前回はMPI + OpenACCによる拡散方程式のマルチGPU実装を行いましたが、性能向上できたのは4GPUまでで、8GPUでは逆に遅くなってしまったのでした。
今回はより高速化するためにはどうしたらいいのかについて解説していきます。
今回扱うコードも全てgithub上で公開されています。https://github.com/hoshino-UTokyo/lecture_openacc_mpi.git
MPI+OpenACC実装における計算と通信のオーバーラップ
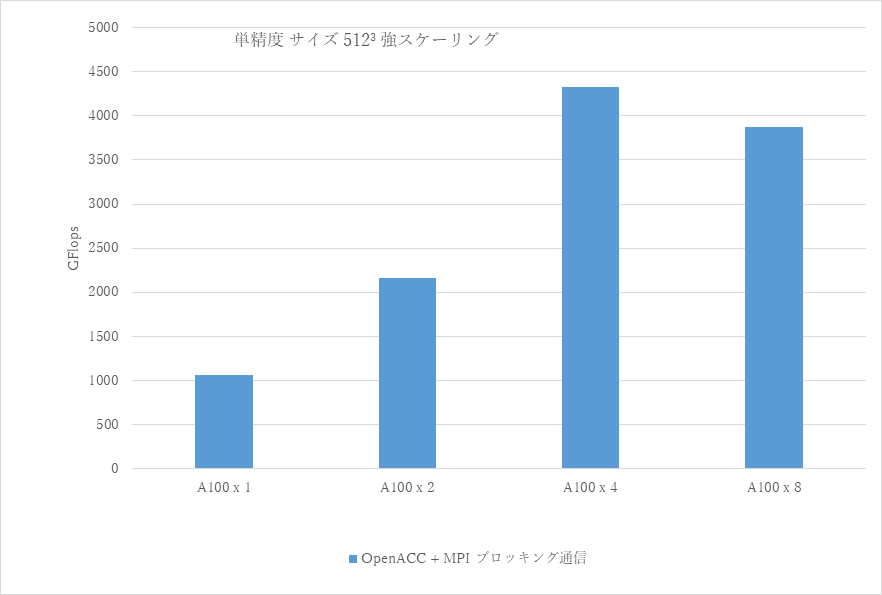
図1は前回の実装の性能です。8 GPUで遅くなってしまってる原因はなんでしょうか。
一つは、1 GPUあたりの担当領域が少なくなった結果、各GPUの実行効率が落ちてしまった、というのが理由としてあげられるでしょう。
問題を均等サイズに切り分けて並列数を増していく強スケーリング方式では、ある程度仕方のないことです。
もう一つは、やはりMPI通信です。
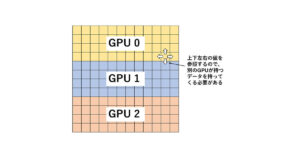
図2は3 MPIプロセスによる袖領域交換のイメージですが、プロセス数が増えたらどうなるでしょうか。
図2の例だとnzの長さは5ですが、例えば5 MPIプロセスで並列化するときはnzの長さが3になります。それに対して袖領域の幅は変わらないので、3 MPIプロセスでも5 MPIプロセスでも幅2のMPI通信が必要になります。
つまり、MPIによる並列数が増えれば増えるほど、相対的に通信時間の比重が大きくなってしまうのです!
