2023年3月
実にさまざまな産業分野で活用されている、熱や流体のシミュレーション。
その解析能力や精度は、GPUコンピューティングの発展と共に大きく進化しています。
そこで今回は、流体・粉体解析ソフトウェアの開発・販売サポート、各種ニーズに応じた解析コンサルティングサービスおよび導入検討の支援などを行っている、プロメテック・ソフトウェア株式会社 解析技術部にインタビューを実施。
プロフェッショナルの視点から、GPUコンピューティングがシミュレーショにもたらす効果について語ってもらいました。
“Industrial GPU Computing”
実用レベルの解析規模は現時点で数億粒子オーダー

パワートレイン内オイル掻きあげ解析
プロメテックは、格子生成が不要な新しい計算手法である粒子法(MPS:Moving Particle Simulation method)の理論に基づく流体解析ソフトウェア「Particleworks」や、
粉体シミュレーション法としてもっとも代表的な離散要素法(DEM:Discrete Element Method)の理論に基づく粉体解析ソフトウェア「Granuleworks」などの開発・販売・サポートを行っている企業です。
また、各種ニーズに応じた解析コンサルティングサービスおよび導入検討の支援、
可視化・映像制作サービスとしてCAE解析結果ファイルをCG 編集ソフトウェアへ入力可能なファイルフォーマットに変換するソフトウェア「SIMUNIMA」の提供も行っています。
