トランスフォーマー 最近流行のニューラルネットワーク

トランスフォーマー
最近流行のニューラルネットワーク
北岡 伸也 氏
Dwango Media Village
1. はじめに
ディープラーニングと聞いて、どのような仕組みを思い浮かべるでしょうか。
「なにかすごい仕組みで動いて、何でも解決してくれる万能ツール」という認識の方もいるかも知れません。あるいはもう少し詳しく、「ニューラルネットワークで構成されていて、多層パーセプトロン(MLP; Multi-Layer Perceptron)や畳み込み(Convolution)が、使われている」とご存じかも知れません。
計算に大変なリソースが必要でGPUが利用されていることはよく知られていると思います。
本稿では、どういう場面でどのようなニューラルネットワークのアーキテクチャーが使われるかはなんとなく知っているけど、実際に使ったり実装してみたりしたことはないといった方を対象として、では実際にそれはどのような仕組みで計算されているのかについてトランスフォーマー(Transformer)を題材として解説します。
2. なぜトランスフォーマーか
トランスフォーマーは、2017年に“Attention is All you Need”という題目の論文で提案された翻訳を行うためのニューラルネットワークの仕組みです[1]。
その特徴は、系列情報(文章は文字が並んだ系列データです)を扱うために、それまでよく用いられていたLSTM (Long Short Term Memory)やGRU (Gated Recurrent Unit)などのRNN (Recurrent Neural Network)に基づく手法とは異なり、注意機構(Attention)という仕組みを中心に構成されていることです。
そして現在では、最初に提案された分野である言語処理の枠を超えて、系列情報を扱う他の分野である音声処理(音声合成や音声認識)に使われるのみならず、物体検知や物体認識などの画像処理・動画像処理分野にも広く応用されるようになっています[2]。
このように現在のニューラルネットワークを語る上で避けては通れない仕組みのひとつですので、そのアーキテクチャーにぜひ詳しくなってしまいましょう。
3. トランスフォーマー概観
