前世代と比較して最大 20 倍のパフォーマンス
NVIDIA A100 GPU [80GB]
2021年に、NVIDIA Ampere(アンペア)アーキテクチャ採用のNVIDIA A100 Tensor Core GPU [80GB版] がリリースされました。
NVIDIA A100 GPU は、コアアーキテクチャに多くの改良を加え、前世代(NVIDIA V100)と比較して最大 20 倍のパフォーマンスを発揮し、新しいスパース性機能を使うことにより、そこからさらに2倍の高速化を実現しました。
単精度・倍精度演算性能の両方を兼ね備えており、GPUメモリ 80GBと大容量のため、ディープラーニング、データサイエンス、シミュレーション、HPC(ハイパフォーマンスコンピューティング)など、大規模な計算において、最大のパフォーマンスを発揮します!
NVIDIA A100 GPU の販売またはレンタルの見積依頼・ご質問など、お気軽にお問い合わせください。
※販売終了のため、レンタルのみの取扱いとなります。
NVIDIA A100 Tensor Core GPU

NVIDIA Ampere GPU アーキテクチャをベースにした NVIDIA A100 Tensor Core GPUは、80GBの大容量メモリを搭載しています。
NVLink で2基のNVIDIA A100 GPUを接続することにより、160GBという広大なGPUメモリ空間の実現と、高速なGPU間通信が可能です。
新しい第 3 世代 NVLink と PCIe Gen 4 により、マルチ GPU システム構成を高速化します。
また、高帯域幅の HBM2 メモリ、より大容量かつ高速のキャッシュを採用し、さらに多くの CUDA コアと Tensor コアにデータを送り込むことができます。
NVIDIA Ampere アーキテクチャは、レイテンシを短縮し、AI や HPCソフトウェアの複雑さを軽減しながら、プログラミングを容易にします。
NVIDIA A100 GPU は、大規模で複雑なワークロードだけでなく、多数の小規模なワークロードも効率的に高速化できるように設計されています。
A100 GPU は、予測不可能なワークロードの需要に対応できるデータセンターの構築を可能にすると同時に、きめ細かなワークロードのプロビジョニング、GPU 利用率の向上、TCOの削減を実現します。
参考販売価格: 3,300,000円(税込 3,630,000円)
短期レンタル価格:561,000 円/月(税込 617,100 円/月)
長期1年レンタル価格:231,000 円/月(税込 254,100 円/月)
発売時期:2021年6月
レンタルの詳細はこちら
NVIDIA A100 Tensor Core GPU 特徴

- NVIDIA Ampereアーキテクチャ搭載
- 単精度・倍精度演算性能の両方を兼ね備えている!
- AIトレーニング向けのTF32を使用して、設定不要で最大6倍高速な性能を実現
- AI推論のためのマルチインスタンスGPU(MIG)により最大7倍高速な性能を実現
- ハイパフォーマンスでのデータ分析が可能
NVIDIA A100 Tensor Core GPU スペック
NVIDIA A100 Tensor Core GPU [40GB] は、販売終了となりましたので、NVIDIA A100 GPU [80GB]のみの取り扱いとなります。
NVIDIA A100 GPU とNVIDIA H100 GPUのスペックを掲載しています。
参考価格となりますので、価格についてはお問い合わせください。
| NVIDIA A100 Tensor Core GPU [PCIe] | NVIDIA H100 Tensor Core GPU [PCIe] | |
| 参考販売価格 | 3,300,000円 (税込 3,630,000円) | 5,850,000円 (税込 6,435,000円) |
| 発売時期 | 2021年6月 | 2023年3月 |
| GPUアーキテクチャ | Ampere | Hopper |
| GPUメモリ | 80 GB HBM2 | 80 GB HBM2e |
| ECC機能 | 対応 | 対応 |
| メモリバンド幅 | 1,935 GB/s | 2 TB/s |
| メモリバス | 5,120 bit | 5,120 bit |
| Compute Capability | 8.0 | 9.0 |
| CUDAコア | 6,912 | 14,592 |
| RTコア | 0 | 0 |
| Tensorコア | 432 | 456 |
| NVLink | 対応 | 対応 |
