- 1. NVIDIA HPC コンパイラとは
- 2. 各言語コンパイラについて
- 2.1. NVFORTRAN
- 2.2. NVC++
- 2.3. NVC
- 2.4. NVCC(いわゆる、CUDA C/C++コンパイラ)
- 3. NVIDIA HPCコンパイラは、何ができるの?
- 4. CPUの能力を引き出し、速い実行モジュールを作る
- 5. OpenMP並列プログラミングモデルを使用し、並列実行モジュールを作る
- 6. OpenACC並列プログラミングモデルを使用し、並列実行モジュールを作る
- 7. 最新のISO言語規格に準拠する構文による並列処理をサポートする
- 7.1. Fortran 2008標準並列プログラミング
- 7.2. C++17標準並列プログラミング
2022年8月
NVIDIA HPC コンパイラとは
NVIDIA HPC SDKスイートに含まれているHPCコンパイラは、Fortran、C++、C高級言語用のコンパイラとNVIDIA GPU専用のCUDA C/C++コンパイラ(ドライバー)となります。
前者のFortran、C++、Cコンパイラは、HPC業界で長い間、常にコンパイラ技術の先頭を歩んできたPGIの科学技術並びにエンジニアリング分野におけるフラグシップ・コンパイラの後継として、NVIDIAブランドで引き続き開発が続けられているものです。日本において多くのユーザにより利用されてきたPGIコンパイラの機能、オプション等は当該コンパイラに引き継がれ、その利用法において互換性を有しています。
本稿では、NVIDIA HPCコンパイラの中でFortran、C++、Cコンパイラに焦点を当てて説明することとします。
NVIDIA HPC コンパイラは以下のような特徴を持っています。
一言で言えば、現在、標準となっている並列プログラミングモデルに対応し、多種のCPUアーキテクチャと最新のNVIDIA GPU用に最適化・並列化コードを生成でき、ユーザにとってマルチプラットフォーム対応のプログラム開発ができるコンパイラです。
- FP16、TF32、FP64 tensor coresを含む最新のNVIDIA GPUアーキテクチャ用の最適化をサポート
- NVIDIA GPUおよびAMD、Intel、OpenPOWER、ArmのマルチコアCPU用アプリケーションの最適化、および並列化を可能とする
- C++17、Fortran 2008高級言語レベルでの並列化シンタックスへの対応、OpenACC、OpenMPによる並列プログラミングモデルに対応する
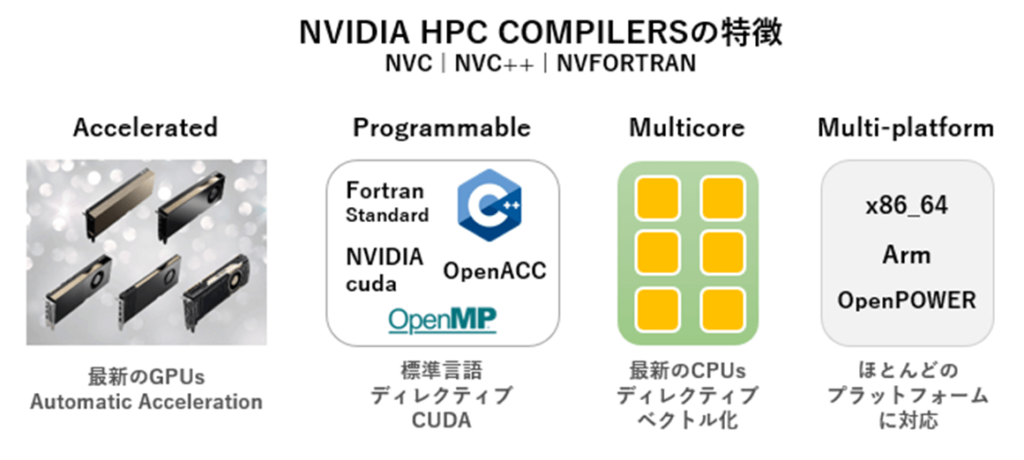
各言語コンパイラについて
次の表に、NVIDIA HPCコンパイラとそれに対応するコマンドを示します。
旧PGIコマンドを利用してコンパイルすることも可能です。
| コンパイラ名 | 言語規格、機能 | コマンド | 互換旧PGIコマンド |
| NVFORTRAN | ISO/ANSI Fortran 2003, CUDA Fortran | nvfortran | pgfortran or pgf90 |
| NVC++ | GNU互換性を有するISO/ANSI C++ 17 | nvc++ | pgc++ |
| NVC | ISO/ANSI C11 | nvc | pgcc |
| NVCC | CUDA C/C++ compiler driver | nvcc | なし |
3つのコンパイラ共に、NVIDIA GPUおよびAMD、Intel、OpenPOWER、およびArm CPU用に最適化可能な並列コンパイラです。
