-1. 検証機
今回の検証では、RTX 5090を2基搭載した液冷GPUワークステーション「AquSys」を使用しています。
AquSysシリーズは、NVIDIA H200 NVLなどデータセンター向けGPUなどの高性能GPUを静音・低温で運用できるよう設計した、GDEPソリューションズ独自開発の液冷GPUワークステーションです。


液冷 GeForce RTX 5090 ×2 搭載モデル
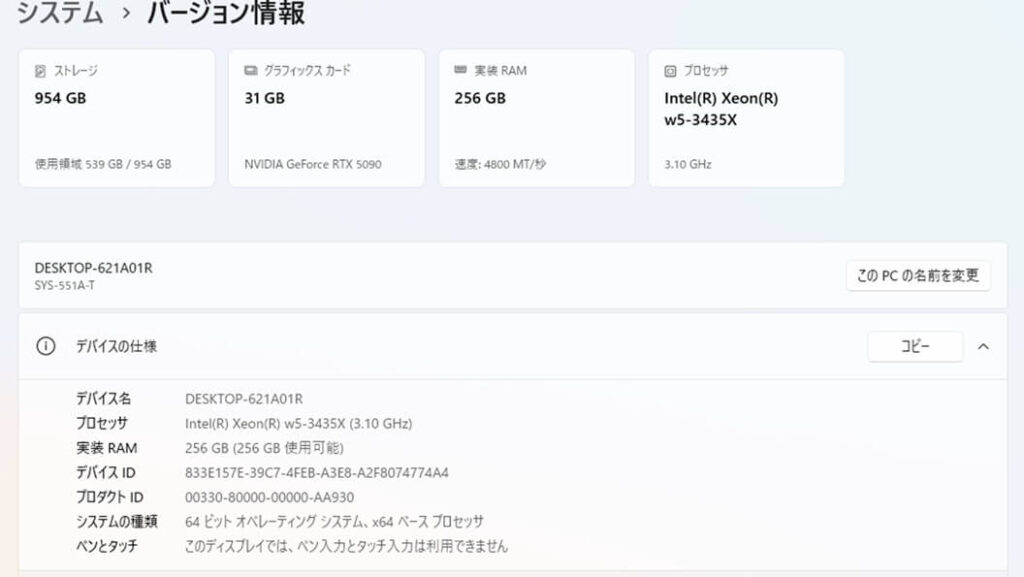
1-2. システム構成
今回の検証は、液冷GPUワークステーション「AquSys」に、NVIDIA GeForce RTX 5090 [GPUメモリ:32GB] を2基搭載したオールインワンタイプで実施しています。
CPUにはIntel Xeon w5-3435X、システムメモリは256GBを搭載しており、生成AIや動画処理など、高負荷なAIワークフローを想定した構成。
1-3. 電力設定
RTX 5090は非常に高い演算性能を持つ一方で、最大600W級の高消費電力GPUです。
今回の検証では、RTX 5090を400W動作設定で運用しています。
100V電源環境での運用を前提としながら、消費電力を抑えつつ、高いAI処理性能を維持できるかを検証しました。
以下のコマンドで制限を設定
nvidia-smi -pl 400
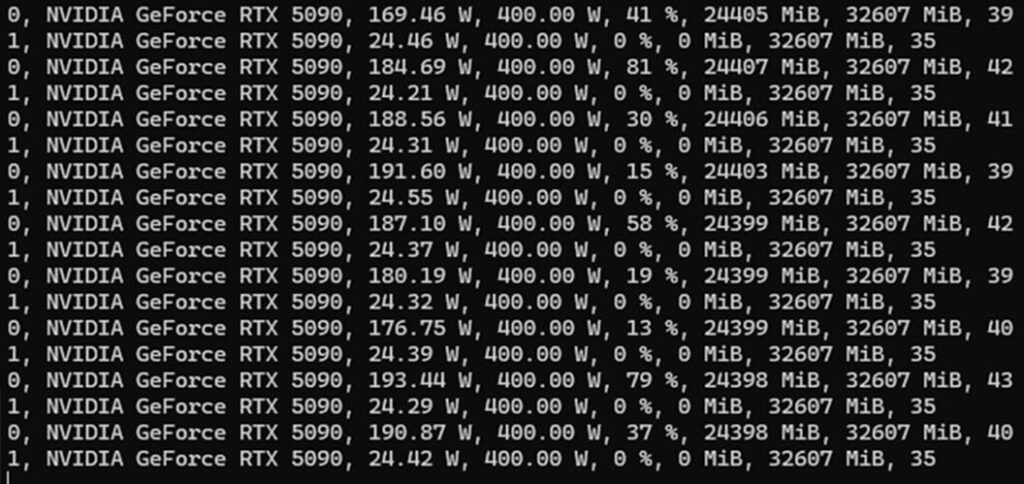
GPU状態のリアルタイム監視コマンド:
nvidia-smi --query-gpu=index,name,power.draw,power.limit,utilization.gpu,memory.used,memory.total,temperature.gpu --format=csv -l 1
1-4. GPU使用状況・温度監視
ComfyUI起動時のGPU使用状況を監視したところ、GPU温度は30〜40℃台で安定していることが確認されています。
また、高負荷なAIモデルを使用した場合でも、VRAMを安定して利用できており、液冷AquSysによる冷却性能と静音性の高さが確認されました。
ComfyUI未使用時(スタンバイ)の消費リソース:

ComfyUI起動時の消費リソース:
ComfyUIスタンバイ時(モデル生成なし)のCPU/RAM使用状況:

🔌 特別な電源工事は不要:100V環境で検証
液冷GPUワークステーション「AquSys」は、日本の一般的なオフィスや研究室で利用される100V電源環境での運用を前提に設計されています。
今回のRTX 5090×2構成による検証についても、すべて100V電源環境で実施しました。
RTX 5090は最大600W級の高消費電力GPUですが、本検証では2基搭載構成を400W動作設定で運用することで、100V環境でも安定動作を確認しています。
独自の液冷システム最適化により、大がかりな200V電源工事を行うことなく、デスクサイド環境でRTX 5090の高いAIパフォーマンスを静音・低温で運用できることを確認しました。
※ RTX 5090を1基搭載した構成では、600W設定での100V運用も可能です。
※ GPUの搭載基数や構成によっては200V電源が必要となる場合があります。詳細はお問い合わせください。
▶ AquSys 詳細はこちら
2. ComfyUI デュアルGPU検証
今回の検証では、RTX 5090を2基搭載したデュアルGPU環境において、ComfyUIのマルチGPU活用についても検証を行いました。
ComfyUI-MultiGPUノードを使用し、CUDA 0とCUDA 1を同一ワークフロー内で切り替えながら、2基のGPUを同時利用できる構成を試しています。

2-1. 試行した設定
マルチGPU構成の検証では、複数のノード構成やCUDA環境を組み合わせて動作確認を行いました。
✅ ComfyUI-MultiGPU インストール
❌ UnetLoaderGGUFAdvancedMultiGPU + Qwen GGUFノード
→ クラッシュを確認
❌ UNETLoaderDisTorch2MultiGPU + Qwen fp8mixedノード
→ CUDA 13環境でクラッシュを確認
✅ DDU + Driver 595.79 再インストール
→ nvidia-smi上で2GPU認識を確認
✅ PyTorch nightly cu130 インストール
✅ UNETLoaderDisTorch2MultiGPU + Flux Klein 9B
→ クラッシュなし
(ただしGPU 1は0%稼働。モデルが32GB以内に収まるため)
2-2. 現状の結論
| 検証結果 | |
|---|---|
| GPU認識 | ✅ 2基のGPUを正常認識 |
| DisTorch / ONNX | ❌ CUDA 13.2 / RTX 5090環境への対応は未完了 |
| GPU 1活用条件 | 32GBを超えるモデル(HunyuanVideo / Wan 2.1等)が必要 |
| 対応状況 | 最新GPU向けノード・モデルへの対応は進行中 |
2-3. 解決案
別ポートで2インスタンスを同時起動(推奨)
通常のAIコンテンツ生成では、1つのコンテンツを生成してから次の生成処理を行う逐次処理となるため、生成待機時間が発生します。
一方、2ポート構成でComfyUIを別々に起動することで、2つのコンテンツを同時並行で生成しながら作業を進めることが可能になります。
2ポート構成の起動例:
python main.py --cuda-device 0 --port 8188
python main.py --cuda-device 1 --port 8189