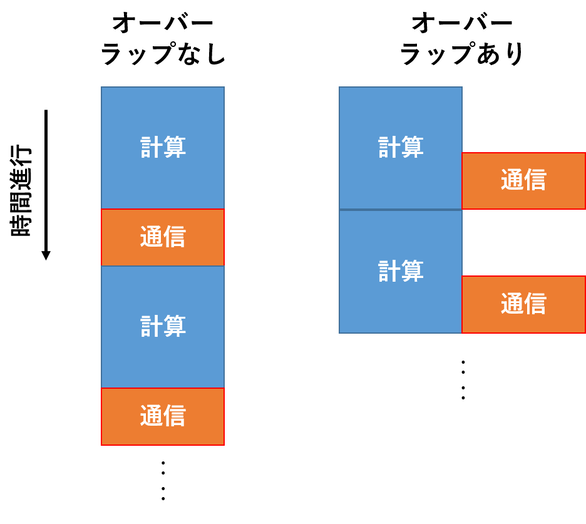
この通信時間をうまいこと隠して高速化する手法として、計算と通信のオーバーラップと呼ばれる手法が良く使われます。
図3が計算と通信のオーバーラップのイメージです。
計算時間 >= 通信時間が成り立つ間は速くなりそうですね。
ただしこれをするには、計算と通信が同時に実行可能でなければなりません。
拡散方程式の場合にはどうしたらいいのか、考えてみましょう。
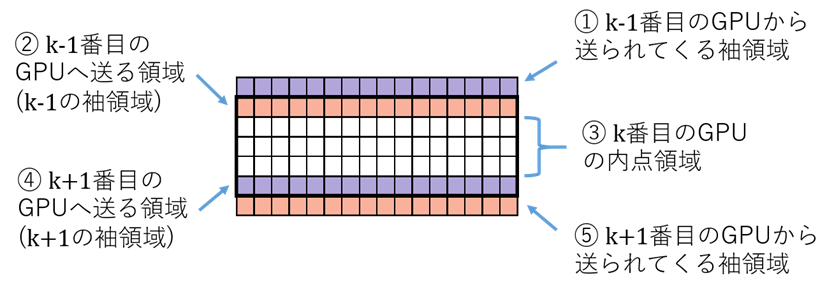
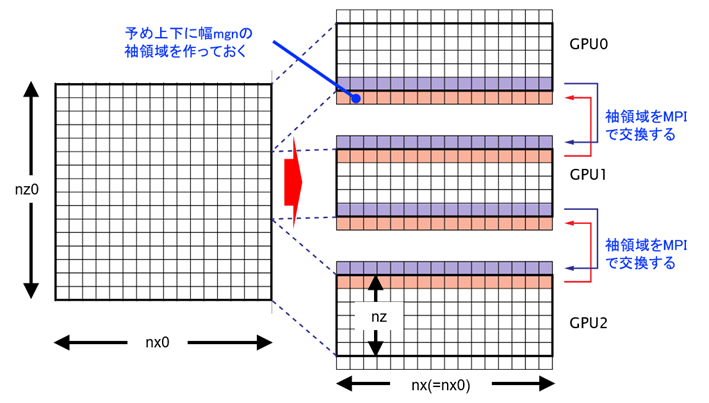
図4のようにGPUの計算担当領域を細かく分けてみます。
各格子点を計算するには、一つ前の時刻における近傍点の値が必要なわけですから、k番目のGPUが時刻t+1の②を計算するには時刻tの①をk-1番目のGPUからもらう必要があります。
同様に、時刻t+1の④を計算するには時刻tの⑤をk+1番目のGPUからもらう必要があります。
一方で③の内点領域は、隣のGPUからデータをもらわずに計算できますから、MPIの通信と関係なく実行できそうです。つまり、③の計算とMPIによる通信は同時に実行しうるわけです。
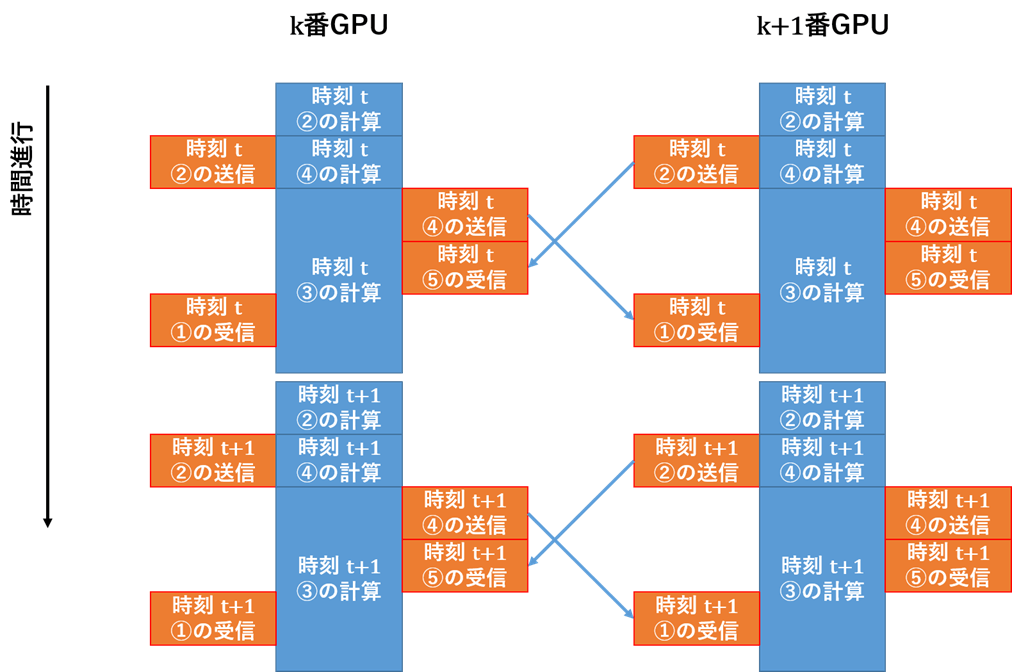
先ほどの依存関係を踏まえて、通信と計算のオーバーラップを考えると、例えば図5のようになります。
②、④の計算が終わった後に送信を行うこと、①、②、④、⑤の送受信は計算と同時に行うこと、時刻t+1の計算時には時刻tにおける①〜⑤全てのデータが揃っていること、という条件を図5は満たしています。
通信をオーバラップするためには、MPI_Isend, MPI_Irecv関数を使って①、②、④、⑤の送受信をします。
