深層学習を利用した画像処理・画像認識と必要なGPU性能

深層学習を利用した画像処理・
必要なGPU性能
石川 知一 先生
東洋大学 准教授
1. はじめに
ご存じの通り、深層学習(Deep Learning)は様々な分野に応用されています。
この技術発展はGPUの性能向上と共にあります。
本稿では画像処理、画像認識の分野において、最新の研究ではどのようなことを実現できるかと、実際に学習を行うために必要なGPUの性能についてまとめていきます。
学習フェーズでどの程度の時間を要するのか、どの程度のデータを学習に用いているのか、実験を行うために最低限必要なスペックの参考にして頂けると幸いです。
2. リフォーカス
一般にリフォーカス技術は、撮影後に写真の焦点を変更することを指します。
現在、スマートフォンに搭載されているリフォーカス技術は、スマートフォンに搭載されている2つ以上のカメラを使用して撮影された複数上の画像から距離画像を推定し、焦点を変更する方法(ステレオマッチング)か、距離センサーを利用して深度情報も撮影時に同時に取得する方法が一般的です。
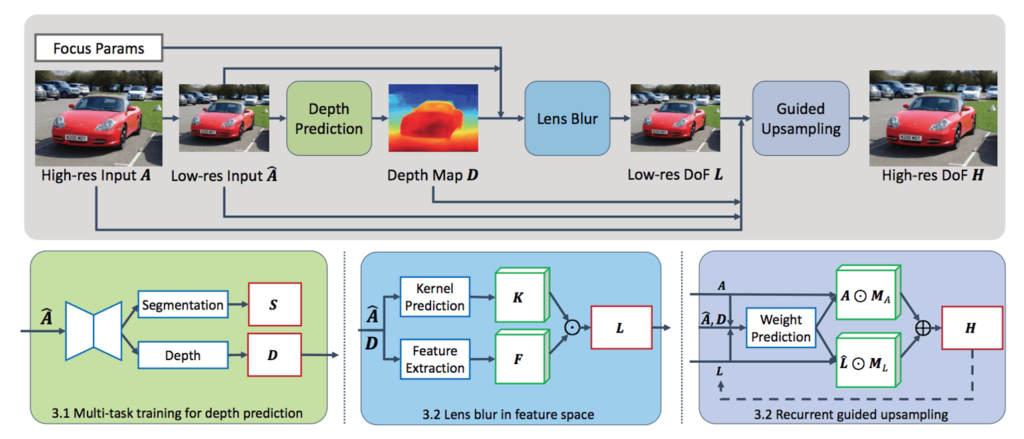
ここで紹介するリフォーカスは、深層学習を用いて1枚の画像から焦点位置を変更する技術 DeepLens です[1]。(論文タイトルで命名されていた技術名で,AWS DeepLensとは別の技術です)
概要を図1に示します。
学習用にはデュアルレンズカメラで収集したRGB-D データセットを用い、畳み込みニューラルネットワーク(Convolutional Neural Network のことで以下、CNN)で深度マップを推定し、アーティファクトのない合成データセットでトレーニングされたニューラルネットワークを使用し、アーティファクトの少ない結果を生成します。
深度予測モジュールは図1に示すように全焦点入 から低解像度の深度マップD を予測します。D,とフォーカスパラメータは、低解像度の浅い被写界深度画像 L を生成するために用いられ、これは最終的に高解像度出力 H にアップサンプリングされます。
深度予測モジュールでは を受け取り、深度 D とセグメンテーション S マップを共同で予測しています。レンズブラーモジュールは空間的に変化するカーネル K を計算し、これを縮小された次元の特徴マップ F に適用して L を生成します。
ガイドアップサンプリングモジュールは被写界深度画像を元の解像度に達するまで2倍の繰り返し超解像を行います。
このアプローチは学習フェーズで時間はかかりますが、学習後のネットワークを利用して画像処理を行う過程では計算時間がかからないため、既存のアルゴリズム[2]よりも高速に(リアルタイムに)出力を確認できます。
著者らのプロジェクトサイトによると、学習もCUDAを使用できるGPUであることが要件になっているくらいで、機械学習を行う準備ができていれば問題なく動作確認できると思います。
私の研究室では NVIDIA GeForce GTX 1050Tiでも動作可能であることを確認しています。

DeepLensの技術を用いてリフォーカスした結果を図2に示します。
その他の結果例はこちらのYouTubeから確認できます。
