前回までは、シンプルな 拡散方程式のプログラム を例にOpenACCの基本的な使い方を学んできました。
実のところ拡散方程式のプログラムは、OpenACCと非常に相性の良いプログラム例です。しかし最初に述べた通り、OpenACCで全てがうまく行くわけではありません。
今回からは、どんな時にうまく行かないのか、そしてうまく行かないときにどう解決したら良いのか、について学びます。
OpenACCでも扱えるけど面倒な構造体
はじめに、OpenACCで扱えないわけではないけど、扱うのがとても面倒な構造体について紹介します。
構造体の面倒な点は2つあります。
面倒 ①
そもそもGPUの仕組み的に、構造体は速度低下の原因になり得る。
前提として、GPUは不連続なメモリアクセスが苦手、という事実があります。
ではそれが、どうして構造体と関わってくるのでしょうか。
前回まで扱っていた拡散方程式のプログラムでは、赤いインクの拡散をシミュレーションするために、赤いインクの濃度を配列で表現しました(図1)。

では同時に、黄色いインクも垂らしたとしたら、どう実装しましょうか。
図2のような構造体の配列を作る実装が、一つの候補になるのではないでしょうか。

この場合、RとYはそれぞれメモリ上に不連続に配置されるため、速度低下が起き得ます。
速度低下こそ起き得ますが、図2のようなポインタが含まれずサイズが明らかな構造体は、特に苦労なくOpenACCで扱えます(図3)。
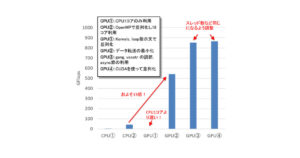
参考までに、図3左の例のように、ひとつのループ内で構造体要素全てにアクセスするのであれば、実はさほど速度低下は起きません。
色違いインクの濃度を扱う程度であればよいのですが、全く別の物理量(圧力、密度、速度、etc.)を構造体にした場合、そうもいきませんよね?

またこのような構造体の配列を利用した場合に、
あまり速度低下しない例(左)と速度低下する例(右)。
面倒 ②
CPUとGPUのメモリが独立していることに起因する、ディープコピーと呼ばれる問題。
それでは、図4のように配列の構造体として実装した場合はどうでしょう。
これならば、R も Y もメモリ上に連続して配置されるため、速度低下は気にしなくてもよさそうです。
しかしこれをOpenACCで扱う場合、ディープコピーと呼ばれる問題が付きまといます。
この構造体 f を、CPUからGPUにコピーしたとき、何が起きるでしょうか。


構造体 f をCPUからGPUへコピーした結果が図5です。
fに保存されている内容は、f.R や f.Y が CPUのメモリ上のどこにあるか、というあくまでCPU側でのアドレス情報でしかありません。
GPUのメモリはCPUと独立しているわけですから、f の内容だけコピーしても意味がありません。これを解決する方法は以下の5つくらいあると思われるのですが…
- NVIDIAのハイエンドなGPU + PGI compiler なら使える Unified memory 機能を使う。
- PGI compiler の最新版なら使える deepcopyというコンパイラオプションを使う。
- OpenACCの最新仕様にある attach、detach という指示子の使い方を調べる。
- 構造体 f をcreateした上で、構造体の中身 f.R, f.Y をcopyすると、GPU上でのポインタも更新されるというOpenACCの仕様を覚える。
- 構造体を使わない。
私は「5. 構造体を使わない」を推奨しています。
というのも、1~4は「※ただし」という例外規定があって、覚えるのが面倒だからです(私も覚えてません)。
その点「5. 構造体を使わない」は、図6のように、単に新しいポインタを宣言して置き換えてしまうという、CやFortranに準拠した方法で代替可能なので、OpenACCの細かい仕様を覚える必要がないのです。
書き換える行数自体は多いのですが、テキストエディタで文字列置換するだけで済みますから、いちいちOpenACCの仕様を調べに行くよりよっぽど早いです。
しかも、OpenACCを無視してCPUで計算する場合においても、構造体の参照コストが少ない分、速くなる可能性すらあります。

GPUで構造体をどのように扱うかというのは、性能と利便性のトレードオフになりますので、OpenACC・CUDAに関わらず、結構難しい問題です。
個人的には、上記のようにポインタで代替する方法を推しますが、環境が整えば1も強力な手法ですし、ソースを書き換えたくない場合には2~4も手段かと思います。
色々方法があるらしいことだけ覚えておいていただければ幸いです。
1ヵ月間有効のスパコンお試しアカウント
東京大学情報基盤センターでは、教育の一環として、制限はあるものの一ヵ月の間有効なスパコンアカウントを提供しています。
現在3つのスパコンが運用されていますが、そのうちReedbushと呼ばれるスパコンには、一世代前のものではありますがGPUが搭載されていて、OpenACCを使える環境も整っています。
自分でどんどん自習したい場合は、ご利用を考えてみてください。
トライアルアカウント申し込みページ
https://www.cc.u-tokyo.ac.jp/guide/trial/free_trial.php
< 過去の講習会の資料やプログラム公開中 >
東大センターが行った過去のOpenACCに関する講習会の資料やプログラムも公開されていますので、自習する場合にはぜひご利用ください。オンライン講習会 定期開催中!
講習会ページ
https://www.cc.u-tokyo.ac.jp/events/lectures/
講習会で用いているプログラム
https://www.dropbox.com/s/z4fmc4ibdggdi0y/openacc_samples.tar.gz?dl=0