熱や流体のシミュレーションに関して「粒子法(MPS)は自動車・輸送機械/鉄鋼・金属/医療・製薬/食品・生活/エネルギー/電気・機械/素材・素形材/土木・建築など幅広い分野で活用されています。
メインとなるのは主に流体・粉体の解析とそれらの複合解析が必要とされる分野ですね」と語ります。

GPUのスケーラビリティについては、同社が提供する流体解析ソフトウェア「Particleworks」で2010年代初頭から本格的にGPU対応を進めており、「解析規模は計算リソースを上げていけばいくらでも高められます。
例えばアカデミック分野では数十億粒子の事例もありますが、産業界で実用レベルといえる解析規模は現時点で数億粒子オーダーといったところです」と語る同氏。
利用が多いGPUについては、ワークステーションで動作する「NVIDIA Quadro GV100」を中心に、
Linuxベースでは「NVIDIA Tesla V100s」、最近は「NVIDIA A100 Tensor Core GPU」なども使い始めているそうです。

CPU換算で1000~1500コア相当のGPUスケーラビリティ
参考用としてCPUとGPUの比較データを見せてくれました。
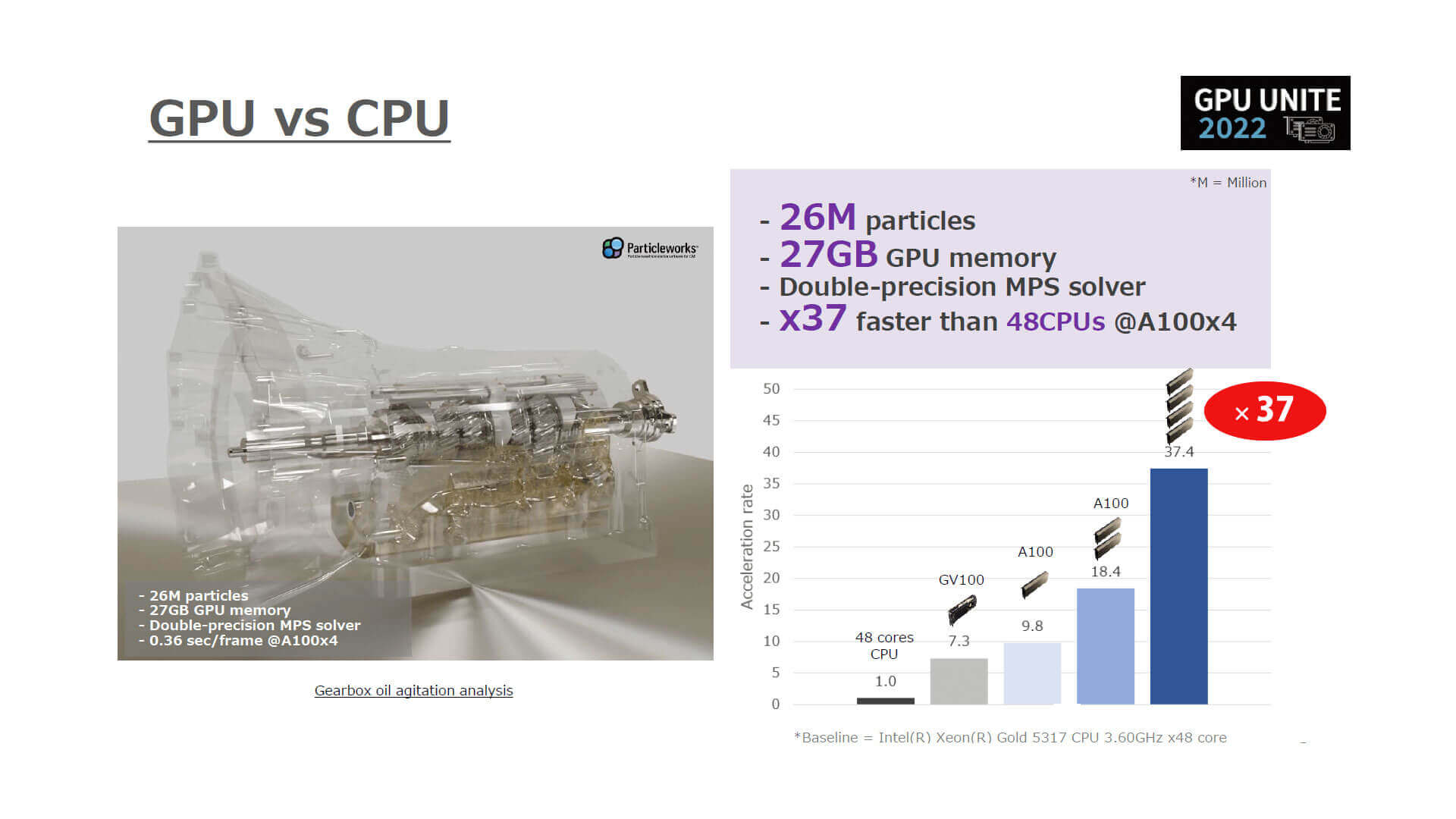
※本解析はソフトウェアのベンチマークを目的としており、
同じ解析スペックで期待通りの結果が得られることを保証するものではありません。