2-4. 2ポート同時起動による並列生成
今回計測したベンチマーク結果から、RTX 5090では各タスクを高速に処理できることが確認されました。
さらに、2ポート構成を活用することで、それぞれのポートの処理時間へ影響を与えることなく、複数のAI処理を同時並行で実行できます。
例えば、
- 画像生成 × 動画生成
- 画像生成 × 画像生成(2パターン同時)
- 動画生成 × 動画生成(2本同時)
- 画像生成 × 3Dモデル生成
など、複数のコンテンツ生成を同時に進めることが可能です。
これにより、生成待機時間を削減し、制作全体の効率向上につながります。
2-5. コスト・効率比較
RTX 5090を2基搭載したAquSysでは、1台のワークステーション上で複数のAI処理を同時に実行できます。
今回の検証では、2GPU搭載構成を活用することで、生成待機時間を削減しながら、制作全体の効率向上につながることが確認できました。
| 導入メリット | |
|---|---|
| コスト | PCを2台用意する必要がなく、設置スペースと導入コストを削減 |
| 作業効率 | 生成待ち時間を減らし、制作作業を効率化 |
| 人件費 | 待機時間を削減し、他の作業へ時間を有効活用 |
| 運用管理 | 1台で管理できるため、設置・運用負荷を軽減 |
3. AI画像生成ベンチマーク
3-1. 2Dイラスト → ラインアート化
2Dイラスト画像からラインアートを自動抽出するワークフローのパフォーマンス検証。
軽量な画像変換処理では非常に高速なレスポンスを確認しており、2回目以降の処理では約0.8秒で処理を完了しています。
また、GPU温度は31℃前後に安定しており、長時間利用時でも高い冷却性能が確認されています。

| 初回処理(Cold Start) | 5秒 |
| 2回目以降(Warm) | 0.8秒 |
| GPU使用率(ピーク) | 約0% |
| VRAM使用率 | 約7% |
| GPU温度(ピーク) | 31℃ |
3-2. Upscale 20x(1456×816 → 29,586×16,581)
超解像AIによる画像アップスケール処理を検証。
1456×816の画像を約20倍へアップスケールし、放送・印刷用途にも対応可能な高解像度出力を生成。
高解像度処理においても、GPU温度は34℃に安定しており、高負荷時でも安定した動作が確認されました。

| 初回処理(Cold Start) | 339.69秒 |
| 2回目以降(Warm) | 85秒 |
| GPU使用率(ピーク) | 約25% |
| VRAM使用率 | 約21% |
| GPU温度(ピーク) | 34℃ |
3-3. 画像編集 AI
AIモデルを用いた画像編集ワークフローを検証。
背景変更やライティング変更など、高負荷な画像編集処理においても、2回目以降の処理では約31秒で完了しています。
検証では、
- オブジェクト削除
- ライティング変更
- 背景調整
などを実施。
GPU温度は33℃前後に抑えられており、高負荷時でも液冷AquSysによる安定した冷却性能が確認されています。
テスト1:リボンを削除

| 初回処理(Cold Start) | 58.73秒 |
| 2回目以降(Warm) | 31.06秒 |
| GPU使用率(ピーク) | 約11% |
| VRAM使用率 | 約21% |
| GPU温度(ピーク) | 33℃ |
テスト2:ライトシーンと照明を変更

3-4. ポーズ・カメラ変更
キャラクターのポーズやカメラアングルをAIで自動変換するワークフローを検証。
2回目以降では約7.25秒、3回目では約5.63秒で処理を完了しており、高速な生成性能が確認されています。
また、本テストではGPU使用率が約100%、VRAM使用率も約94%まで使用されましたが、GPU温度は42℃に安定していました。
高負荷なAI処理においても、液冷AquSysによる冷却性能と安定性が確認されています。
| 初回処理(Cold Start) | 27.27秒 |
| 2回目以降(Warm) | 7.25秒 |
| 3回目 | 5.63秒 |
| CPU使用率 | 約21% |
| RAM使用率 | 約17% |
| GPU使用率(ピーク) | 約100% |
| VRAM使用率 | 約94% |
| GPU温度(ピーク) | 42℃ |