| ベースクロック | 1,065 MHz | 1,065 MHz |
| GPU Boost クロック | 1,410 MHz | 1,620 MHz |
| 最大消費電力 | 300 W | 350 W |
| 補助電源 | CPU(EPS) 8 pin | PCIe CEM5 16 pin |
| バスインターフェース | PCIe 4.0 × 16 | PCIe 5.0 × 16 |
| トランジスタ数 | 54.2 | 80 |
| マルチインスタンスGPU | 各10GBで最大7つのMIGS | 各10GBで最大7つのMIGS |
| 相互接続 | NVLink:600GB/s PCIe Gen4:64GB/s | NVLink:600GB/s PCIe Gen5:128GB/s |
NVIDIA A100 取付けに関する注意点・稼働環境
- NVIDIA A100は、サーバ搭載用のGPUです。(ファンレス・ヒートシンクタイプ)※タワー型搭載時は強制外排気ファンの搭載をお勧めします。
- 消費電力:A100 40GB「250W」、A100 80GB「300W」
- CPU 8pin 電源が必要 ※PCIe 8pin電源2回路から変換可能
- フルハイトフルレングス(FHFL)Doubleワイドカードのため、隣り合うPCIex16スロットが2つ以上あること
- PCI Expressはgen3/gen4に対応
- 各社のサーバーに搭載可能 ※PDB(PowerDistributionBoard)からの配線ケーブルがメーカー・機種によって異なる場合があります。
- 電源ケーブルの有無をご確認いただき、ない場合は電源(PSU)もしくはPDBからのケーブルをご用意いただく必要があります。
- BIOS等々のUpdateが必要になる場合があります。搭載予定メーカーのホームページもしくは、NVIDIAのホームページから搭載可否をご確認いただくことをお勧めします。
ご不明な点は、弊社までお問い合わせください。
NVIDIA A100 Tensor Core GPU 性能
NVIDIA A100 GPU と NVIDIA H100 GPUの性能を掲載しています。
| NVIDIA A100 Tensor Core GPU [PCIe] | NVIDIA H100 Tensor Core GPU [PCIe] | |
| FP64 | 9.7 TFLOPS | 24.0 TFLOPS |
| FP64 Tensor コア | 19.5 TFLOPS | 48.0 TFLOPS |
| FP32 | 19.5 TFLOPS | 48.0 TFLOPS |
| TF32 Tensor コア (スパース性機能) | 156 TFLOPS (312 TFLOPS) | 400 TFLOPS (800 TFLOPS) |
| BFLOAT16 Tensor コア (スパース性機能) | 312 TFLOPS (624 TFLOPS) | 800 TFLOPS (1,600 TFLOPS) |
| FP16 Tensor コア (スパース性機能) | 312 TFLOPS (624 TFLOPS) | 800 TFLOPS (1,600 TFLOPS) |
| FP8 Tensor コア (スパース性機能) | ー | 1,600 TFOPS (3,200 TFLOPS) |
| INT8 Tensor コア (スパース性機能) | 624 TOPS (1,248 TOPS) | 1,600 TOPS (3,200 TOPS) |
* スパース性機能を使用した場合の TFLOPS/TOPS 実効値
NVIDIA GPU 一覧表PDF
弊社で取り扱っているNVIDIA GPUの性能・スペックを一覧にしました。
PDFファイルをダウンロードすることができます。

NVIDIA GPU 拡張保証サービス

NVIDIA GPUは「3年間センドバック保証(無償修理・交換)」のメーカー標準保証が基本として含まれていますが、
当社オリジナルとして「NVIDIA GPU 拡張保証サービス」をご提供しています。
「NVIDIA GPU 拡張保証サービス」には、先出しセンドバック保証、センドバック延長保証、オンサイト保証があり、お客様のニーズや状況にあわせた保証内容にすることができます。
NVIDIA GPU 拡張保証サービスにより、GPU導入後も、長く・安心してお使いいただけます。
GPUを導入される際に、あわせてご検討ください。
★NVIDIA GPU 拡張保証サービスの詳細はこちら
NVIDIA A100 Tensor Core GPUの設置場所は3通り!