こちらは自動車用5速トランスミッション内のギアオイル挙動をシミュレーションしたもので、解像度は2,600万粒子、GPUメモリは27GBを使用。48コアのインテル Xeon Gold 5317 プロセッサーを基準とした場合、NVIDIA A100 GPU×4枚で約37倍と、CPU換算で1,000~1,500コア相当のパフォーマンスが出ていることになります。
さらにGPUを用いたいくつかのシミュレーション結果を見せながら語ります。
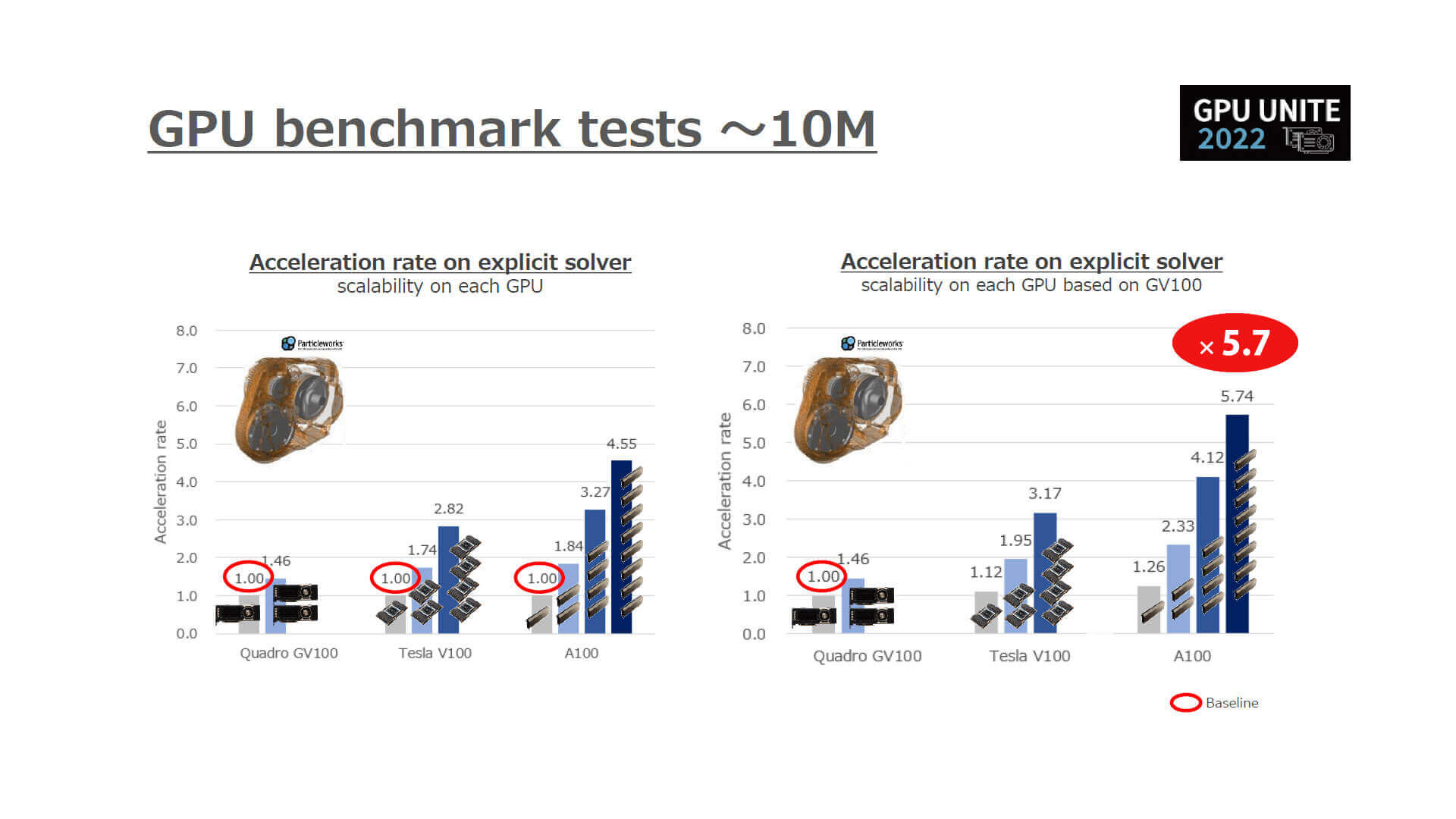
※本解析はソフトウェアのベンチマークを目的としており、
同じ解析スペックで期待通りの結果が得られることを保証するものではありません。
たとえば解像度約1,000万粒子、メモリが9GB程度の小規模なギアのベンチマークでは、
NVIDIA Quadro GV100×1枚に対して × 2 枚の場合は 1.46倍、
NVIDIA Tesla V100s×1枚に対して × 4 枚の場合は 2.82倍、
NVIDIA A100 GPU×1枚に対して × 8 枚の場合は 4.55倍 のパフォーマンスを発揮。
並列化効率は70%前後に達しています。
また、NVIDIA Quadro GV100×1枚を基準とした場合、
NVIDIA A100 GPU × 8 枚 のパフォーマンスは5.74倍となっています。
このような小規模の解析をGPU×8枚で実施するのはあまり現実的ではありませんが、解像度が2000万粒子規模を超えたあたりから並列化効率は90%以上というハイスケーラビリティを示しており注目に値します。
1.5億粒子規模の解析を
デスクトップワークステーションで実現!
