お久しぶりです!
今回からは中級編ということで、近年普通になっている複数のGPUを搭載した計算機で、OpenACCを使う方法の解説を行います。
なお、ここで使っているコードは全てgithub上で公開されています。
公開コードには、2021年5月から運用を開始した、東京大学情報基盤センターのスパコン、Wisteria/BDEC-01で利用可能なジョブスクリプト等を含んでいます。
https://github.com/hoshino-UTokyo/lecture_openacc_mpi.git
複数のGPUを使う方法とは?
最初にお断りしておきますと、OpenACCには複数のGPUを使うための機能はありません!
OpenACCはGPUの内部で並列処理するためのものであって、複数のGPUを使うためには、GPUを呼び出すCPU側の処理を並列化するのが一般的です。
つまり、CPUの並列処理言語である、OpenMPやMPIと組み合わせて使うことになります。
(1)OpenMP+OpenACC
結論から言うと推奨しません。
OpenMPとOpenACCの指示文を同じループで同時利用することができないので、OpenMPの指示文を使わず、omp_get_thread_num()関数を用いて並列化することになります。
これは指示文指向のOpenMPの利点を潰していて、MPIとコードの煩雑さは変わりませんし、同じノード内のGPUしか利用できないため、拡張性がありません。
メリットは環境構築が容易なことです。
NVIDIA HPC SDKをインストールすれば、OpenACCと一緒について来ますからね。
解説はしませんが、サンプルコードをopenacc_multi_gpu_hello/01_openacc_openmp に用意してあります。
(2)MPI+OpenACC
推奨です。
最大の難点は、適切な環境構築が難しいことです。
NVIDIA HPC SDKにOpenMPI(MPIのライブラリ。紛らわしいがOpenMPとは別物。)が同梱されていますので、とりあえずはそれを使うのが良いと思います。
以降では、MPI+OpenACCの使い方を解説していきます。
コードとしては、openacc_multi_gpu_hello/02_openacc_mpiを使います。
まずはMPIについて簡単に解説します。
MPIは複数のCPUの間で、メッセージを送信し合うためのツールです。
図1ではメッセージのやり取りすらしておらず、出てくるのはテンプレの4つの関数です。
- 11行目 MPI_Init(&argc, &argv); ここからMPIプログラム始まりますという宣言です。
- 16行目 MPI_Comm_size(MPI_COMM_WORLD, &nprocs); 世界に何人のプロセスがいるか、問い合わせるための関数です。MPI_COMM_WORLDはコミュニケータと呼ばれ、最初から全てのプロセスが参加しています。nprocsに人数が代入されます。
- 17行目 MPI_Comm_rank(MPI_COMM_WORLD, &rank); 自分の背番号を問い合わせるための関数です。MPI_COMM_WORLDに参加しているプロセスは、0から順番に背番号を振られています。rank に背番号が代入されます。
- 42行目 MPI_Finalize(); ここでMPIプログラム終了ですという宣言です。

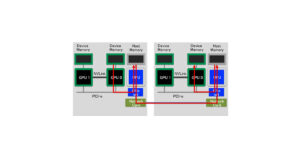
各MPIプロセスにGPUを一つずつ割り当てている。
上の関数を使うと、結局のところ何人プロセスがいて、自分の背番号が何番なのかがわかります。
それを使って、29-30行目では36行目のループの担当範囲を決めています。
nprocs = 2の場合を考えてみましょう。
length = 12、nprocs = 2 ですから、rank 0 のプロセスではstr = 0, end = 6となり、
rank 1 のプロセスではstr = 6, end = 12となります。
つまり36行目のループは、rank 0 では 0 <= i < 6, rank 1では6 <= i < 12 のループとなるわけです。
ここまでが、OpenACCを無視した、単なるMPIプログラムとしての挙動です。
OpenACCを組み合わせる場合に重要なのが、25-27行目です。
- 25行目 int ngpus = acc_get_num_devices(acc_device_nvidia); 計算ノード内のGPU数を問い合わせるための関数です。acc_device_nvidiaで、NVIDIA製のGPU数を問い合わせます。
- 27行目 acc_set_device_num(gpuid, acc_device_nvidia); この関数以降、gpuid番目のGPUを使いますという宣言です。デフォルトでは0番のGPUを使おうとします。
つまり上記の関数を使って25-27行目のような設定をしないと、rank 0もrank 1も0番のGPUを取り合ってしまい、複数GPUでの並列計算ができないのです。
そこで26行目のようにrank番号に従ってGPU番号を指定することで、複数GPUの利用を可能とします。
注意点として、図2の様にMPIのプロセス番号が計算ノードを跨いで通しで付けられる一方、GPUの番号は計算ノード毎に付けられています。

プロセス番号が計算ノードを跨いで通しの番号である一方、GPUは各ノードでローカルに番号が付けられている。
このプロセス番号とGPU番号の対応付けさえ出来てしまえば、残りはただのOpenACCのプログラムです。
34-38行目では、普通のOpenACCと同様に、kernels指示文とloop指示文を用いてループを並列化しています。
このように、複数GPU間の並列化はMPIに任せて、GPU内での並列化はOpenACCが担当することで、MPI+OpenACCのプログラムが完成します。
それではこのコードを、Wisteria/BDEC-01上で動かしてみます。
Wisteria/BDEC-01では予めNVIDIA HPC SDKやOpenMPIがインストールされていますので、moduleコマンドを利用することで環境構築が完了します。
その他の環境では、OpenMPIやNVIDIA HPC SDKが利用できるように、適切に環境設定が為されている必要があります。
$ module load nvidia cuda ompi-cuda #Wisteriaではこれで完了
$ make
$ pjsub run.sh #Wisteria でのジョブ実行
MPIのプログラムですので、実行時には mpirun などのコマンドを使う必要があります。
図1のプログラムはMPIのプロセス数が2の時にしか動かないようになっていますので、
$ mpirun –np 2 ./run # run.sh の中に記載してあります。
として実行します。実行結果が以下です。
rank = 0, gpuid = 0, b = Hello
rank = 1, gpuid = 1, b = World
rank 0 のプロセスは 0番GPUを使って Hello World の6文字目までを、rank 1 のプロセスは 1 番GPUを使って7文字目以降を配列bに代入できてますね。
1ヵ月間有効のスパコンお試しアカウント
東京大学情報基盤センターでは、教育の一環として、制限はあるものの一ヵ月の間有効なスパコンアカウントを提供しています。
現在3つのスパコンが運用されていますが、そのうちReedbushと呼ばれるスパコンには、一世代前のものではありますがGPUが搭載されていて、OpenACCを使える環境も整っています。
自分でどんどん自習したい場合は、ご利用を考えてみてください。
トライアルアカウント申し込みページ
https://www.cc.u-tokyo.ac.jp/guide/trial/free_trial.php
< 過去の講習会の資料やプログラム公開中 >
講習会ページ
https://www.cc.u-tokyo.ac.jp/events/lectures/
講習会で用いているプログラム
https://www.dropbox.com/s/z4fmc4ibdggdi0y/openacc_samples.tar.gz?dl=0