ではさっそくトランスフォーマーの構成を見てみましょう。
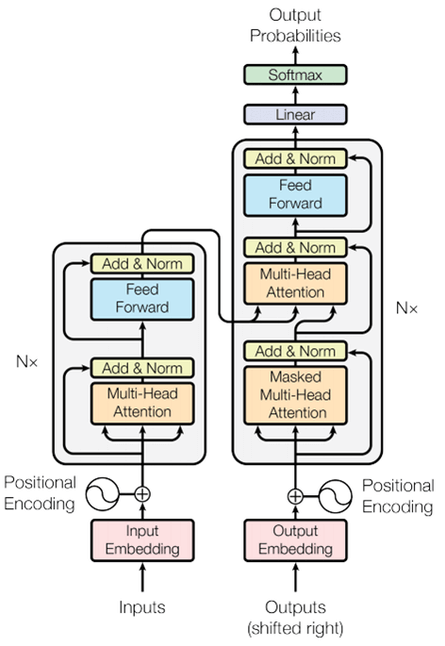
図1は原論文に記載されている全体像を表す図です。
一見として複雑な構成に見えますが、構成要素を一つ一つ分解していくとそれほど難しくはありませんので、順に何をやっているか確認していきましょう。
英語から日本語への翻訳を題材として考えてみます。
トランスフォーマーの左側下部のInputs(入力)にはEncoderへ日本語の文章が入力されることになります。
また、右側下部のOutputs(出力)には、それまでに出力した英語の文章がDecoderに入力として与えられます。
そして右側上部のOutputs Probabilities(出力確率)に、入力とした英語の文章の続きになりそうな英単語の確率が出力されます。
これが翻訳処理の1ステップになります。
出力された英単語を最後に加えた英文をあらたなOutputsへの入力とすることで、文の最後にたどり着くまで順々に文章を作っていくという処理の流れになります。
図2に構成要素をならべてみました。
主要な構成要素はEmbedding (埋め込み)・Encoder (エンコーダー)・Decoder (デコーダー)・Linear (全結合層)の4つです。
デコーダーは、中央にエンコーダーからの入力を受け取っている以外はエンコーダーと同じ構造です。
そのため以降ではEmbedding・Encoder (Decoder)・Linearの3つについて順にみていきましょう。

4. 文章を表現するEmbedding
Embeddingは自然言語の文章をニューラルネットワークで扱えるようにするための変換部分に当たります。

図 3 Embedding:まず単語に対してID(整数値)を割り当てます。
すべての処理はこの単語を基準として行うことになります。
図中では単語に仮に番号をふっていますが、これをすべての単語(おおよそ32,000ぐらいの語彙数になります)について行っています。
そして、それぞれのIDについて対応するd次元のベクトルを用意します。それぞれのベクトルはランダムに初期化されておりニューラルネットワークを学習させるとき、同じように更新していくことになるパラメーターとなります。このようにして自然言語をコンピューターで扱える数値の形として表現しています。