続いて大規模解析の事例を紹介してくれました。
GPUによる大規模解析 事例1

NVIDIA A100 80GB × 4 gpus
自動車用5速トランスミッション内のギアオイル挙動をシミュレーションした解像度1億7,300万粒子の事例です。
「流体粒子が壁やギアに付着した際の頻度をマッピングする機能を利用し、どの部分にどれだけオイルが触れたのか評価したり、各ギアのトルクを算出したり、といった使い方などを想定しています。」と語ります。
GPUによる大規模解析 事例2
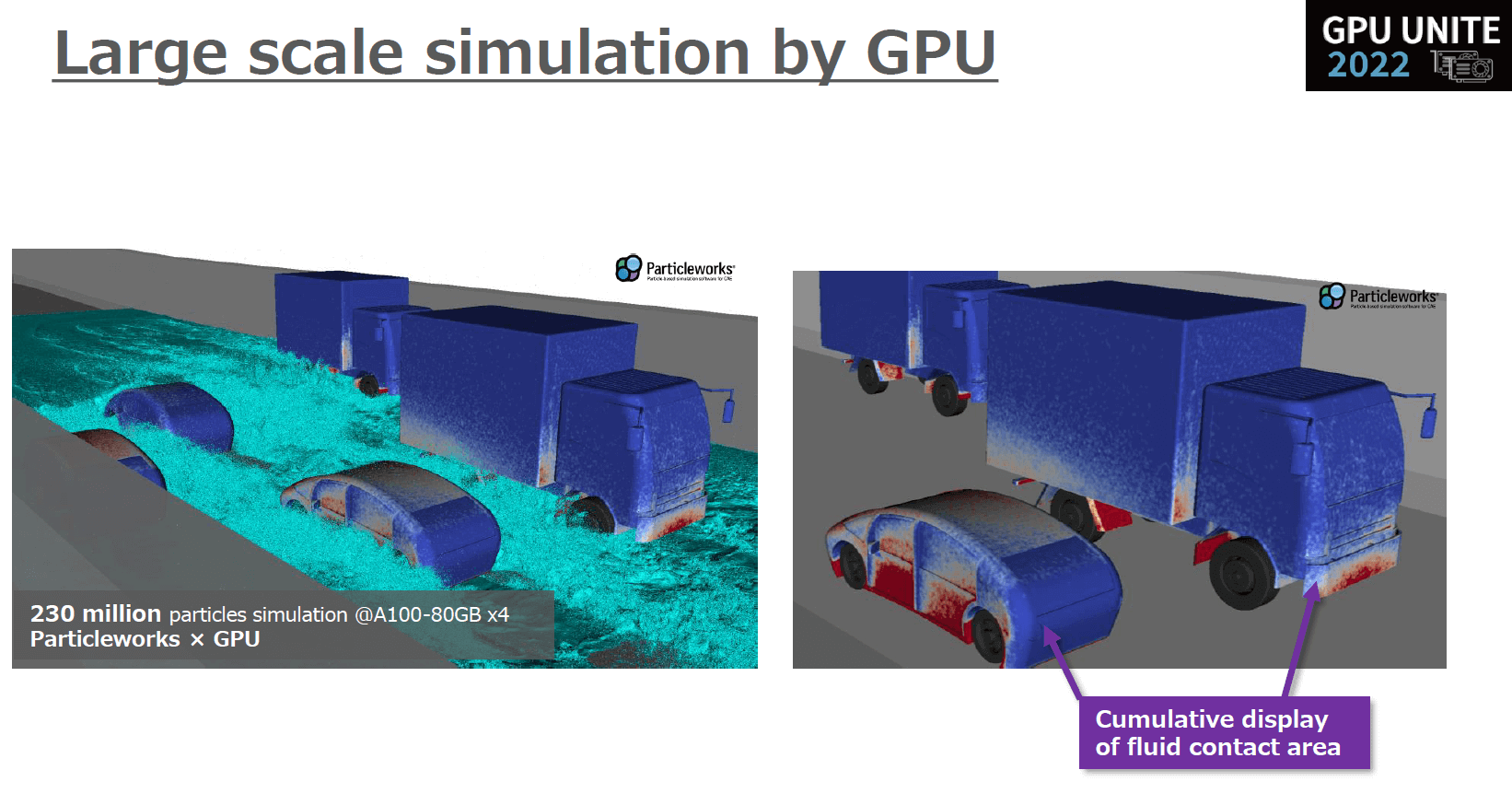
NVIDIA A100 80GB × 4 gpus
30cmほどの冠水状況で乗用車とトラック各3台がすれ違い走行した際のシミュレーションは、解像度が2億3000万粒子。
「実際のユースケースとしては、例えば水がよく当たっている部分を可視化し、実際に車体がどこまで浸水するのか、車体のどこに被水するのかなどを評価します。もちろん車体にかかる水圧も評価可能です。
こちらもギアオイルの解析と同様に、水の粒子が車体に付着した際の頻度をマッピングする機能を利用して評価しています。
GPUによる大規模解析 事例3

NVIDIA A100 80GB × 4 gpus
こちらは車両への水のかかり方だけでなく、車両周囲の環境である歩道や歩行者への被水影響を評価することを想定した解析を行っています。