ターゲットとするプロセッサに対して各言語用のコンパイラ、アセンブラ、およびリンカを呼び出し、実行形式モジュール(executable)を生成します。
NVFORTRAN
NVFORTRANは、Fortranコンパイラです。
NVFORTRANは、ISO Fortran 2003およびISO Fortran 2008の多くの機能をサポートし、CUDA Fortranを使用したGPUプログラミング、およびISO Fortran並列言語機能、OpenACC、およびOpenMPを使用したGPUおよびマルチコアCPUプログラミングをサポートします。
当該コンパイラは、以下の言語規約に準拠する、FORTRAN77/fortran 90/95/2003コンパイラです。
- Fortran ANSI x3.9 1978, ISO/IEC 1539 : 1980 (FORTRAN77)
- ISO/IEC 1539-1 : 1991 (Fortran 90)
- ISO/IEC 1539-1 : 1997 (Fortran 95) 対応JIS規格 JIS X 3001-1:1998
- ISO/IEC 1539-1 : 2004 (Fortran 2003) 対応JIS規格 JIS X 3001-1:2009
- ISO/IEC 1539-1 : 2010 (Fortran 2008) 一部取込
- OpenACC 2.7、OpenMP 4.5
NVC++
NVC++は、GNU GCC g++ とABI 互換性を有するC++コンパイラです。
NVC++ はISO C++17をサポートし、C++17並列アルゴリズム、OpenACC、およびOpenMPを使用したGPUおよびマルチコアCPUプログラミングをサポートします。
当該コンパイラは、以下の言語規約に準拠する、ISO C++11/14/17コンパイラです。
- ISO/IEC 14882 : 2011 (ISO C++11)
- ISO/IEC 14882 : 2014 (ISO C++14)
- ISO/IEC 14882 : 2017 (ISO C++17)
- OpenACC 2.7、OpenMP 4.5
NVC
NVCは、Cコンパイラです。
NVCはISO C11をサポートし、OpenACCを使用したGPUプログラミングをサポートし、OpenACCおよびOpenMPを使用したマルチコアCPUプログラミングをサポートします。
当該コンパイラは、以下の言語規約に準拠する、ANSI C、ISO C90/C99/C11コンパイラです。
- ANSI X3.159-1989 (ANSI C)
- ISO/IEC 9899 : 1990 (C90)
- ISO/IEC 9899 : 1999 (C99)
- ISO/IEC 9899 : 2011 (C11)
- OpenACC 2.7、OpenMP 4.5
NVCC(いわゆる、CUDA C/C++コンパイラ)
nvcc は、NVIDIA GPU 用のドメイン固有の言語CUDA C および CUDA C++ のコンパイラ・ドライバです。
nvcc は、マクロやインクルード/ライブラリパスの定義、コンパイル・プロセスの操作など、さまざまな従来のコンパイラ・オプションを受け入れます。nvcc は、NVIDIA GPU 用に最適化されたコードを生成し、AMD、Intel、OpenPOWER、および Arm CPU 用にサポートされているホスト・コンパイラを駆動します。
なお、本稿では、CUDA C/C++コンパイラについては説明しません。
NVIDIA HPCコンパイラは、何ができるの?