最初の方にはインタラクティブなデモの様子があります。推定された奥行き情報や,マウスクリックした場所にフォーカスを合わせることができるツールは実用性を感じます。
3. デブラー
デブラー技術とは、画像上のボケを取り除くことです。
ここでは焦点ボケではなく、露光時間に対して物体の速度が速いためにボケが発生するモーションブラーを取り上げます。
昔から研究されているコンピュテーショナルフォトグラフィ(レンズに入射する光線から,光学系と画像処理の2段階の情報処理を介して所望の画像をつくる技術)では、カメラの可変露光を利用してモーションブラーを除去します。
最新の深層学習では、事前にブラーを含んだ画像と、ブラーの無い画像のセットを用意し、CGAN(Conditional Generative Adversarial Network:条件付き敵対的生成ネットワーク)の技術を利用することで、1枚の写真からでもデブラーを施す方法が提案されています。(GANについては金森先生のコラムで詳しく説明されています)

OrsetらのDeblur GAN [3]のネットワーク構造を図3に示します。
この場合のジェネレーターはシャープな画像を再現することを目的としています。ネットワークはResNetブロック[4]に基づいています。ディスクリミネーターの目的は入力画像が人為的に作られたものかどうかを判断することです。
損失は2種類で、1つ目は知覚損失です。
知覚損失によりGANモデルがブラー除去タスクに向けられます。
2つ目はワッサースタイン損失です。ワッサースタイン損失は2つの画像の差の平均を取ります。損失関数はコンテンツ損失と敵対的損失の組み合わせとして定式化されています。
実装については、こちらのサイトで詳しく解説されています。
Orsetらの論文によると、学習では NVIDIA GeForce GTX Titan-X (Maxwell) 1枚を使用して行っていましたが、私の研究室ではAMD Radeon 540Xで学習させたところ、10エポックの学習でも約1.5日かかりました。
学習時の条件にもよりますが、より高性能なGPUを使用すると、この時間は短縮できそうです。
デブラーの結果を図4に示します。
ブラーがかかっている場所がより鮮明になっていることが見て取れると思います。アーティファクトが残ることは問題で、図4では全体に規則的に格子状の模様が入っているように見えます。右上の空の部分に顕著に見られると思います。

著者らはこの研究を発展させて、DeblurGAN-v2を発表しています[5]。
計算がより速く、結果がより良くなっており、このときの学習には NVIDIA Tesla P100 を使っています。
この精度向上は、ジェネレーターにFPN(Feature Pyramid Network)を導入したことによると論文中では述べられています。
4. 画像認識
ここでは画像認識の中でも深層学習の導入が盛んな画像分類タスクについて紹介します。
画像分類タスクは、画像に写っている物体が「ネコ」、「飛行機」、「鳥」など事前に定義されたラベルのうちどれに適するかを識別する問題のことです。
