Excel方眼紙・複雑PDFにも対応
RAGの回答精度を大幅に向上する「G-RAGon」搭載モデル
「RAGの回答精度がなかなか上がらない」「チューニングに多くの工数がかかる」
――こうしたお客様の課題を解決するため、独自にRAG回答精度改善ツール
「G-RAGon(ジー・ラグ・オン)」を開発しました。
独自のChunking(文書分割)とプロンプト最適化により、初期回答精度を大幅に向上。
Excel方眼紙や複雑なPDFといった、日本企業特有のドキュメントにも対応し、
実業務で使えるRAG環境を実現します。
(Word文書においては初期回答精度 90%を達成 ※1)
「LLM/RAG 業務活用セット」は、NVIDIA GPU搭載ワークステーションに、
生成AIモデルやRAG開発ツールと連携可能な形で「G-RAGon」を標準搭載したモデルです。
※1 当社社内チャットボット検証結果
RAGの構築で、こんな課題はありませんか?
- RAGの回答精度が低く、手作業での調整が必要
- Difyの自動分割では、検索精度が向上しない
- 日本語処理の難しさ(同義語や表現の揺れ、多様な言い回し等)が原因で回答精度が不安定
- RAGのアップグレード時に、ナレッジデータが失われ、再登録の手間がかかる
- 試行錯誤で回答精度を上げるには時間と労力がかかる
「G-RAGon」で解決!
「LLM/RAG 業務活用セット」には「G-RAGon」がプレインストールされています。
導入後すぐに精度向上を実現し、RAG構築の負担を大幅に削減します。
新機能! Excel方眼紙・複雑PDF対応
日本企業で多く利用されるExcel方眼紙や、複雑な表構造を含むPDF文書にも対応。
独自のChunking処理により文書構造を維持したままRAGに組み込むことで、
従来課題となっていた回答精度の低下を大幅に改善します。
・Excel方眼紙:6% →78%
・PDF文書:47% → 82%
なお、Word文書においては従来より初期回答精度 90%を達成しています。
※自社検証結果
Chunking自動最適化機能
「Dify」のChunking機能を凌駕する独自ツールにより初期回答精度を大幅に向上。
自社チャットボットで90%の回答精度達成!
自社チャットボット開発過程で明らかになった、RAGの課題をひとつひとつ解決し、得られた知見をG-RAGonに詰め込みました!
RAG運用ツールを付属
RAGの業務運用に必須となる2つの機能をサポート
(1)「OpenWebUI」と「Dify」の連携設定により、ユーザ管理機能をサポート
(2)ナレッジデータのバックアップリストア機能をサポート
対応ファイル形式
「G-RAGon」は、RAG応答精度の向上と運用支援を目的としたツールであり、以下のファイル形式から高精度なナレッジベースを構築可能です。