NVIDIA HPCコンパイラは、CPU/GPUの能力を引き出しアプリケーションの性能を高めることを目的に、主に以下の機能を有します。
- マルチコアCPU用に性能最適化を行えます。
- OpenMP並列プログラミングモデルを使用して、マルチコアCPU並びにGPU用のマルチスレッド並列実行可能モジュールを生成できます。
- OpenACC並列プログラミングモデルを使用し、GPU並びにマルチコアCPU用の並列実行可能モジュールを生成できます。
- 標準言語による並列処理をサポートします。C++ コンパイラである NVC++ は、NVIDIA GPU およびマルチコア CPU 向けの C++17、C++ 標準並列処理 (stdpar)をサポートします。また、FortranコンパイラであるNVFORTRANは、ISO 標準 Fortran 2008 のDO CONCURRENTによるループレベルの並列処理をNVIDIA GPU およびマルチコア CPU向けに行えます。
CPUの能力を引き出し、速い実行モジュールを作る
コンパイラの最適化機能によって性能がどの程度変化していくのか、以下のFortranプログラムを例に測定してみましょう。
ここで測定に用いたシステムは、筆者のWindowsノートPCにWSL 2 (Windows Subsystem for Linux 2)を構築し、その中にNVIDIA HPC SDKを実装した環境を使いました(手軽に使える環境でテストしています)。
CPUは、Intel Core i7-9750H @2.60GHzで、ベクトルストリーミングSIMDとしてavx/avx2機構を備えています。
以下のプログラムは、単純な配列(ベクトル)の加算処理を行っているものです。
$ cat vadd.f90
program vector_op
parameter (N = 9999)
real*4 x(N), y(N), z(N), W(N)
do i = 1, n
y(i) = i
z(i) = 2*i
w(i) = 4*i
end do
do j = 1, 2000000
call loop(x,y,z,w,1.0e0,N)
end do
print *, x(1),x(771),x(3618),x(6498),x(9999)
end
subroutine loop(a,b,c,d,s,n)
integer i, n
real*4 a(n), b(n), c(n), d(n), s
do i = 1, n
a(i) = b(i) + c(i) - s * d(i)
end do
end
最初に、最適化オプションを何も指定しないで、実行してみます。実行時間は39秒掛かっています。
$ nvfortran -Minfo vadd.f90 -o vadd
loop:
18, FMA (fused multiply-add) instruction(s) generated
$ /bin/time vadd
-1.000000 -771.0000 -3618.000 -6498.000
-9999.000
39.28user 0.00system 0:39.28elapsed 99%CPU (0avgtext+0avgdata 5140maxresident)k
40inputs+0outputs (1major+312minor)pagefaults 0swaps
次に、一般に最適化を指示する際に使用する -02オプションをして実行します。
最適化レベル2は、レベル1のローカル最適化とレベル2のグローバル最適化をすべて実行します。さらに、ベクトルストリーミングSIMDコード生成、キャッシュ・アライメント、部分的な冗長性の排除など、より高度な最適化が有効になるモードです。
何と、2.84秒で終了しています。
最適化により、14倍近く高速化されています。-02最適化では、配列の計算処理においてSIMDインストラクションを適用しますので、ベクトル化されたコードが生成されています。
コンパイルメッセージにも、ソースコード17行目で「Generated vector simd code for the loop」と記されています。
$ nvfortran -Minfo vadd.f90 -o vadd-O2 -O2
vector_op:
4, Generated vector simd code for the loop
9, Loop not vectorized/parallelized: contains call
loop:
17, Generated vector simd code for the loop
18, FMA (fused multiply-add) instruction(s) generated
$ /bin/time vadd-O2
-1.000000 -771.0000 -3618.000 -6498.000
-9999.000
2.84user 0.00system 0:02.84elapsed 99%CPU (0avgtext+0avgdata 5288maxresident)k
一方、SIMDコード生成の無効化して実行してみます。
-Mvect=nosimd を -02 オプションの後に指定すると、-02に包括されたベクトル化を無効とすることができます。
この場合の実行時間は4.12秒でした。
SIMDコードの方が非SIMDコードより早いことが分かりません。使用したCPUがAVX2のため、この程度の差かもしれませんが、AVX-512を有する場合はより高速に実行できるでしょう。
$ nvfortran -Minfo vadd.f90 -o vadd-nosimd -O2 -Mvect=nosimd
vector_op:
4, Loop unrolled 8 times
9, Loop not vectorized/parallelized: contains call
loop:
17, Loop unrolled 4 times
FMA (fused multiply-add) instruction(s) generated
18, FMA (fused multiply-add) instruction(s) generated
$ /bin/time vadd-nosimd
-1.000000 -771.0000 -3618.000 -6498.000
-9999.000
4.12user 0.00system 0:04.13elapsed 99%CPU (0avgtext+0avgdata 5304maxresident)k
40inputs+0outputs (1major+314minor)pagefaults 0swaps
以上の例のように、コンパイラの最適化オプションを適用することにより、高速な実行形式モジュールを作ることができます。
OpenMP並列プログラミングモデルを使用し、並列実行モジュールを作る
マルチコアCPUに対応した並列化は、ソースプログラムにOpenMPディレクティブを適用することにより可能となります。
さらに、GPUをターゲティングとした並列化されたオフロード・コードの作成も可能です
ここでは、OpenMP 4.x以降にサポートされたGPU(アクセラレータ)用のコード生成について簡単に説明します。
以下は、DAXPYのプログラムです。ループ処理の前に、OpenMPのオフロード用のディレクティブを挿入しています。
#include <stdlib.h>
int main() {
size_t n = 200000000;
double *A = (double*) malloc(n*sizeof(double));
double *B = (double*) malloc(n*sizeof(double));
double *C = (double*) malloc(n*sizeof(double));
double scalar = 2;
#pragma omp target teams loop
for (size_t i = 0; i < n; i++) {
B[i] = 1;
C[i] = i;
}
#pragma omp target teams loop
for(size_t i = 0; i < n; i++) {
A[i] = B[i] + scalar * C[i];
}
free(A);
free(B);
free(C);
return 0;
}
OpenMPにて、CPU および GPU ターゲットを有効にするコマンドライン・オプションは、-mp=gpu あるいは、-mp=multicoreです。
前者の -mp=gpuオプションは、GPU 実行とマルチコア CPUフォールバック用にコンパイルされます。この機能は、NVIDIA V100 以降の GPU でサポートされています。
後者の -mp=multicoreオプションは、マルチコア CPU 実行用にのみコンパイルされます。このサブオプションがデフォルトとなります。
GPU用にコンパイルした際のメッセージは以下の通りです。GPUカーネルコードを生成していることが分かります。
$ nvc++ -mp=gpu -Minfo=mp -fast triad.cpp
main:
8, #omp target teams loop
8, Generating "nvkernel_main_F1L8_2" GPU kernel
Generating NVIDIA GPU code
11, Loop parallelized across teams, threads(128) /* blockIdx.x threadIdx.x */
8, Generating Multicore code
11, Loop parallelized across threads
8, Generating implicit map(from:C[:200000000],B[:200000000])
11, Generated vector simd code for the loop
14, #omp target teams loop
14, Generating "nvkernel_main_F1L14_4" GPU kernel
Generating NVIDIA GPU code
17, Loop parallelized across teams, threads(128) /* blockIdx.x threadIdx.x */
14, Generating Multicore code
17, Loop parallelized across threads
14, Generating implicit map(from:A[:n])
Generating implicit map(to:B[:n],C[:n])
17, Generated vector simd code for the loop
18, FMA (fused multiply-add) instruction(s) generated
一方、マルチコアCPUをターゲットとした場合のメッセージは以下のように示されます。
$ nvc++ -mp=multicore -Minfo=mp -fast triad.cpp
main:
8, #omp target teams loop
8, Generating Multicore code
11, Loop parallelized across threads
14, #omp target teams loop
14, Generating Multicore code
17, Loop parallelized across threads
NVIDIA HPCコンパイラは、OpenMP 4.5オフロードをサポートしていますが、NVIDIA GPUを対象とした場合、GPU 向けに適切に構造化されていないコードは、パフォーマンスが低下する可能性があります。
