前回の記事では、GPUプログラミングにおけるOpenACCの立ち位置や、OpenACCで記述可能な並列処理など、OpenACCの概要を説明しました。
今回からは、具体的なOpenACCの使い方について解説していきます。
その前に知っておきたいGPUの特徴
具体的なOpenACCの使い方を解説する前に、最低限知っておいてほしいGPUの特徴があります。
これはCUDAを使う場合にも同様です。
- GPUにはたくさんのコアがあり、並列計算が必須。
- CPUとGPUの記憶領域(メモリ)が物理的に独立であるため、CPUとGPUの間のデータ転送が必須。
並列計算が必須なことについては前回説明しました。
それと同じくらい重要なこととして、CPU-GPU間のデータ転送があります。
計算はオペレーティングシステム(WindowsやMac OSなど)の動いているCPUから始まりますので、GPUでの計算に必要なデータはCPUから転送しなくてはならないのです。
ここで問題なのが、CPU-GPU間のデータ転送が遅いことなのです!
CPUのデータをGPUに複製するスピードは、GPUの中でデータを複製する場合より2桁遅いと思っていいです。従ってGPUプログラミングでは、CPU-GPU間のデータ転送を最小化する最適化が必須となります!

最低限覚えるべきOpenACCの3つの指示文
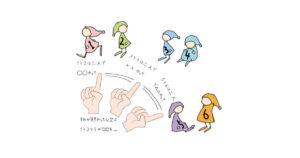
さて、ここまでに説明したGPUの特徴を踏まえると、GPUプログラミングでは以下が必要になります。
- GPUプログラミングではプログラム中の重たいループ構造を抜き出して高速化するため、プログラム中のどの部分をGPUで実行するかを決める
- 多数の小人さん(以降ではスレッドっと言います)に仕事を割り付けるため、ループ構造を並列化する
- CPUとGPUのメモリが物理的に分かれており、かつデータ転送に時間がかかるため、CPU-GPU間のデータの転送とその最小化をする
これをOpenACCでは、それぞれ対応する以下の三つの指示文で記述します。
Ⅰ. kernels指示文
Ⅱ. loop指示文
Ⅲ. data 指示文
ちなみに指示文とは、プログラム中に挿入する特殊なコメント行のことで、コンパイラに指示を行うために使われます。
指示文に対応していないコンパイラでは単にコメントとして扱われるため、元のプログラムを壊さないことが利点です。OpenACCの指示文は、すでに出来上がったC/C++/Fortranのプログラムに挿入することで、上記の1,2,3を指示します。
百聞は一見にしかず!実際のコード例を用いて説明しましょう。

最後にloop指示文ですが、これはkernels指示文の内側に現れるループが、どのような性質を持ったループであるかを示すために主に使われます。故に、kernels指示文の内側でしか使えません。
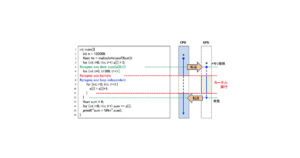
図2では、9行目のループがindependentなループ、すなわちデータ独立であり並列化可能なループであることを示しています。
結局、図2のプログラムでは、5行目において一度だけ、CPUからGPUに配列aをコピーし、9行目から11行目のループがGPU上で並列に100回実行され、12行目で一度だけ、GPUからCPUに配列aをコピーし、CPU側で結果が得られる。というプログラムになっています。
今回は、GPUプログラミングにおいて必須である、GPUで実行する場所を決めること、ループを並列化すること、CPU-GPU間のデータ移動をすること、を可能にする、kernels指示文、loop指示文、data指示文について、非常に簡単なプログラム例を用いて紹介しました。
しかし図2を見ていただくと、このプログラムはもっと工夫の余地がありそうですよね?
(4行目や14行目も並列化できるのでは?データ転送をもっと少なくできるのでは?)
次回は、この簡単なプログラムを用いて、プログラムの性能を意識しながら、kernels, loop, data指示文についてのさらに詳しい使い方を紹介していきます。