前回利用したMPI_Send, MPI_Recvが同期関数と呼ばれ、データの送受信の終了を待つのに対し、MPI_Isend, MPI_Irecv関数は非同期関数と呼ばれ、データの送受信の終了を待たずに先の処理に進みます。
MPI_waitが呼ばれて初めて終了を待つので、③の計算が終わった後でMPI_waitを呼べばいいわけですね。
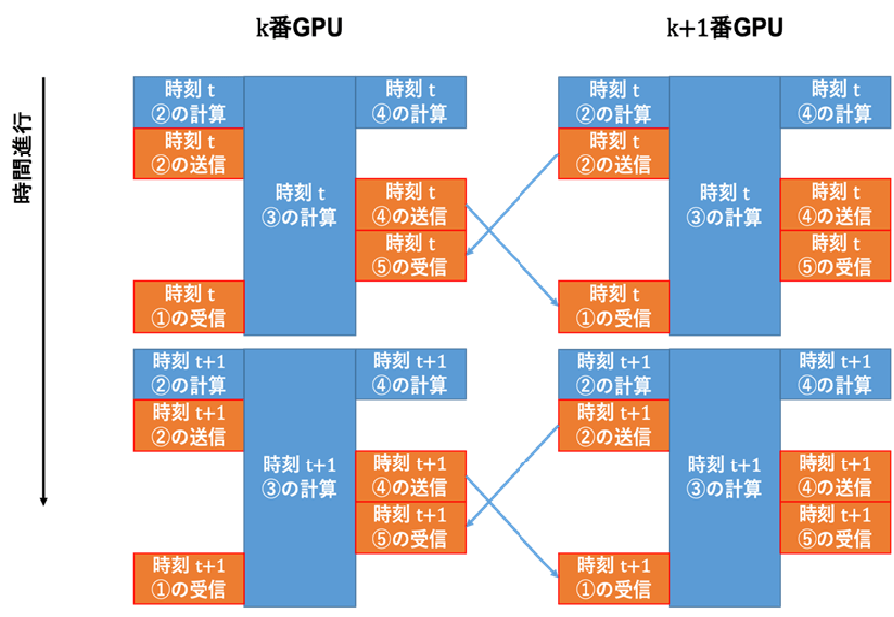
さらにOpenACCのasync節を使うと、②、③、④も同時に実行することができます。
②、④は格子数が少ないので、GPUのリソースを使い切ることができず、効率的に実行できません。③と同時に動かすことでリソースを埋めることができるわけです。

実際のコードはlecture_openacc_mpi/C/openacc_mpi_diffusion/03_openacc/diffusion.c
図7は拡散方程式のカーネルの疑似コードです。
元々は一つの三重ループでしたが、②、④を分離して3つのカーネルになっています。
②のカーネルにaysnc(0)、④のカーネルにasync(1)、③のカーネルにasync(2)と別々の番号を付けることで、これらは同時に実行可能なカーネルとして処理されます。

lecture_openacc_mpi/C/openacc_mpi_diffusion/03_openacc/main.c
図8は通信を行っている時間ループ部分です。
図7のカーネルは122行のdiffusion3d関数内で実行されます。
Asyncを付与したカーネルはどこかで終了を待たなくてはならないのですが、それが110, 111, 120行目のwait指示文です。
②の送信は116行目、④の送信は117行目で行っていますから、それより前にwait指示文で②、④の計算の終了を待つ必要があるわけです。