OpenMP規格としてオフロード機能のリリースがOpenACCよりかなり遅れたこともあり、現時点では実用的域に達していないと言わざるを得ません。
GPUに最適な並列化機能と性能を提供できるプログラミングモデルは、次に述べるOpenACCとなりますので、その概要を説明します。
OpenACC並列プログラミングモデルを使用し、並列実行モジュールを作る
GPU用の並列実行形式モジュールをCUDA C/C++、CUDA Fortranプログラミングモデルで作成する時代は終わりました。
もちろん、性能チューニングをしたい部分だけをCUDA言語にて最適化コードを作成する場合はありますが、現在のプログラム開発方法は、対象プログラムにOpenACCディレクティブを挿入し、段階的にGPU計算適用箇所(GPUに処理をオフロードする部分)を増やしていくスタイルが一般的です。
OpenACCプログラミングモデルは実用に供されてから10年以上経過しており、コンパイラとしての実装も成熟しつつしつつあります。高速な計算を行うことにより処理のスループットの改善を行いたいユーザは、GPUの計算能力を活用するために簡単に適用できるOpenACCを使用してみることをお勧めします。
以下のプログラムは、配列(ベクトル)の加算を行う単純なCプログラムです。
この中に、OpenACCディレクティブが2行挿入されています(黄色でマーキングされている行です)。
これだけで、GPUで計算処理できるコードが作成可能となります。
ディレクティブの挿入箇所は多くの場合、計算時間が掛かるループ(ホットスポット)が対象となります。
#include <stdio.h>
#include <stdlib.h>
void vecaddgpu( float *restrict r, float *a, float *b, int n ){
#pragma acc kernels loop present(r,a,b)
for( int i = 0; i < n; ++i ) r[i] = a[i] + b[i];
}
int main( int argc, char* argv[] ){
int n; /* vector length */
float * a; /* input vector 1 */
float * b; /* input vector 2 */
float * r; /* output vector */
float * e; /* expected output values */
int i, errs;
if( argc > 1 ) n = atoi( argv[1] );
else n = 100000; /* default vector length */
if( n <= 0 ) n = 100000;
a = (float*)malloc( n*sizeof(float) );
b = (float*)malloc( n*sizeof(float) );
r = (float*)malloc( n*sizeof(float) );
e = (float*)malloc( n*sizeof(float) );
for( i = 0; i < n; ++i ){
a[i] = (float)(i+1);
b[i] = (float)(1000*i);
}
/* compute on the GPU */
#pragma acc data copyin(a[0:n],b[0:n]) copyout(r[0:n])
{
vecaddgpu( r, a, b, n );
}
/* compute on the host to compare */
for( i = 0; i < n; ++i ) e[i] = a[i] + b[i];
/* compare results */
errs = 0;
for( i = 0; i < n; ++i ){
if( r[i] != e[i] ){
++errs;
}
}
printf( "%d errors found\n", errs );
return errs;
}
コード生成までをイメージするため、実際のコンパイラのコマンドラインを以下に示しました。
-accオプションは、OpenACCディレクティブを認識することを指示し、-fastは最適化コードの生成を指示します。
また、-Minfo=accelはアクセラレータに係るメッセージを出力させることを指示しています。
このコマンドによって、GPUを利用して動作する実行形式モジュールが生成されます。
$ nvc -acc -fast -Minfo=accel vadd.c -Msafeptr
vecaddgpu:
4, Generating present(b[:],r[:],a[:])
6, Loop is parallelizable
Generating NVIDIA GPU code
6, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
main:
30, Generating copyin(a[:n]) [if not already present]
Generating copyout(r[:n]) [if not already present]
Generating copyin(b[:n]) [if not already present]
もう一つ、大事なことがあります。
コマンドライン・オプションを変えることによって、OpenACCプログラムは、マルチコアCPU用のスレッド並列コードの生成も可能となります。
以下の -acc=multicoreオプションによりこれを実現します。
$ nvc -acc=multicore -fast -Minfo=accel vadd.c -Msafeptr
vecaddgpu:
6, Loop is parallelizable
Generating Multicore code
6, #pragma acc loop gang
以上のように、OpenACCはGPU用だけでなくマルチコアCPU用の並列実行形式プログラムを作成できる、マルチプラットフォームを意識したプログラミングモデルですので、今後、活用される場面が増えていくと思います。
NVIDIA HPC コンパイラは、OpenACCのコンパイラ技術においては最も長い開発実績を有しております。
また、新しく開発されるNVIDIA GPUデバイス機能に随時対応するため、NVIDIA GPUを利用する場合の開発コンパイラとしては最適なものと思います。
もちろん、一般的なCPU用のコンパイラ機能も有し無償で使用できることもあり、パーソナルユースとして利用することもできます。
最新のISO言語規格に準拠する構文による並列処理をサポートする
今までC++ やFortran開発者は、CUDA C/C++やCUDA Fortran または OpenACC を使用して、GPU用にプログラムを高速化することができました。
今、ISO言語規格C++/Fortranの標準並列プログラミング構文を用いて、NVIDIA GPU のフルパワーを活用できるようになりました。
標準のC++、Fortran の構文で並列処理を記述できるようになり、他のコンパイラやシステムへの完全な移植性を維持しながら、NVIDIA GPU のパワーを活用できます。
こうした方向性は、ユーザが移植に費やす時間を減らして、本当に重要なこと、つまり計算科学で世界の問題を解決することに多くの時間を費やすことができるよう、プログラム開発の現場も変化していくことを示しています。
ISO 標準言語には安定性と移植性に関して実績があるため、コードの将来性を保証します。
将来的にサポートが失われる可能性はほとんどないという利点があります。
Fortran 2008標準並列プログラミング
最初に、Fortranの状況について説明します。
ISO規格Fortran 2008では、Fortran言語で並列性を直接表現する様々な仕組みのうち、ループレベルの並列性を表現できるDO CONCURRENT構文が導入されました。
以下は do concurrent構文を使用した例です。
多重ループを1行で記述できます。シンプルな見栄えの良いコードを作成できます。
なお、コンパイラはデータの依存関係がある場合でもループを並列化するため、競合状態が発生し、誤った結果になる可能性があります。ループを安全に並列化できるようにするのは、ユーザの責任です。
do iter = 1, niters
do concurrent(i=2:n-1, j=2:m-1)
a(i,j) = w0 * b(i,j) + &
w1 * (b(i-1,j) + b(i,j-1) + b(i+1,j) + b(i,j+1)) + &
w2 * (b(i-1, j-1) + b(i-1,j+1) + b(i+1,j-1) + b(i+1,j+1))
enddo
do concurrent(i=2:n-1, j=2:m-1)
b(i,j) = w0 * a(i,j) + &
w1 * (a(i-1,j) + a(i,j-1) + a(i+1,j) + a(i,j+1)) + &
w2 * (a(i-1,j-1) + a(i-1,j+1) + a(i+1,j-1) + a(i+1,j+1))
enddo
enddo
このプログラムを -stdpar オプションでコンパイルするとGPU用コードが生成されます。
これにより、NVIDIA GPU での並列処理が可能になります。
並列化に関する詳細情報を表示するには、-Minfoオプションを指定します。
$ nvfortran -fast -Minfo jacobi.f90 -stdpar
28, Generating NVIDIA GPU code
28, ! blockidx%x threadidx%x auto-collapsed
Loop parallelized across CUDA thread blocks, CUDA threads(128) collapse(2) ! blockidx%x threadidx%x collapsed-innermost
33, Generating NVIDIA GPU code
33, ! blockidx%x threadidx%x auto-collapsed
Loop parallelized across CUDA thread blocks, CUDA threads(128) collapse(2) ! blockidx%x threadidx%x collapsed-innermost
マルチコアCPU用のスレッド並列コードを生成したい場合は、-stdpar=multicore を指定します。
$ nvfortran -fast -Minfo=accel jacobi.f90 -stdpar=multicore
smooth:
28, Generating Multicore code
28, Loop parallelized across CPU threads
33, Generating Multicore code
33, Loop parallelized across CPU thread
標準言語での並列化(-stdpar)を行ったプログラムであっても、OpenACCのディレクティブを挿入することにより、機能の共存ができます。
例えば、データの移動管理を細かくOpenACCを使って制御したい場合があります。こうした場合は、以下のようなコマンドライン・オプションで複数の並列プログラミングモデル(この場合は -stdparと -acc)を適用することができます。
このオプションの意味はともかくとして、細かな制御ができるということを覚えておいてください。