10cmほど冠水したトンネル内を乗用車とトラックが通過する際のシミュレーション(1億6,000万粒子)では、隣接する歩道へどれだけ水が流れ込むかが解析できます。
また、解析評価に使うだけでなく、『SIMUNIMA』を介して例えば『Unity』や『Blender』などのソフトウェアでCG化して、よりリアルに可視化することも可能です」
NVIDIA A100 GPU により大規模解析が可能に
さらに横軸に粒子数、縦軸に解析終了までの計算時間をプロットしたグラフを提示。
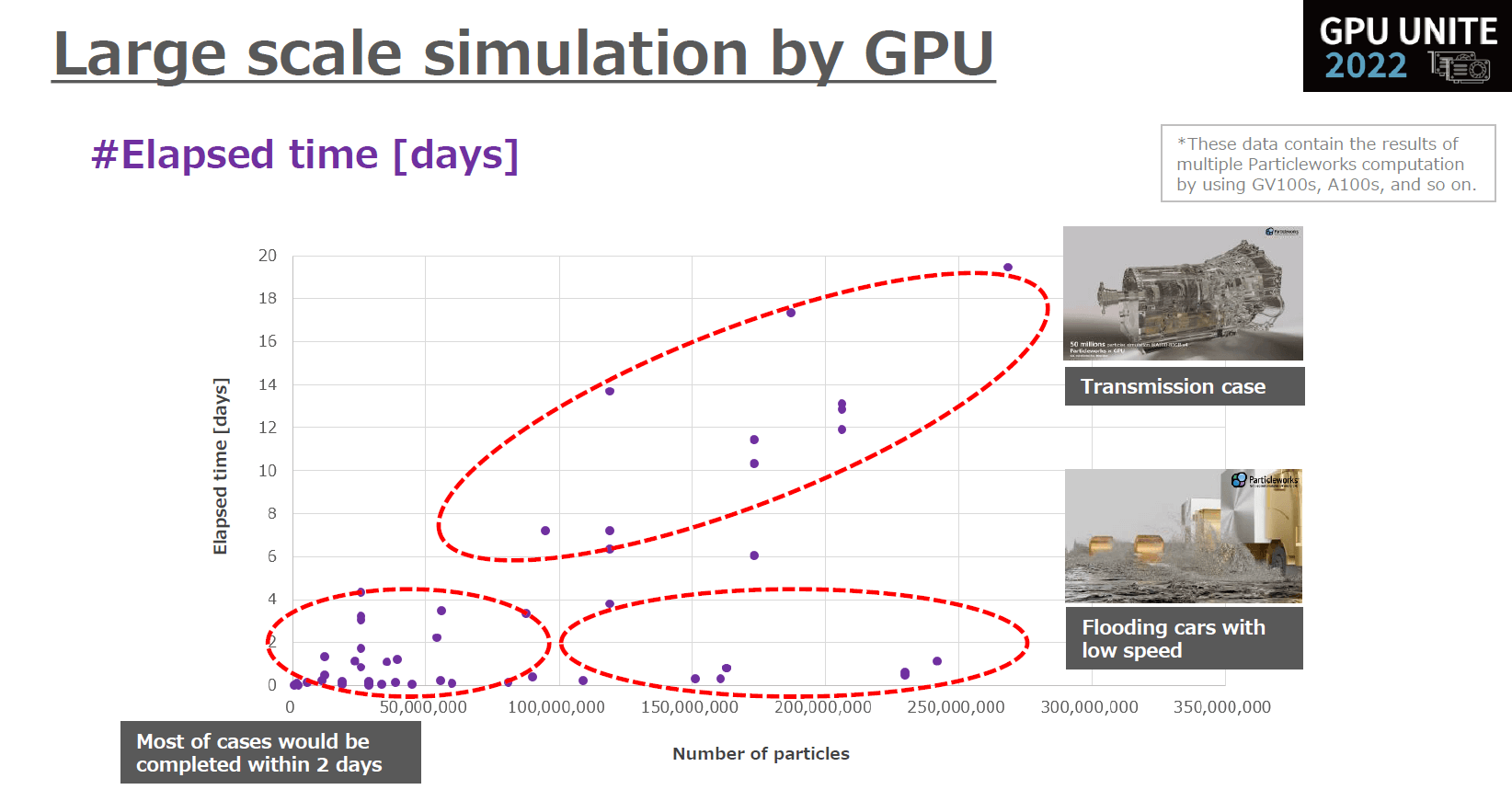
同じ解析スペックで期待通りの結果が得られることを保証するものではありません。
「解析時間は評価指標によっていくらでも変化しますので参考程度にご覧いただきたいのですが、
今回のデモンストレーション解析における各種解析の結果をクラスタリングすると、冠水路走行の解析などでは2億粒子クラスでもほとんどのケースにおいて約2日以内で解析が終わることが分かります。
トランスミッションで定常のトルクや回転数をトランジェントに変化させるような解析ケースでは評価に5日以上かかってしまうこともありますが、これは特殊なケースであり、シミュレーション全般に言える話だと思います。