114, 115行目で先に受信関数を呼んでいるのはおかしい気がするかもしれませんが、これは良く用いられる手法です。MPI_Recvが「受信」であるとするならば、MPI_Irecvは「受信準備」というべき関数で、この関数呼び出し以降のデータが送られてきたタイミングで受け取ることができます。
受信準備を先に済ませた方が効率がいいので、114〜117行目はこのような順序になっています。
これらの通信は119行目のMPI_Waitallで完了します。それより1行後の120行目のwait指示文で③の終了を待ちますので、これにより③の計算と②、④の通信のオーバーラップが達成できるのです。
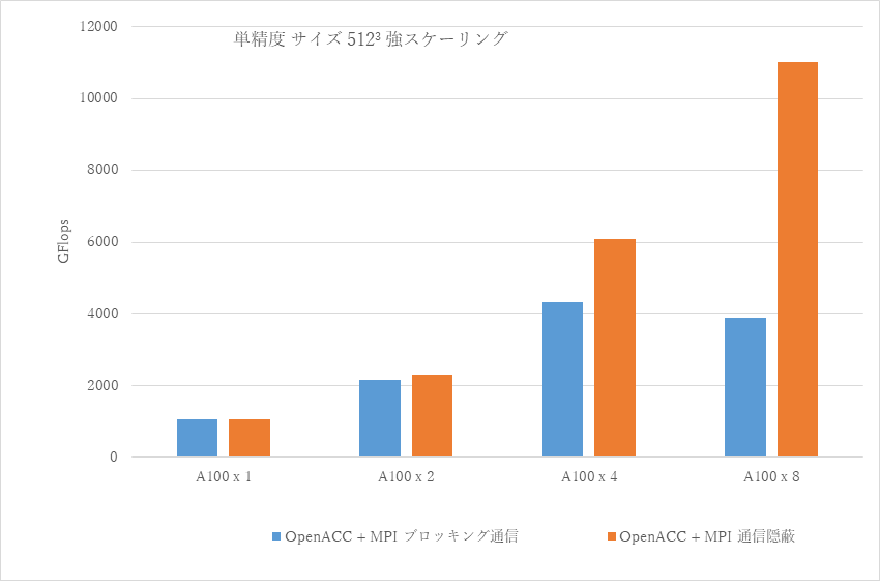
今回作った実装を前回の実装と比較したものです。
GPU数が少ない時は大差ないですが、8 GPU実行時には大きな差が出てきました。
一見細かい最適化ですが、このくらいの性能差が生まれてしまうのが難しいところですね。
1ヵ月間有効のスパコンお試しアカウント
東京大学情報基盤センターでは、教育の一環として、制限はあるものの一ヵ月の間有効なスパコンアカウントを提供しています。
現在3つのスパコンが運用されていますが、そのうちReedbushと呼ばれるスパコンには、一世代前のものではありますがGPUが搭載されていて、OpenACCを使える環境も整っています。
自分でどんどん自習したい場合は、ご利用を考えてみてください。
トライアルアカウント申し込みページ
https://www.cc.u-tokyo.ac.jp/guide/trial/free_trial.php
< 過去の講習会の資料やプログラム公開中 >
講習会ページ
https://www.cc.u-tokyo.ac.jp/events/lectures/
講習会で用いているプログラム
https://www.dropbox.com/s/z4fmc4ibdggdi0y/openacc_samples.tar.gz?dl=0