会社の環境や設置スペースにあわせて、NVIDIA A100 GPUの設置場所を選ぶことができます。
New!
1. デスクサイドに設置

高負荷をかけても静音!GPU温度も安定
GPU Cooling BOXのファンを工夫したことにより、NVIDIA A100 GPUがフル稼働しているのも気づかないほどの静音です。
また、GPUを効率的に冷やすことができるため、空冷と比較して10-15%の性能向上が見込めます。
2. サーバー室に設置

GPUサーバー
GS-Supermicro SYS-741GE-TNRT
GPU最大4基 搭載可能
第4世代 インテル Xeon スケーラブル・プロセッサーを搭載しており、16個のDIMMスロット、最大4TBのDRAM、PCI-E 5.0に対応、最大8台のNVMeドライブ、4Uラックサイズのタワー型です。
横置き、縦置きも可能です。
3. 静音ケースに入れて居室内に設置
静音ケースも取り扱っています。
サーバー室への設置が一般的ですが、GPUサーバーを静音ケースに入れて居室に置き、手元で使用されるニーズも増えています。
静音ケースの価格は、GS-Supermicro SYS-741GE-TNRT 製品ページ に掲載しています。
NVIDIA A100 Tensor Core GPU パフォーマンス
NVIDIA A100 GPU Performance for AI
最大級のモデルで最大 3 倍高速な AI トレーニングを実現
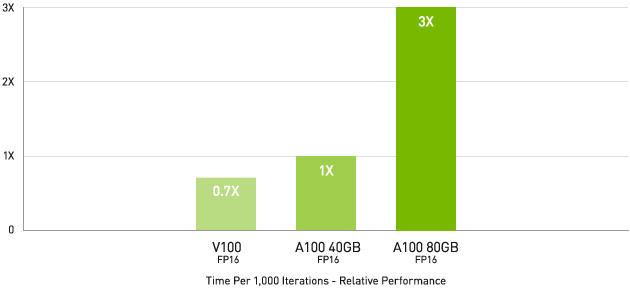
DLRM on HugeCTR framework, precision = FP16 | NVIDIA A100 80GB batch size = 48 | NVIDIA A100 40GB batch size = 32 | NVIDIA V100 32GB batch size = 32.
※NVIDIA A100 Tensor Core GPU [40GB] は、販売終了のため、[80GB]のみの取り扱いとなります。
AI 開発は、次の新たな課題に向けて、データの増加や処理が爆発的に複雑化しています。モデルのトレーニングには、大規模な計算処理能力とスケーラビリティが必要になります。
NVIDIA A100 のTensor コアと Tensor Float (TF32) を利用することで、NVIDIA Volta と比較して最大 20 倍のパフォーマンスがコードを変更することなく得られます。
加えて、Automatic Mixed Precision と FP16 の活用でさらに 2 倍の高速化が可能になります。
NVIDIA® NVLink®、NVIDIA NVSwitch™、PCI Gen4、NVIDIA® Mellanox® InfiniBand®、NVIDIA Magnum IO™ SDK と組み合わせることで、数千個もの A100 GPU まで拡張できます。
2,048 基の A100 GPU という大規模な環境で、BERT などのトレーニング ワークロードを、世界記録となる 1 分未満で解決できます。
ディープラーニング レコメンデーション モデル (DLRM) といった大きなデータ テーブルを持つ最大級のモデルの場合、A100 80GB であれば、ノードあたり最大 1.3 TB の統合メモリに到達し、A100 40GB の最大 3 倍のスループットの増加が可能です。
NVIDIA は、AI トレーニングの業界標準ベンチマークであるMLPerfで複数のパフォーマンス記録を打ち立て、そのリーダーシップを確立しました。
NVIDIA A100 GPU Performance for AI
AI推論パフォーマンス
CPU と比較して最大 249 倍の高速化
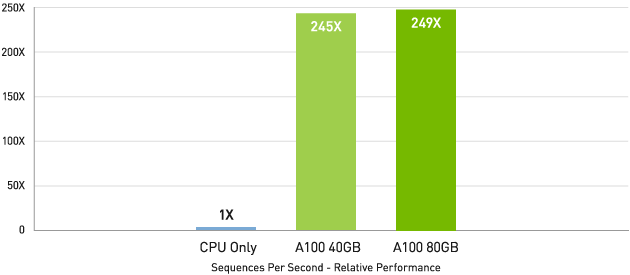
BERT-Large Inference | CPU only: Dual Xeon Gold 6240 @ 2.60 GHz, precision = FP32, batch size = 128 | V100: NVIDIA TensorRT™ (TRT) 7.2, precision = INT8, batch size = 256 | A100 40GB and 80GB, batch size = 256, precision = INT8 with sparsity.
