入門編

第12回:OpenACCを使ったICCG法の高速化つづき
前回に引き続き、OpenACCを使ったICCG法の高速化手法について考えてみます。
オリジナルのプログラムは東大情報基盤センターの講習会、「OpenMPによるマルチコア・メニィコア並列プログラミング入門」のページから入手できます。

第11回:OpenACCを使ったICCG法の高速化
OpenACCの基本的な考え方や使い方については、前回まででおおよそ説明しきってしまいました。
それでは習うより慣れろということで、今までの総仕上げとして、ICCG法プログラムのOpenACC実装についてご紹介します。

第10回:OpenACCでできる最適化とは?
前回は、OpenACCプログラムにおけるGPU向けライブラリプログラムの呼び出し方の解説に加え、行列積のような計算量オーダーの大きな計算パターンにおいては、GPUの性能を発揮するためのプログラムの最適化を十分に行えず、満足な性能が得られない可能性があることを解説しました。
今回はここをもう少し掘り下げて、GPUプログラミングにおける最適化とOpenACCの関係性について解説します。

第9回:速くならない?とりあえずライブラリに頼ろう!
前回に引き続き、OpenACCでうまく行かないケースとその解決策について学びます。
特に計算が複雑になればなるほど、思ったほどの性能が出ないケースが増えてきます。そんな時はどうしたら良いのでしょうか?
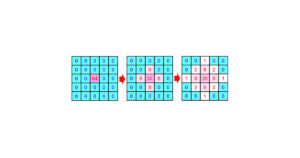
第8回:OpenACCでも扱えるけど面倒な構造体
実のところ拡散方程式のプログラムは、OpenACCと非常に相性の良いプログラム例です。しかし最初に述べた通り、OpenACCで全てがうまく行くわけではありません。
今回からは、どんな時にうまく行かないのか、そしてうまく行かないときにどう解決したら良いのか、について学びます。
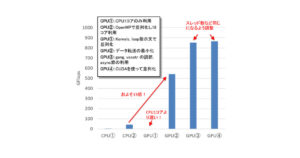
第7回:今あるプログラムを楽に速くするためには
今回で 拡散方程式のプログラム 例は終わりです。
ここまで学んだこと(+α)のまとめとして、何をすればどのくらい速くなるのかを見ていきます。
ここまでで解説した指示文(+α)を使って最適化した場合、どのくらい速くなるのか確認してみましょう。

第6回:プログラムの実行時間を確認しよう
前回は、拡散方程式のプログラムを例として、OpenACCのコンパイラが出力するメッセージについて学びました。
今回は、OpenACCプログラムを実行した際の、プログラムの性能の確認方法について学びます。
GPUを使う上で必ず考えなければならないのが、プログラムの実行速度です。
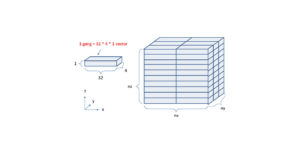
第5回:コンパイラのメッセージを確認しよう
前回に引き続き、拡散方程式のプログラムを例として、OpenACCの使い方を学びます。
…では、PGIコンパイラ (ver. 19.10) を用いて、このプログラムをコンパイルしてみましょう。コンパイル時に出力されるメッセージが図2です。
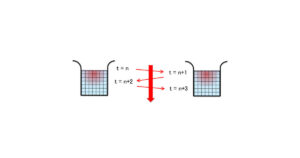
第4回:拡散現象シミュレーションのOpenACC化
前回は、非常に簡単なプログラムを例として、データ転送の最小化について考えました。
今回はもう少し実践的な例として、拡散方程式を扱います。今回は、前回行ったデータ転送の最小化が如何に重要なのかを知ってもらうために、拡散現象のシミュレーションプログラムをOpenACC化してみましょう。
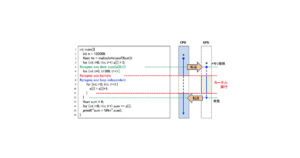
第3回:データ転送の最小化はほとんどのアプリケーションで必須
前回は、図1のプログラムを例にして、OpenACCの主要な3つの指示文:kernels, data, loop指示文を紹介しました。
今回はプログラムの効率について考えてみましょう。