GPUについては実装メモリにもよりますが、NVIDIA A100 GPU×2枚あれば1億5000万粒子程度の規模まで対応できますし、後にお話しするGPU水冷キット付きNVIDIA A100 GPU搭載ワークステーションであればデスクトップで1億5000万粒子規模の解析が実行できる環境が手に入ります。」と語りました。
解析時間の短縮により、冷却効率のシミュレーションにもトライ!
インタビューの終盤には、モーター開発における冷却解析シミュレーションを紹介してくれました。
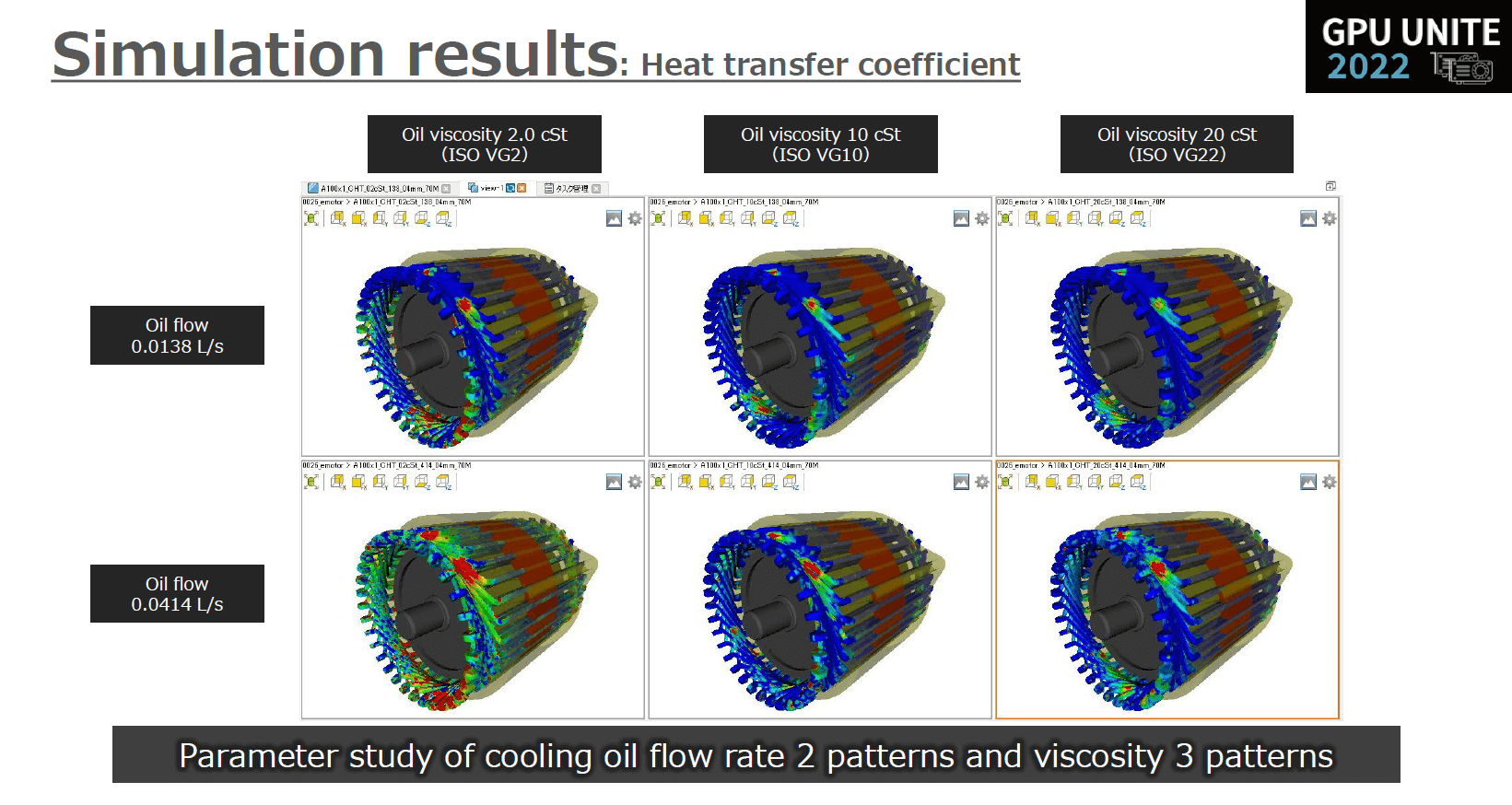
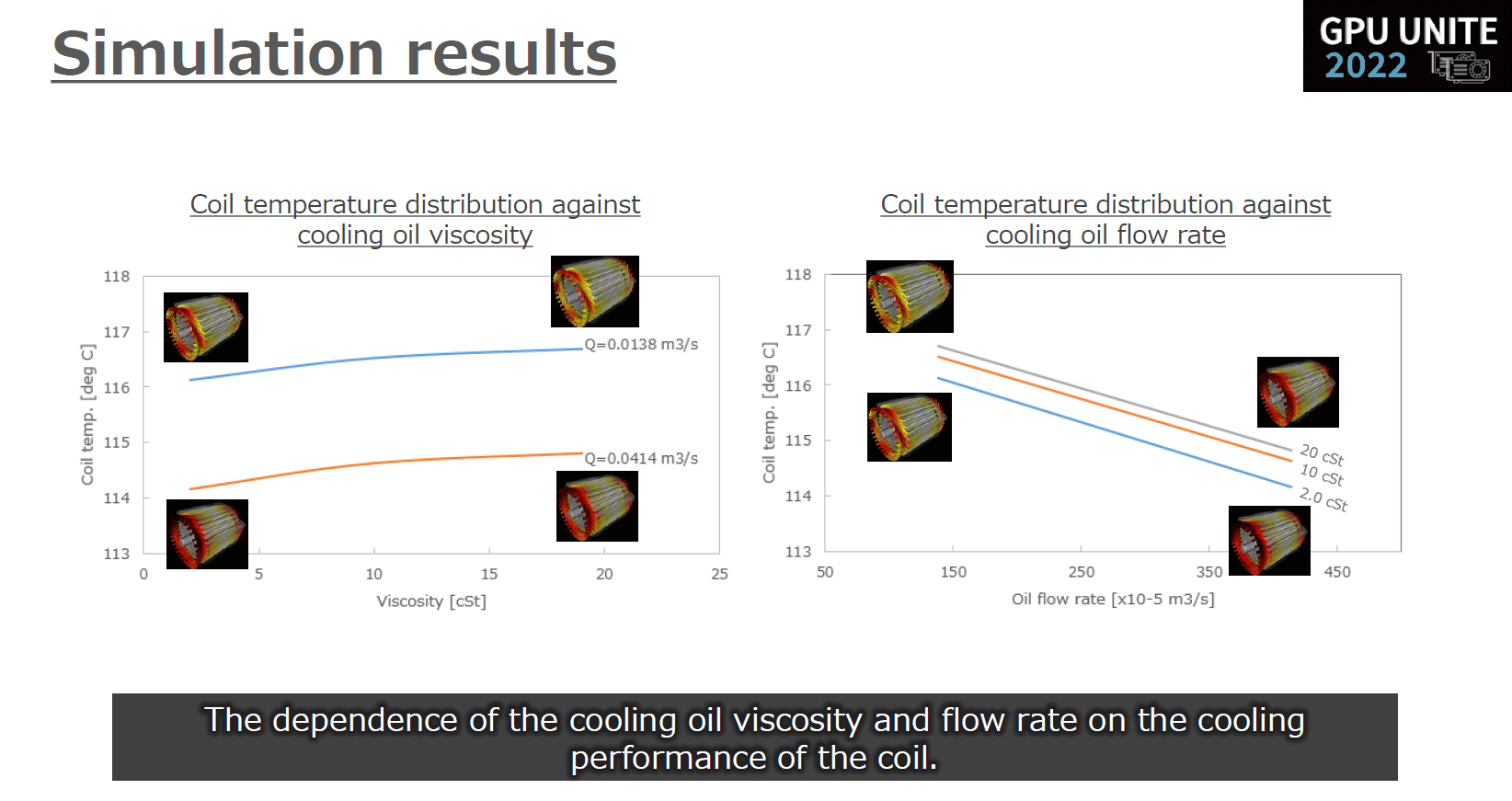
このシミュレーションでは、発熱部位であるコイルを直接冷却する油冷方法(スプラッシュクーリング)を想定してオイル冷却吐出口を設定。
オイルの粘度や油量を変えつつ、流体解析およびスプラッシュクーリングによる熱伝導解析を行っています。
「こちらのスライドではオイルの粘度や油量の組み合わせを6パターンしか表示していませんが、実際にはより多くの組み合わせをパラメータスタディしながら、最終的な冷却効率の傾向を出していく解析です」
水冷NVIDIA A100 GPUワークステーションを導入して
弊社オリジナルモデル『水冷 A100 GPU ワークステーション』を使った感想を聞きました。