A100 40GB と比較して最大 1.25 倍
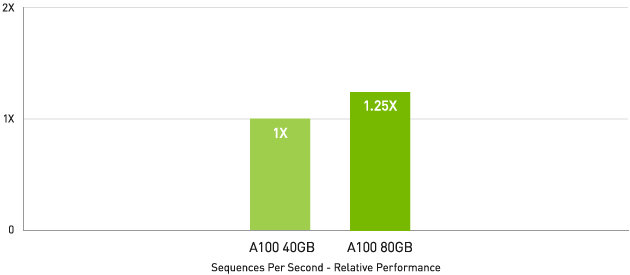
MLPerf 0.7 RNN-T measured with (1/7) MIG slices. Framework: TensorRT 7.2, dataset = LibriSpeech, precision = FP16.
※NVIDIA A100 Tensor Core GPU [40GB] は、販売終了のため、[80GB]のみの取り扱いとなります。
NVIDIA A100 GPUには、推論ワークロードを最適化する画期的な機能が導入されています。
FP32 から INT4 まで、あらゆる精度を加速します。マルチインスタンス GPU (MIG) テクノロジでは、1 個の A100 で複数のネットワークを同時に動作できるため、コンピューティング リソースの使用率が最適化されます。
また、構造化スパース性により、A100 による数々の推論性能の高速化に加え、さらに最大 2 倍のパフォーマンスがもたらされます。
BERT などの最先端の対話型 AI モデルでは、NVIDIA A100 GPUは推論スループットを CPU の最大 249 倍に高めます。
メモリ容量の大きな NVIDIA A100 80GB は、各 MIG のサイズが 2 倍になります。自動音声認識用の RNN-T といった、バッチサイズが制約された非常に複雑なモデルでは、A100 40GB に比べて最大 1.25 倍のスループットが得られます。
市場をリードする NVIDIA のパフォーマンスはMLPerf 推論 推論で実証されました。
NVIDIA A100 は 20 倍のパフォーマンスを実現し、そのリードをさらに広げます。
NVIDIA A100 GPU Performance for HPC
HPC(ハイパフォーマンスコンピューティング)パフォーマンス
4 年間で 11 倍の HPCパフォーマンス!
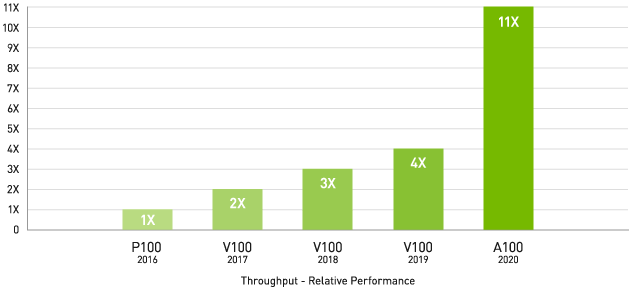
Geometric mean of application speedups vs. P100: Benchmark application: Amber [PME-Cellulose_NVE], Chroma [szscl21_24_128], GROMACS [ADH Dodec], MILC [Apex Medium], NAMD [stmv_nve_cuda], PyTorch (BERT-Large Fine Tuner], Quantum Espresso [AUSURF112-jR]; Random Forest FP32 [make_blobs (160000 x 64 : 10)], TensorFlow [ResNet-50], VASP 6 [Si Huge] | GPU node with dual-socket CPUs with 4x NVIDIA P100, V100, or A100 GPUs.