これについては、今後、説明することにします。
$ nvfortran -fast -Minfo jacobi.f90 -stdpar=gpu -acc=gpu -gpu=nomanagedC++17標準並列プログラミング
次に、C++言語の標準並列プログラミングの状況について説明します。
C++言語では、C++17 standardの時点で、多くのアルゴリズムの並列バージョンが標準ライブラリとして提供されています。
C++はソート、検索、累積和などの一般的なタスクに対して並列アルゴリズムを提供し、次期バージョンではさらにドメイン固有のアルゴリズムのサポートを追加する可能性があるため、ライブラリベースで開発する並列化のアプローチのように機能します。
さらに、手書きによる並列ループのための形態として、汎用的な for_each や transform_reduce アルゴリズムという形で提供されています。
C++の並列アルゴリズムは、非標準の拡張ではなく、言語のネイティブな構文によって並列性を表現します。
これによって、開発したソフトウェアの長期的な互換性と移植性を保証しているのです。
この手法の斬新な点は、既存のコードベースにシームレスに統合することができることです。
この方法では、段階的に重要なプログラム・コンポーネントの性能を選択的に高速化することができます。すなわち、一部のアルゴリズムをGPUで実行し、一部のアルゴリズムをCPUで維持するハイブリッドアプローチが可能となります。
C++プログラムのGPUへの移植は、すべての for ループを for_each の呼び出しに置き換えるだけでよく、リダクションを含む場合は transform_reduce に置き換えるだけでよいのです。
標準C++ 並列アルゴリズムの多くは、アルゴリズムへの追加引数として提供される、以下に示す「実行ポリシー」の助けを借りて、ホストまたはデバイス上で並列に実行させることができます。
- std::execution::seq:順次実行。並列処理は行わない。
- std::execution::par:1つ以上のスレッドでの並列実行。
- std::execution::par_unseq:1つ以上のスレッドでの並列実行。また、各スレッドがベクトル化される可能性がある。
標準C++ 並列アルゴリズムを使用例として、適切なコンテナに格納されたアイテムをソートする例を見てみましょう。
std::sort(employees.begin(), employees.end(),
CompareByLastName());
C++ 並列アルゴリズムを使えばこのソートの並列化は簡単にできます。<execution> をインクルードして、関数呼び出しに実行ポリシーを追加します。
std:sort(std::execution::par,
employees.begin(), employees.end(),
CompareByLastName());
コンテナ内の全要素の合計を計算するのも、std::accumulate アルゴリズムを使えば簡単です。
C++17以前では、合計を取る間に何らかの方法でデータを変換することは、やや厄介でした。
例えば、従業員の平均年齢を計算する場合、次のようなコードを書くことになります。
int ave_age =
std::accumulate(employees.begin(), employees.end(), 0,
[](int sum, const Employee& emp){
return sum + emp.age();
})
/ employees.size();
C++17で導入されたstd::transform_reduceアルゴリズムにより、このコードを簡単に並列化することができます。
また、リダクション操作(この場合はstd::plus)を変換操作(この場合はemp.age())から分離することにより、よりクリーンなコードになります。
int ave_age =
std::transform_reduce(std::execution::par_unseq,
employees.begin(), employees.end(),
0, std::plus<int>(),
[](const Employee& emp){
return emp.age();
})
/ employees.size();
C++ 並列アルゴリズムのGPUアクセラレーションは、nvc++ の-stdpar=gpuコマンドライン・オプションで有効化されます。
stdpar=gpuが指定された場合(または引数なしの-stdpar)、並列実行ポリシーを使用するほぼすべてのアルゴリズムが、NVIDIA GPU上で並列実行するためのオフロード用にコンパイルされます。
$ nvc++ -stdpar=gpu program.cpp -o program
$ nvc++ -stdpar program.cpp -o program
C++ 並列アルゴリズムをマルチコアCPUで高速化するには、NVC++のコマンドライン・オプション
-stdpar=multicoreを使用します。
stdpar=multicoreを指定すると、並列実行ポリシーを使用するすべてのアルゴリズムがマルチコアCPUで実行されるようにコンパイルされます。
$ nvc++ -stdpar=multicore program.cpp -o programC++ 標準並列プログラミングを使用して並列化が簡単にできる一方、性能を追求するためには、C++というオブジェクト指向のアプローチとは逆のデータ指向の設計で、プログラムをリファクタリングする必要も出てきます。
これは、性能を大きく左右するメモリアクセスの最適化を考えた場合、データの構造とレイアウトに中心的な重要性を見出し、この構造に基づいてデータ処理アルゴリズムを構築することを意味します。