Microsoft Excel形式 (.xlsx)
→ Excel方眼紙にも対応し、構造を維持したままRAGに組み込み可能
(検証により初期回答精度 6% → 78%に向上)
PDF形式 (.pdf)
→ 表構造を保持したチャンキングにより、複雑なPDF文書でも高精度な回答を実現
(検証により初期回答精度 47% → 82%に向上)
Microsoft Word形式 (.docx)
→ 従来より高い精度を実現し、検証により初期回答精度90%を達成
(当社社内チャットボット検証結果)
LLM/RAG業務活用セットの構成
1. ハードウェア構成 | 高性能GPU搭載で安心のLLM/RAG運用
高性能GPUと信頼性の高いハードウェア構成を採用。LLMやRAGに求められる計算処理を、安定かつ快適にこなすGPUワークステーションです。

[ミッドレンジ搭載GPU]

[ミッドレンジ ワークステーション]
| エントリー | ミッドレンジ | |
| ワークステーション | HP Z4 G5 Workstation | HP Z8 Fury G5 Workstation |
| GPU用PCIe Slot | Gen 5x16 x1Slot | Gen 5x16 x2Slot Gen 4x16 x2Slot |
| 計算用GPU | NVIDIA RTX PRO 4500 [32GB] × 1基 | NVIDIA RTX PRO 6000 Max-Q [96GB] × 1~3基 |
| CPU | インテル® Xeon® w3-2435 プロセッサー (3.1GHz 最大4.5GHz / 8コア / 22.5MB / 4400MHz) | インテル Xeon w5-3535X プロセッサー (2.9GHz 最大4.8GHz / 20コア / 52.5MB / 4800MHz) |
| システムメモリ* | 64GB ~ 512GB | 64GB ~ 1,024GB |
| SSD | 1TB ×2 HP Z Turboドライブ G2 (内蔵M.2スロット接続 TLC NVMe SSD) | 1TB ×1 , 2TB ×1 HP Z Turboドライブ G2 (内蔵M.2スロット接続 TLC NVMe SSD) |
| HDD * | 4TBハードディスクドライブ (SATA / 7200rpm) | |
| OS | Ubuntu 24.04 | |
| 光 学ドライブ | DVD-RW | |
| キーボード、マウス | 標準添付 | |
| モニター | なし | |
| 保守 | 保証3年 | |
| 筐体サイズ | 幅 169 mm × 奥行 445 mm × 高さ 386 mm | 幅 216 mm × 奥行 556 mm × 高さ 445 mm |
| 電源 | 775 W | 2250 W |
*システムメモリ、HDDは増設することができます。