自然言語処理の分野でTransformerが注目されてから程なくして、画像分類タスクにTransformerを適用しようという流れがあり、ViT(Vision Transformer)という技術が登場しました。(Transformerについては北岡さんのコラムで詳しく説明されています)
Dosovitskiy らによって提案されたViTは、画像を平坦なパッチに分解し、それらのパッチを線形に埋め込むシーケンスをTransformer に入力値として与え、画像分類ではトークンの出力をMLP(Multilayer perceptron) に入力することで最終的な予測を行うモデルでした[6]。
しかし、ViT は Imagenet-1k [7] のデータセットで良好な結果を得るために、より大規模なJFT-300M [8] のデータセットで事前に学習する必要があるという課題がありました。
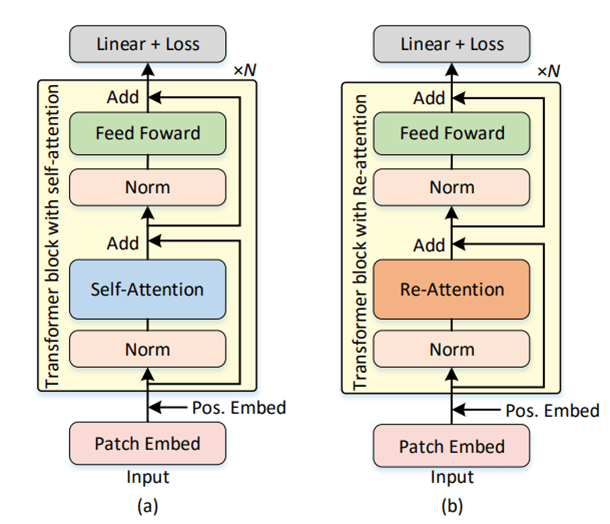
Zhou らはViTのネットワークの深さが増すにつれViTの性能が飽和することを発見し、最小の計算量とメモリで解決するための再注意層(Re-Attention)を提案しました[9]。
Re-Attentionは、式で示すと次のようになります。
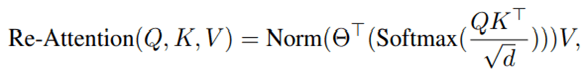
Q,K,VはそれぞれTransformerのquery,key,valueを表し,Θは学習可能なヘッド数×ヘッド数の変換行列を新たに定義してVと乗算しています。
この効果は、異なるヘッド間の相互作用を利用して、attention mapの多様性を向上させることです。この概要図を図5に示します。
32層のViTモデルのMHSAをRe-Attentionに置き換えることで、精度が1.6%向上したと報告しています。
この研究では、8枚のNVIDIA Telsa V100を用いて学習を行っています。
バッチサイズを256として、Transformerの層を32層重ねる実験ではGPU側へのデータ転送も膨大になるため、私の研究室にあるようなデスクトップPCに搭載できるGPUの範囲では再現実験することは難しかったです。
5. 物体追跡
物体追跡タスクは、与えられた動画像から指定した対象がどのように移動するかを推定する問題のことです。
物体追跡タスクの応用例として、動画内の移動物体に対してのオートフォーカスや、動画像内の追跡対象物に対してバウンディングボックスで強調表示をする編集を行うことで、スポーツのリプレイ映像で選手を強調表示させられることができます。
古典的な(深層学習の応用以前は)物体追跡タスク手法で代表的な技術はテンプレートマッチング、アクティブ探索、MeanShift法を利用したもの、Particle Filter、オプティカルフロー、背景差分法が提案されていました。
しかし、人物の重なりが頻繁に発生する動画像や細かい形の違いが重要になるような動画像に対してうまく追跡を行うことができないという課題が残されていました。
2021年にZhao らは物体追跡タスクにTransformer を適用したTracker with Transformer(以下、TrTr と略す)を提案しました[10]。
図6はTrTrの概要図です。
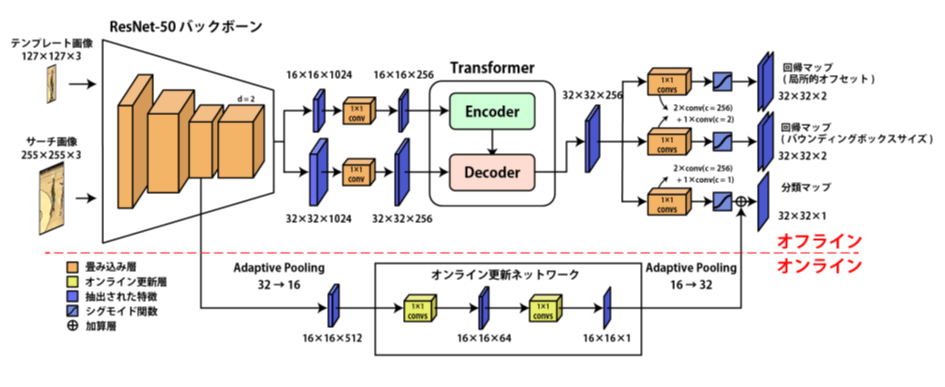