HPCアプリケーションで最大 1.8 倍高速
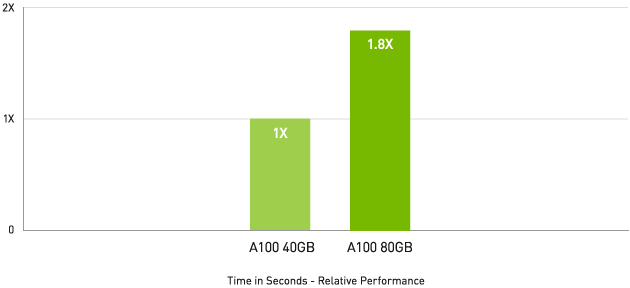
Quantum Espresso measured using CNT10POR8 dataset, precision = FP64.
※NVIDIA A100 Tensor Core GPU [40GB] は、販売終了のため、[80GB]のみの取り扱いとなります。
NVIDIA A100 は、GPU の導入以降で最大のHPCパフォーマンスの飛躍を実現するために、Tensor コアを導入しています。
NVIDIA A100 80 GB の最速の GPU メモリと組み合わせることで、研究者は 10 時間かかる倍精度シミュレーションをA100 で 4 時間たらすに短縮できます。
HPC アプリケーションで TF32 を活用すれば、単精度の密行列積演算のスループットが最大 11 倍向上します。
大規模データセットを扱う HPC アプリケーションでは、メモリが追加された A100 80GB により、マテリアル シミュレーションの Quantum Espresso において最大 2 倍のスループットの増加を実現します。
この膨大なメモリと前例のないメモリ帯域幅により、A100 80GB は次世代のワークロードに最適なプラットフォームとなっています。
ハイパフォーマンス データ分析
ビッグ データ分析ベンチマークでCPUより最大83倍
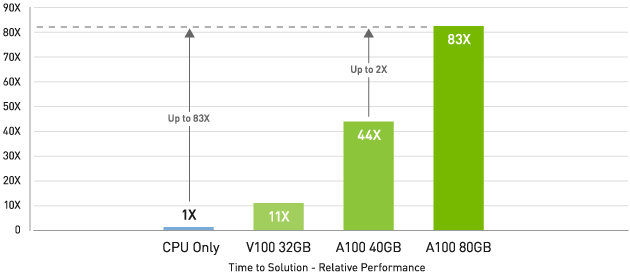
Big data analytics benchmark | 30 analytical retail queries, ETL, ML, NLP on 10TB dataset | CPU: Intel Xeon Gold 6252 2.10 GHz, Hadoop | V100 32GB, RAPIDS/Dask | A100 40GB and A100 80GB, RAPIDS/Dask/BlazingSQL
※NVIDIA A100 Tensor Core GPU [40GB] は、販売終了のため、[80GB]のみの取り扱いとなります。
データ サイエンティストは、大量のデータセットを分析し、可視化し、インサイトに変えられる能力を求めています。
しかしながら、スケールアウト ソリューションは行き詰まることが多々あります。複数のサーバー間でデータセットが分散されるためです。
NVIDIA A100 GPUを搭載したアクセラレーテッド サーバーなら、大容量メモリ、2 TB/秒を超えるメモリ帯域幅、NVIDIA® NVLink® と NVSwitch™ によるスケーラビリティに加えて、必要な計算処理能力を提供し、データ分析ワークロードに対応することができます。
InfiniBand、NVIDIA Magnum IO™ 、オープンソース ライブラリの RAPIDS™ スイート (GPU 活用データ分析用の RAPIDS Accelerator for Apache Spark を含む) と組み合わせることで、NVIDIA データ センター プラットフォームは前例のないレベルのパフォーマンスと効率性で大規模なデータ分析ワークロードを高速化します。