上記のように単語を表現することにすると、その単語が文中のどの位置に現れたのかという情報を表現できていません。
そこでその欠けた情報を加えるためにPositional Embedding (位置埋め込み)を用います。
ここで、iはそれが文の何番目の単語かに対応しており、またkはその単語を表すベクトルの何次元目かに対応しています。
dは単語ベクトルの次元数です。この一埋め込みによるベクトル同士について内積計算をとると、位置iが遠いほど小さい値になり、近いほど大きい値になります。
これを単語ベクトルに加算することで位置情報を表現できるベクトルを構成しています。
5. 注意こそはすべて Encoder(Decoder)
トランスフォーマーは、注意機構で構成されることが特徴です。注意機構は、時系列的に並んでいる単語のベクトルを混ぜ合わせる役割を担っています。
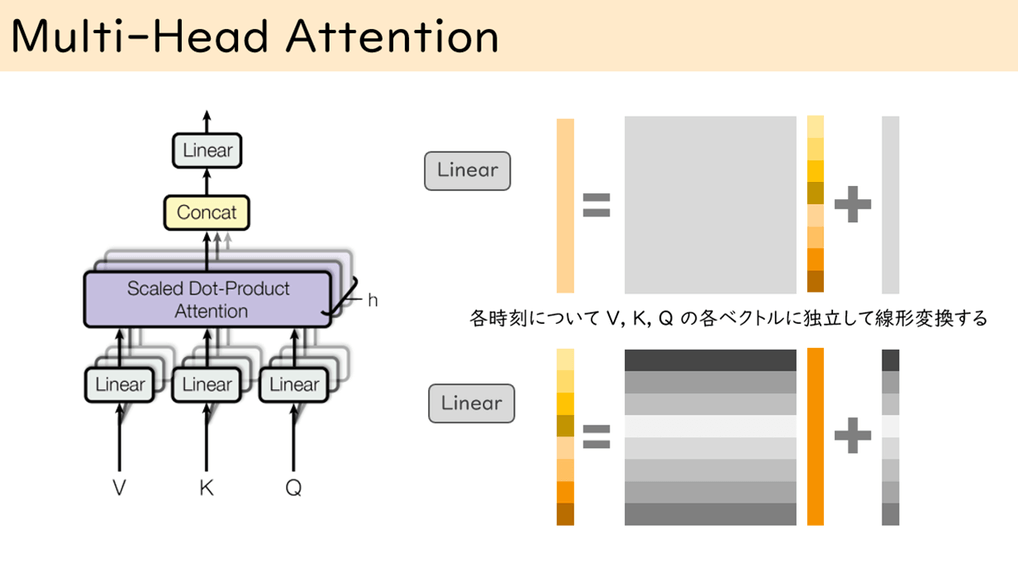
図 4 トランスフォーマーの注意機構はMulti-Head Attention(多頭注意)で構成されています。
これは複数のScaled Dot-Product Attention(縮小付き内積注意)によって構成されています。
エンコーダーで利用される際には入力になるVとKとQはまったく同じベクトルになっています。デコーダーで、エンコーダーの入力をとる部分では、KとVがエンコーダーからの入力になり、Qがデコーダーからの入力になっているだけです。
縮小付き内積注意の前後にはLinear(全結合層)を追加しています。これは入力ベクトルに行列を掛けて、ベクトルを足しているだけです。
図中の右上が出力部分、右下側が入力部分のLinearを表しています。灰色の長方形はいずれもニューラルネットワークで学習されるパラメーターを示しています。
さて、なぜ多頭というかというと、入力のLinearのあとのベクトルを固定の次元ごとに小分割して、それぞれについて縮小付き内積注意を適用するためです。
そして、それぞれの内積注意から得られたベクトルをConcat(ならべてひとつの大きなベクトルとして扱う)したあと、Linearを適用して出力としています。