TrTr の構造は主にオフラインで追跡を行うオフライントラッキング部(図6の上部)とオンラインで分類モデルを更新するオンライン更新部(図6の下部)から構成されています。
オフライン部には、特徴抽出構造・Transformer 構造・物体の位置特定を行うヘッドで構成されています。
TrTr ではテンプレート画像とサーチ画像の2 つの画像を入力としています。
テンプレート画像は入力動画の最初のフレームの中から追跡対象となる物体を中心とした画像パッチを表します。サーチ画像はテンプレート画像よりも画像サイズが大きく、入力動画の後続のフレームにおける探索領域を表しています。サーチ画像とテンプレート画像の特徴抽出には、改良されたResNet-50 バックボーンが利用されています。
TrTr で利用されているTransformer はテンプレート画像の特徴を持つエンコーダとサーチ画像の特徴を持つデコーダの2 つで構成されています。またTrTr で利用されているTransformer のモデルではオリジナルのTransformerとは異なり1 つの層で学習を行っています。
TrTrで使用しているGPUは論文中に記載が無かったため著者に尋ねたところ、8枚のNVIDIA GeForce RTX 3090を用いて学習しているとのことでした。
学習の時間はオンラインもオフラインも20epochで、10時間程度かかるそうです。
TrTrもバッチサイズによってGPUの容量で制限がかかったのですが、私の研究室では2枚のNVIDIA Quadro RTX 4000を利用して学習を行うことができました。この環境だと学習には18時間を要しました。
6. おわりに
いかがでしたでしょうか。(まとめサイト風)
深層学習を利用した画像処理・画像認識の研究と、それぞれに使用されたGPUについて紹介してきました。
紹介したGPUの性能(メモリとFLOPS(FLoating-point Operations Per Second))について図7にまとめます。
FLOPSは単精度浮動小数点数でテラ単位です。
紹介したGPUのメモリとTFLOPS(単精度)
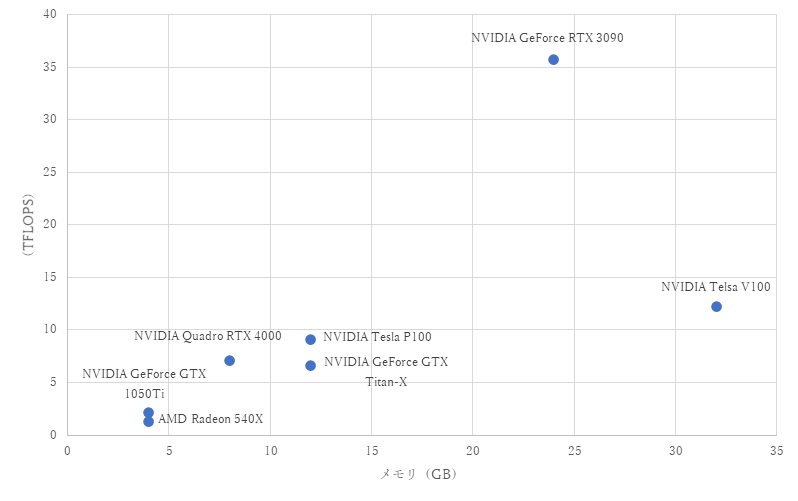
画像のデータセットの容量は、自然言語や音声と比べても大きいため、よりハイスペックなGPUが必要となります。
特に、層を重ねると精度が上がると言われているTransformerや、物体追跡タスクのような動画を使用する研究では、GPUを何枚も接続することが通例となっています。
深層学習の最新研究はソースコードも公開されていることが多いのですが、実験を行う場合は、GPU性能を確認してから計画的に行うことをお勧めします。
著者紹介

石川 知一 氏
東洋大学 准教授
2012年3月東京大学新領域創成科学研究科複雑理工学専攻博士課程修了. 博士(科学).
同年4月より東京工科大学メディア学部助教,その後,東京理科大学理工学部助教を経て,現職の東洋大学情報連携学部(INIAD)の准教授.
画像処理を含むコンピュータグラフィックス(CG)およびコンピュータビジョン(CV)に関する研究に興味がある.
特に,数値シミュレーションを利用した物理アニメーションの研究に取り組んでいる.
情報処理学会, 画像電子学会, ACM各会員.