NVIDIA A100 80GB はビッグ データ分析ベンチマークで、CPU の 83 倍高いスループット、A100 40GB では 2 倍高いスループットでインサイトをもたらします。データセット サイズが爆発的に増える昨今のワークロードに最適です。
MIG (マルチインスタンス GPU) とは・・・
最大 7 倍高速な性能を実現
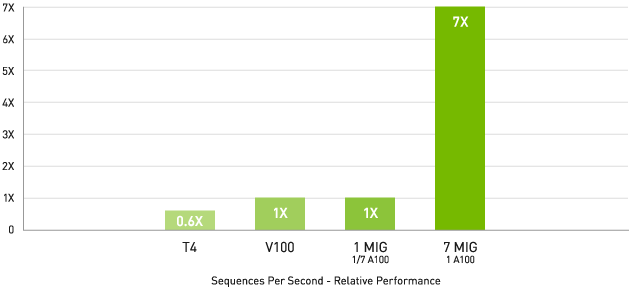
NVIDIA T4 Tensor Core GPU:NVIDIA TensorRT™(TRT)7.1、精度= INT8、バッチサイズ= 256
V100:TRT 7.1、精度= FP16、バッチサイズ= 256
A100:実稼働前のTRT、バッチサイズ= 94、精度= INT8、スパース性
NVIDIA A100 と MIG の組み合わせにより、GPU 対応インフラストラクチャを今までにないレベルで最大限に活用できます。
MIG によって A100 GPU は最大 7 つの独立したインスタンスに分割でき、複数のユーザーが自分のアプリケーションや開発プロジェクトを GPU で高速化できます。
MIG は Kubernetes やコンテナー、ハイパーバイザベースのサーバー仮想化によるNVIDIA Virtual Compute Server(vComputeServer) と連携します。
MIG を使用することで、インフラ管理者は各ジョブのサービス品質 (QoS) を保証した適切なサイズの GPU を提供し、使用率を最適化し、高速化されたコンピューティング リソースの範囲をすべてのユーザーに拡大することができます。
MIGテクノロジの仕組み

MIG を使用すれば、複数のインスタンスでジョブが同時に実行され、それぞれに専用のコンピューティング リソース、メモリ、メモリ帯域幅が割り当てられるため、予測可能なパフォーマンス、 サービス品質、最大 GPU 使用率を実現することができます。
たとえば、管理者はインスタンスを 2 つ作成し、メモリをいずれも 20 ギガバイトにしたり、10 ギガバイトのインスタンスを 3 つ作成したり、5 ギガバイトのインスタンスを 7 つ作成したりできます。あるいは、それらを組み合わせることもできます。 システム管理者は、ワークロードの種類が異なるときに、ユーザーに適切なサイズの GPU を提供できます。
MIG インスタンスは構成を動的に変更させることもできます。
管理者は、ユーザーや業務上の要求が変わったときに、それに合わせて GPU リソースを変更できます。
たとえば、昼はスループットの低い推論のために 7 つの MIG インスタンスを使用し、夜はディープラーニング トレーニングのために 1 つの大きな MIG インスタンスに再構成することが可能です。
NVIDIA A100 Tensor Core GPU 搭載製品



NVIDIA A100 Tensor Core GPU 搭載可能な製品について、
ご不明な点やご質問などありましたら、お問い合わせください!

お気軽にご相談ください!
製品に関するご質問・ご相談など、お気軽にお問い合わせください。
NVIDIA認定パートナー「GDEPソリューションズ」は、
お客様の用途に最適な製品のご提案から導入までサポートします。