「A100 GPUの演算速度は、ワークステーション搭載向けGPU「Quadro GV100」と比較して約20%向上、搭載メモリも32GB→80GBと性能向上しており、メモリ容量に依存する解析規模はこれまでの2倍以上に対応できるようになりました。

(GPU水冷キットには収納BOXが付属しています。)
現在使用しているワークステーションは2基の水冷A100を搭載しており、1億5000万粒子規模の解析がデスクトップワークステーションで解析できます。
筐体は通常のワークステーションに水冷ラジエータBOXが追加される程度なので、従来のワークステーションのリプレイスとして、デスクトップに設置しています。NVIDIA A100 がワークステーションで使える手軽さも気に入っています。」
GPUのコア数と搭載メモリはどちらがよりパフォーマンス向上に影響するのかを聞いたところ、
「一般には、計算速度はGPUメモリクロックやバンド幅に依存すると思います。一方で解析規模は、GPU搭載メモリ容量に依存します。」と回答。
さらに、流体計算は倍精度でシミュレーションをしなければ計算精度が得られないのかという問いには、
「数値計算の理屈上、倍精度で行わなければいけない解析は一部にありますが、解析の評価内容によっては単精度で実施しても問題ないものは存在します。例えばNVIDIA A100 GPUの単精度では1.5~2倍ほど扱える粒子数が変わってきますので、解析対象や評価指標に応じてすべてを倍精度で行う必要はないでしょう。」と答えてくれました。
最後に、読者の皆様に対するメッセージとして、「こうしたシミュレーションの様子は、WebサイトやSNSなどで動画コンテンツやWebセミナーとしても公開しています。流体・粉体解析、シミュレーション結果のCG制作に興味がある方は、お気軽にプロメテックまでお問い合わせください」と語り、インタビューを締めくくりました。
プロメテックWebサイト:https://www.prometech.co.jp
プロメテック動画コンテンツ:https://www.prometech.co.jp/web_seminar_outline_ja.html
弊社GDEPソリューションズでは、プロメテック・ソフトウェアが提供する製品・ソリューションが、ハードウェアで最適に稼働するよう検証も含め、サポートしています。
解析用途でのハードウェアの選定や導入は弊社にお任せください!
取材:GDEPソリューションズ株式会社
GPU導入事例 プロメテック 導入製品はこちら!
水冷 NVIDIA A100 GPUワークステーション

NVIDIA A100 GPUは、サーバー向けの筐体に搭載し、サーバー室への設置が一般的ですが、本製品は、ワークステーションの筐体に、水冷 A100 GPUを搭載し、冷却装置を使うことにより、GPUの温度上昇を防ぎ、かつ静音のため、デスクサイドで利用することができます。