中級編の続きです。
前回はMPI + OpenMPによるHello Worldの解説でしたが、今回はもう少し計算っぽいことをしてみましょう。
コードは全てgithub上で公開されています。https://github.com/hoshino-UTokyo/lecture_openacc_mpi.git
簡単なOpenACC + MPI コードで考える
今回はopenacc_mpi_basic/以下のコードを使います。
解説はCで行いますが、Fortranも用意されています。
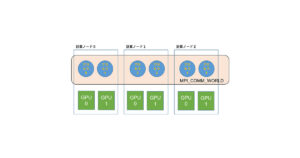
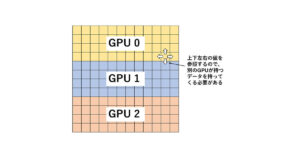
図1は今回の計算内容、図2はその計算内容を図示したものです。
このプログラムは、
- Rank 1 が配列aをa = 3.0*ny で初期化。
- Rank 1 の配列aの一部分(w * nxの部分行列)をRank 0 のbにコピー。
- コピーが成功していれば、Rank 0 の配列bの総和 sum = (3.0*ny) * (w*nx)となる。
- 最終的にはRank 0 の配列bの平均値を出力する。nx = 1,000, ny = 1,000, w = 10で初期化されているので、結局3.0*w = 30.0が出力されればOK。
という動きをします。
特に意味のある計算ではありませんが、このプログラムの高速化について考えてみましょう。

OpenACCによりループを並列化、MPIにより配列の一部を転送している。

Rank1のプロセスが、Rank0に一部分だけ計算内容を送っている。
まず、OpenACCプログラムの高速化の基本として、CPU-GPU間のデータ転送を削減するために、data指示文を付ける必要があるのでした。
慣れてきた皆様であれば、図1の46行目あたりに#pragma acc data create(a[0:n],b[0:n])と挿入して、68行目までをdata指示文で囲ってしまいたくなると思います。
しかしその場合、真ん中のMPI関数は期待通り動くのでしょうか?
GPUにあるデータをMPIで送るためには?
実はこのプログラム、単にdata指示文で囲っただけでは期待通りに動きません!
#pragma acc data create(a[0:n],b[0:n]) という指示文で作った配列aとbは、実際にはa_cpu, a_gpuとb_cpu, b_gpuというペアになっているのでした。
問題はこのペアのうちどちらが使われるのかということです。
kernels指示文で囲まれた領域内では、ペアのうちGPU側が使われるのですが、kernels指示文で囲まれていないMPI関数内ではペアのうちCPU側が使われるのです。
なお、kernels指示文の内側でMPI関数を呼ぶことはできません。それではどうしましょうか?
方法は3つあります。
1. update指示文を使う
update指示文を使って、配列ペアのCPU側を更新し、CPU同士で通信する方法です。
通信が終わったら、配列ペアのGPU側を更新します。
図3のコード例では、Rank 1はMPI_Sendをする前に64行目のupdate指示文で配列aのCPU側を更新。
Rank 0 は、MPI_Recvの後に62行目のupdate指示文でGPU側を更新しています。転送経路を図示すると、図4の様になります。

この外側でdata指示文を用いている。

2. CUDA aware MPIとhost_data指示文を使う(推奨)
MPIのライブラリには、CUDA aware MPIという機能を持つものがあります。
これは、MPI関数の引数にGPUのアドレスを受け付けるというものです。
GPU側の配列をMPI関数に受け渡すことができれば、期待通りに通信してくれます。
図5のコード例では、66, 69行目でhost_data指示文を使っています。
host_data指示文が適用された範囲内では、use_device()内に指定された配列について、GPU側を使ってくださいという指示文です。

この外側でdata指示文を用いている。
図5の様に関数の上に書けばその関数内で、{}で囲めばその範囲がhost_data指示文の適用範囲となります。
図5では、MPI_Send, MPI_Recvの第一引数にそれぞれGPU側のアドレスが渡ります。
このCUDA aware MPIを使うときに限り、GPU Direct RDMAという通信方式を有効化することができます。有効化した場合、図6のような経路でデータ転送が行われます。
MPIの構築が難しいという点を除けば、実装も簡単でかつCPUに戻さない分速いので、この方法が推奨です。

3. Unified memory 機能に任せる
最近のGPUには、Unified memoryという、CPUとGPUの間の転送を勝手にやってくれるという機能がついているのでした。
NVIDIAコンパイラ(PGIコンパイラから名前が変わりました。機能的にはあまり変更はなさそうです。)では、コンパイルオプションに-ta=tesla,managedと付けることにより、Unified memoryを有効化できます。
以前に説明した通り、Unified memory機能を有効化すると、data指示文によるデータ転送を書かなくても、必要になったタイミングでデータ転送を行ってくれます。
ですので、図1の実装からコンパイルオプションを変更するだけでOKという点でお手軽です。
ただし、Unified memory機能を有効にした場合、CPU側の配列とGPU側の配列という区別がなくなってしまうので、MPI関数を呼んだ場合にはCPUへのデータ転送が発生し、図4のような転送経路を辿ることになります。
それでは、図1, 3, 5の実装を、Wisteria/BDEC-01のGPUノードで動かしてみましょう。

きちんと速くなってますね。
1ヵ月間有効のスパコンお試しアカウント
東京大学情報基盤センターでは、教育の一環として、制限はあるものの一ヵ月の間有効なスパコンアカウントを提供しています。
現在3つのスパコンが運用されていますが、そのうちReedbushと呼ばれるスパコンには、一世代前のものではありますがGPUが搭載されていて、OpenACCを使える環境も整っています。
自分でどんどん自習したい場合は、ご利用を考えてみてください。
トライアルアカウント申し込みページ
https://www.cc.u-tokyo.ac.jp/guide/trial/free_trial.php
< 過去の講習会の資料やプログラム公開中 >
講習会ページ
https://www.cc.u-tokyo.ac.jp/events/lectures/
講習会で用いているプログラム
https://www.dropbox.com/s/z4fmc4ibdggdi0y/openacc_samples.tar.gz?dl=0