3-5. ControlNet ポーズ変更
ControlNetを使用したポーズ変更ワークフローを検証。
スケルトンエディターやポーズライブラリを活用することで、キャラクターのポーズやライティングを柔軟に制御できます。
本検証では、
- キャラクター姿勢変更
- ライティング調整
- スタイル変更
などを実施。
| 初回処理(Cold Start) | 417.74秒 |
| 2回目以降(Warm) | 370.07秒 |
| CPU使用率 | 約14% |
| RAM使用率 | 約11% |
| GPU使用率(ピーク) | 約87% |
| VRAM使用率 | 約84% |
| GPU温度(ピーク) | 47°C |
GPU使用率は約87%、VRAM使用率は約84%を使用しましたが、GPU温度は47℃に抑えられています。
※ 本テストでは、一部モデルで処理時間増加が発生しましたが、軽量モデルへ切り替えることで改善が確認されています。
4. 動画AI生成テスト
4-1. 480P → 4K 動画アップスケール(15秒動画)
15秒の動画を480Pからネイティブ4Kへアップスケールするワークフローを検証。
高負荷な動画処理でありながら、RTX 5090では約165秒で処理を完了しています。
検証時はGPU使用率約99%まで到達しましたが、GPU温度は37℃に安定していました。
動画アップスケールのような高負荷ワークフローにおいても、液冷AquSysによる安定した運用が確認されています。
| 初回処理(Cold Start) | 165.18秒 |
| 2回目以降(Warm) | 168.89秒 |
| CPU使用率 | 約52% |
| RAM使用率 | 約7% |
| GPU使用率(ピーク) | 約99% |
| VRAM使用率 | 約20% |
| GPU温度(ピーク) | 37°C |

🎬 動画サンプル: https://drive.google.com/file/d/1eCEspUR0MdcMjXiJkRo8Ki-wKBTmRbxe/view?usp=sharing
4-2. 白黒動画のカラー化(17秒動画)
17秒の白黒動画を自動カラー化するワークフローを検証。
本検証では、約58秒で処理を完了しており、放送・映像アーカイブ用途でも実用的な性能が確認されています。
GPU温度は43℃前後に安定しており、高負荷時でも安定した動作を維持しました。
ドキュメンタリー映像や報道アーカイブなど、映像復元ワークフローへの活用も期待できます。
| 初回処理(Cold Start) | 58.81秒 |
| 2回目以降(Warm) | 75.61秒 |
| CPU使用率 | 約54% |
| RAM使用率 | 約7% |
| GPU使用率(ピーク) | 約55% |
| VRAM使用率 | 約21% |
| GPU温度(ピーク) | 43°C |

🎬 動画サンプル: https://drive.google.com/file/d/1ErBJIGJ1eC9IIkKIBDOpZ3XzxcoYba-d/view?usp=sharing
5. まとめ
今回の検証を通じて、RTX 5090を2基搭載した液冷GPUワークステーション「AquSys」が、AIワークフローにおいて、高い実用性能を持つことが確認されました。
単一GPU構成の時点でも、4K動画アップスケール、画像編集、ControlNetなど、多様なAIワークフローで高いパフォーマンスを発揮しています。
さらに、2GPU環境で2ポート同時起動による並列生成を活用することで、1台のワークステーション上で複数のコンテンツを同時生成でき、制作全体の効率向上につながることが確認されました。

また、RTX 5090のような高発熱GPUを2基搭載しながらも、400W動作設定でも高いAI処理性能を維持しつつ、液冷システムによりGPU温度は30〜40℃台で安定。
高負荷時でも熱風や騒音を抑えた快適な運用が可能であり、オフィス環境での実用性の高さも確認されています。
デュアルGPUの完全な統合(DisTorch / ONNX)については、CUDA 13.2対応待ちの状況ではあるものの、エコシステム側の対応は進行しており、今後さらに高度なマルチGPU活用が期待されます。
現時点においても、RTX 5090 ×2GPU構成は、
- RTX 5090を400W制限で安定運用
- 高負荷時でも30〜40℃台を維持
- デュアルGPUによる並列生成
- 高い静音性
- 熱風を抑えた快適な運用環境
- 省スペースかつ高効率な運用
を高いレベルで両立できる構成であり、ローカルAI・生成AI環境を構築するうえで、有力な選択肢のひとつと言えます。
GDEPソリューションズでは、用途に応じたGPU構成や、生成AI向けワークステーションの選定支援も行っています。
ローカルAI・生成AI環境の導入をご検討中の方は、お気軽にご相談ください。
※ 本記事は、合同会社MetAI様による検証結果をもとに構成しています。
※ ベンチマーク結果は、使用モデル・ソフトウェア構成・ワークフローによって変動します。

