前回はMPI + OpenACCによる簡単な計算を取り上げました。
今回は、入門編で取り上げた拡散方程式プログラムの複数GPU実行について考えてみましょう。
今回扱うコードも全てgithub上で公開されています。https://github.com/hoshino-UTokyo/lecture_openacc_mpi.git
拡散現象シミュレーションのおさらい
以前も取り上げた、拡散現象のシミュレーションプログラムの複数GPU実行を考えてみます。
拡散現象とは、例えば図1のようにコップに垂らしたインクが拡散して、最終的に均一になる現象です。
このシミュレーションを行うには、図2のようにコップの中の空間を格子状に区切って、タイムステップを刻みながら格子の値を更新していくのでした。
値の更新は図3のように、自身とその周辺の格子の値を参照して計算します。
複数GPUで計算する場合、この「周辺の格子を参照する」という計算パターンが問題となります。



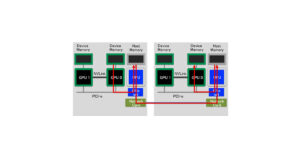
例えば図4のように各GPUの担当場所を決めると、境界の格子点を更新する場合には、隣のGPUが持つデータを必要とするわけです。
この、「別GPUからデータを持ってくる」をどうやって実現するのかが、マルチGPUプログラミングの最も重要な点になるわけです。
例えば図4のように各GPUの担当場所を決めると、境界の格子点を更新する場合には、隣のGPUが持つデータを必要とするわけです。

GPU間のデータ通信を実現する方法がまさに、前回紹介したOpenACC + MPIなのです。
MPIで複数GPUを使う実装を考えてみましょう。
まずは、前回の記事で説明したように、MPIのランク番号とGPUの番号の対応付けが必要です。
図5のように、acc_get_num_devices() と acc_set_device_num() を使います。
ここで変数rankはMPIのランク番号です。48行目はちょっとわかりづらいですが、ngpusが0か否か、つまりノードにGPUが有るか無いかで場合分けをしています。
GPUが無い場合には50行目は実行されません。GPUがある場合には、rank番号をGPU数で割った余りがgpuidに代入されます。

lecture_openacc_mpi/C/openacc_mpi_diffusion/02_openacc/main.cの一部
拡散方程式のカーネルを複数GPUで実行する上で、必要になる度に隣のGPUからデータを持ってくるのでは遅いので、あらかじめデータを置いておけるよう、図6のように上下に袖領域と呼ばれるのりしろを付けながら領域分割をします。
図6は二次元的に表現していますが、Z軸方向に担当領域を分割しています。
図中のnzは、本来のサイズであるnz0をMPIのプロセス数で割った数です。これに上下の袖領域の幅を加えて、領域f, fnを確保します(図7)。
領域をf, fnと2つ確保するのは、図2のように配列を切り替えながらタイムステップを進めるためでした。


lecture_openacc_mpi/C/openacc_mpi_diffusion/02_openacc/main.cの一部
次は拡散方程式のカーネル部分について考えてみます。
OpenACC化の手順は1GPUの場合と同じで、kernels指示文とloop指示文を用いて実装します(図8)。
袖領域付きの領域分割を行ったことで、26行目の配列インデックスの計算部分に、袖領域幅の変数mgnが現れています。
インデックス計算時にk+mgnとすることで、袖部分を飛ばして内側の点から計算を始めます。また27-32行目は境界部分の処理ですが、31, 32行目のZ方向の境界条件判定が複雑になっています。
図6を見るとわかるように、k==0のz軸の上端の処理が必要なのはGPU 0 の時だけ、k==nz0-1のz軸の下端の処理が必要なのはGPU 2の時だけなので、MPIのランク番号のrankと総プロセス数のnprocsを用いて場合分けを行います。それ以外の場合には、自身の持つ袖領域の値を参照して計算するわけです。

lecture_openacc_mpi/C/openacc_mpi_diffusion/02_openacc/diffusion.cの一部
ただし、図8で参照される袖領域の値は、本来隣のGPUが持っているデータですので、あらかじめ隣のGPUからMPIによって持って来ておく必要があります。
図6の袖領域交換を実装した部分を図9に示します。111-115行目で行っているMPI通信が、袖領域の交換です。
118行目のdiffusion3d関数(図8)の前に袖領域交換を行います。
図9の実装例ではcuda-aware MPIを前提としており、前回解説したhost_data指示文を使うことでGPU上のfのアドレスをMPI関数に渡しています。インデックスの計算が少々面倒ですが、111,112行目のMPI_Send/Recvでは図6の青紫の袖領域通信を、114,115行目では図6の赤紫の袖領域通信を行っています。

lecture_openacc_mpi/C/openacc_mpi_diffusion/02_openacc/main.cの一部
それではこの実装の性能を計測してみましょう。
計測にはA100 GPUがノード当たり8枚搭載された、東京大学情報基盤センターのWisteria-BDEC/01のAquariusノードを利用します。
結果は図10です。4GPUまでは順調に速くなっていますが、8GPUで遅くなってしまっていますね。
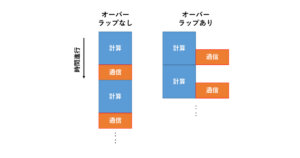
次回は性能改善について考えてみます。

1ヵ月間有効のスパコンお試しアカウント
東京大学情報基盤センターでは、教育の一環として、制限はあるものの一ヵ月の間有効なスパコンアカウントを提供しています。
現在3つのスパコンが運用されていますが、そのうちReedbushと呼ばれるスパコンには、一世代前のものではありますがGPUが搭載されていて、OpenACCを使える環境も整っています。
自分でどんどん自習したい場合は、ご利用を考えてみてください。
トライアルアカウント申し込みページ
https://www.cc.u-tokyo.ac.jp/guide/trial/free_trial.php
< 過去の講習会の資料やプログラム公開中 >
講習会ページ
https://www.cc.u-tokyo.ac.jp/events/lectures/
講習会で用いているプログラム
https://www.dropbox.com/s/z4fmc4ibdggdi0y/openacc_samples.tar.gz?dl=0