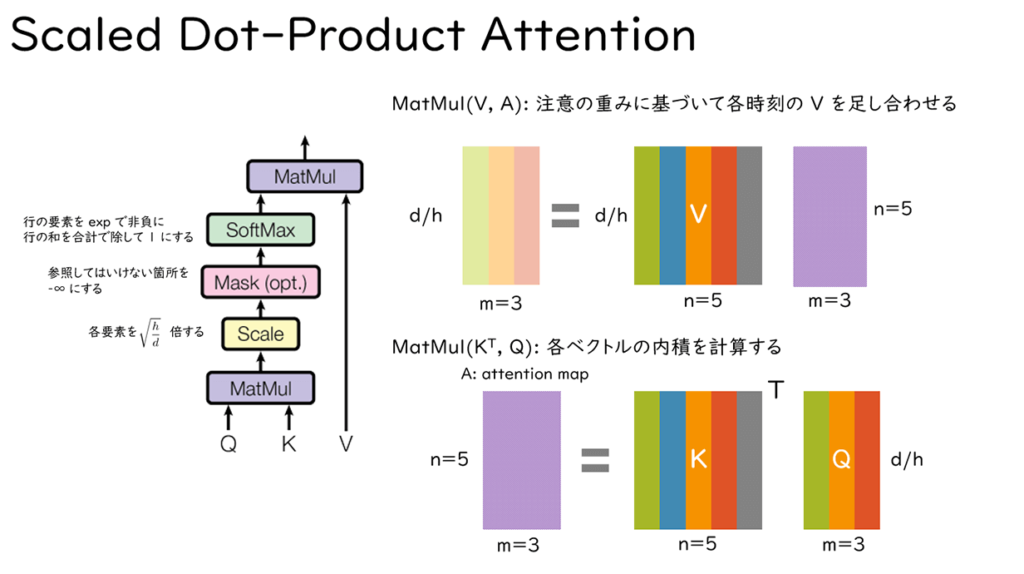
図 5 縮小付き内積注意ではKとQを掛けてA(Attention Map)を作ることから始まります。
Kはd行n列の実数行列、Qはd行m列の実数ベクトルですので、Aはn行m列の行列になります。
Aの各要素は、KとQの列ベクトルの内積結果となっていることから内積注意と呼ばれます。また、これをsqrt(h/d)倍することから縮小付きと呼ばれています(hは多頭の頭数です)。
つぎに、Aのそれぞれの列ベクトルを非負かつ和が1になるように、Softmaxによって正規化します。詳しい計算方法は後述します。
最後にVとAを掛けてd行m列の行列を出力として得ます。
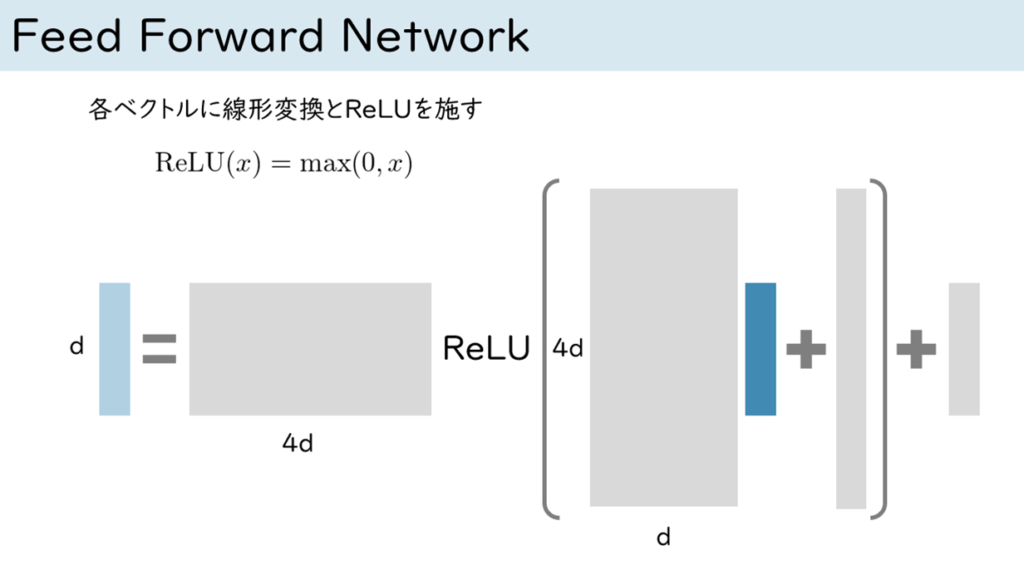
図 6 エンコーダーブロックの後半に配置されているFeed Forward Networkは単純なMLPになっています。
濃い青色のベクトルを入力として、全結合層による2回の変換の間にReLUユニット(0以下の値を0とするランプ関数)を挟んでいるだけです。
図中の灰色の長方形はパラメーターで、ネットワークの学習によって更新される部分です。
これを入力された単語ベクトルそれぞれについて独立に計算しています。
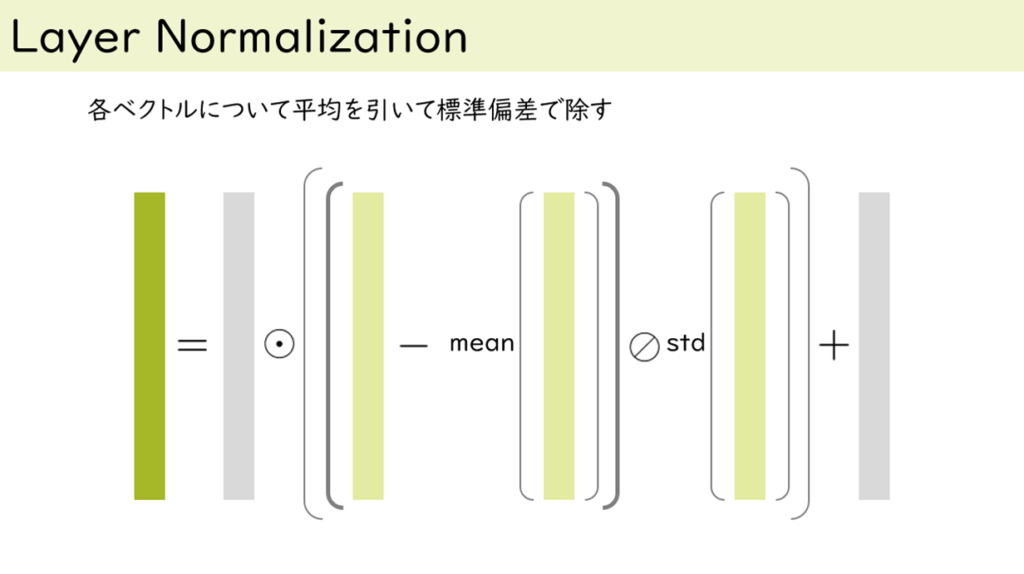
図 7 Add & Normは注意機構とFFNの両方に付いているユニットです:Addは単なる加算です。
それぞれのブロックへの入力と出力を加算しています。トランスフォーマーのNormはLayer Normalizationで構成されています。
これはベクトルの要素の値域をある程度制限役割を担っています。やっていることとしては単純で、ベクトル要素の平均を引いてその標準で除しているだけです。
図中の灰色はネットワークのパラメーターで、要素毎に値をスケーリングとシフトするために要素積と加算がされています。
6. 全結合層 Linear
全結合層は、ここまで変換されてきた入力から各単語の選ばれる確率を算出する処理になります。
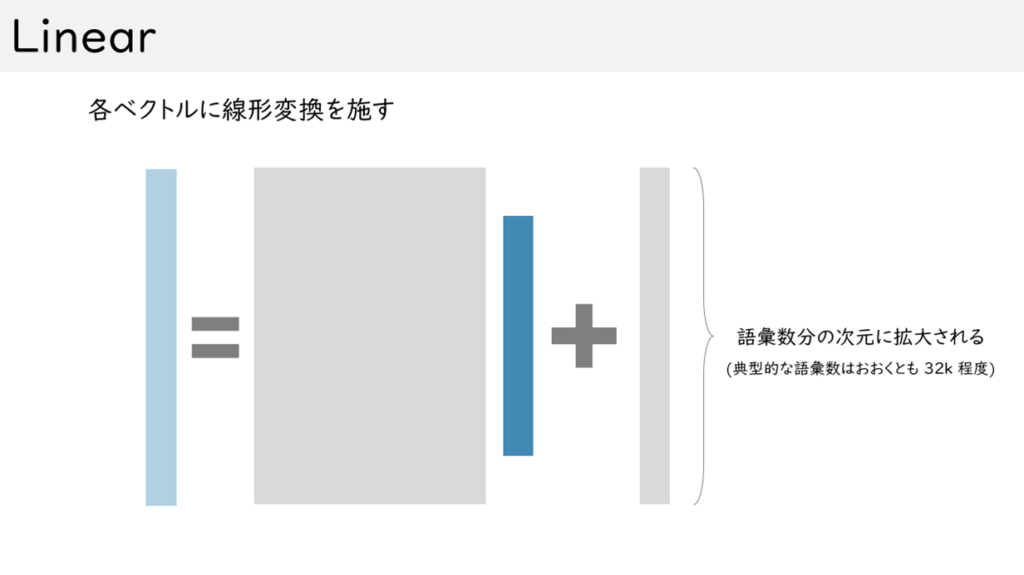
図 8 全結合層:濃い青色が入力の単語に対応するベクトルを表しています。
灰色の長方形が、そのベクトルを変換するための行列(太い方)とベクトル(細い方)です。
薄い青色が出力ベクトルです。このとき、出力ベクトルの次元数は、この翻訳機で扱う語彙の数と同じになります。
この後のSoftmax処理でその値が単語の確率に変換されます。
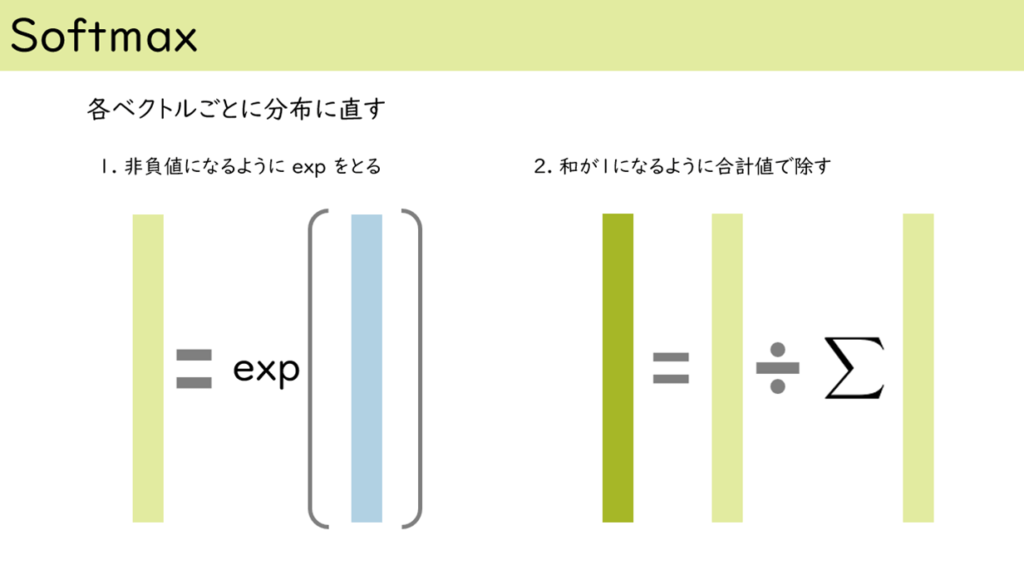
図 9 Softmax:実数ベクトルを0~1の確率値に変換します。
1の薄い水色が入力になっています。そして、確率値(値が非負で、合計が1になる)に直すため指数関数を適用して、その後、その合計値でベクトルの全体の値を除します。
濃い緑色が最終出力結果になります。その中で値が最大となる次元に対応する単語を選ぶことで、次の単語を決めることになります。
7. まとめ
トランスフォーマーの構成をみてきました。
単語を実数ベクトルで表現して扱うことが腑に落ちれば、あとは初等的な線形代数で構成されていることが分かると思います。思っていたより難しくはなかったという感想を持っていただければ幸いです。
トランスフォーマーを利用した技術にも興味深いものが多いので、ぜひいろいろ探してみてください。
Jukebox[3]は、アーティストと歌詞を指定して音楽を生成できます。
PolyGen[4]は、ポリゴンモデルをモデリングできます。
AIのべりすとは、GPT-3というトランスフォーマー系の技術が利用されています。
また、様々な改良手法も提案されています。
それは、Normの位置を変えたりするといったヒューリスティックスなものから、注意機構で計算される行列が使用するメモリーのコストを理論的にうまく削減する方法まで様々です。
本稿の後はぜひそういった派生手法について調べてみて欲しいと願っています。
【参考文献】
著者紹介

北岡 伸也 氏
Dwango Media Village
2010年に大阪大学大学院情報科学研究科マルチメディア工学専攻を修了、博士(情報科学)。
現在は株式会社ドワンゴ ニコニコ事業本部 MLエンジニアリング部 (Dwango Media Village)
マルチメディア・エンジニアリング・セクションでマネージャーを務めている。
2017年度より人工知能学会の編集委員、2020年度より画像電子学会の編集理事。