2. LLM/RAGプレインストールソフトウェア | 手間なく導入、すぐに開発スタート
最新のLLMモデル、ChatGPTライクなUI、LLMアプリ開発プラットフォーム「Dify」などを事前にプレインストール・セットアップし、LLM/RAG環境構築の手間を大幅に削減します。
また業務活用セット「ミッドレンジモデル」には、「Dify」の回答精度を改善し、業務運用を効率化するツール「G-RAGon」が標準搭載されています。
| エントリー | ミッドレンジ | |
| ユーザインターフェース/ AIアプリケーション開発ツール | Open WebUI / Dify | |
| AIモデル実行ツール | Ollama / Xinference | |
| 生成AIモデル | ||
| Meta Llama 3 | 8Bモデル | 8B / 70Bモデル |
| Meta Llama 3.2 Vision | 11Bモデル | |
| Meta Llama 3.3 | - | 70Bモデル |
| Meta Llama 4 scout | - | 17B-16E モデル |
| Google Gemma 2 | 9Bモデル | |
| Google Gemma 3 | 12Bモデル | 12B / 27Bモデル |
| Microsoft Phi-4 | 14Bモデル | |
| OpenAI gpt-oss | 20Bモデル | 20B / 120Bモデル |
| Qwen 2.5 | 14Bモデル | |
| Qwen 3 | 14Bモデル | 14B / 32Bモデル |
| QwQ | - | 32Bモデル |
| その他ツール | ||
| RAG精度改善ツール *独自開発 | G-RAGon | |
| パートナーアプリ | blueqatRAG | |
| Embeddingモデル | nomic-embed-text | |
| Rerankingモデル | bge-reranker-v2-m3 | |
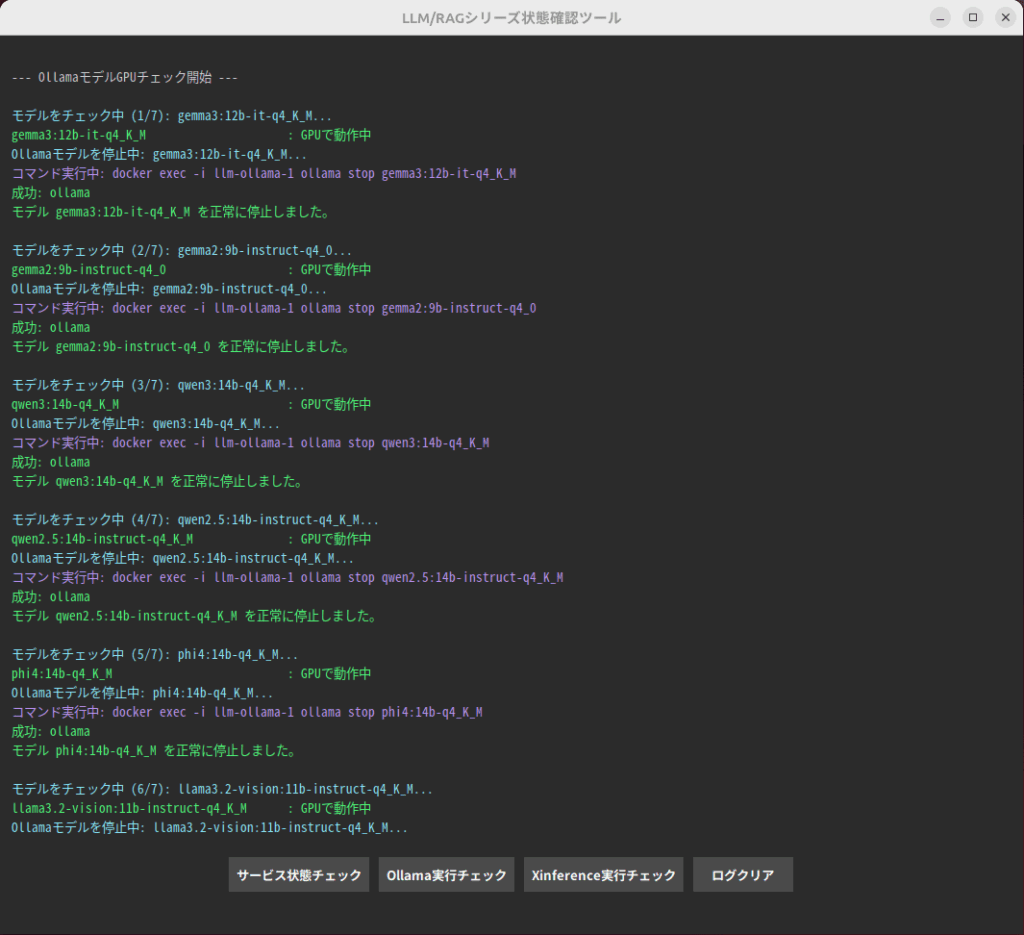
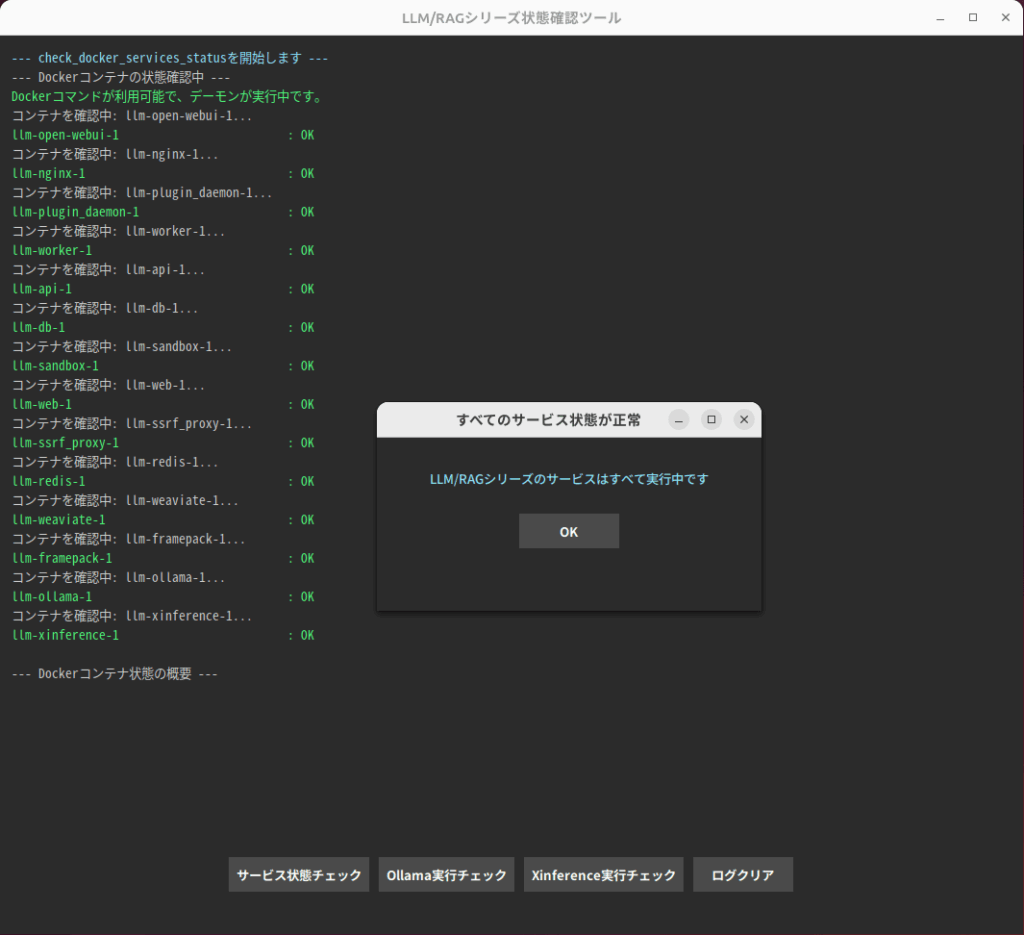
LLM/RAGシリーズ管理ツール(独自開発)
LLM/RAGシリーズには、サービス状態チェックや生成AIモデルの動作チェックなど、システム管理者向けの管理ツールも同梱されています。
LLM/RAGシリーズ約款PDF
LLM/RAGシリーズ仕様書PDF
3. サポートについて | 安心して始められる
当社では、お客様が安心してLLM/RAGシステムを導入いただけるよう、充実したサポート体制を整えています。
導入時のサポートもワンストップでご提供
- システム環境構築:ハードウェア・ソフトウェア専門エンジニアが予めセットアップして出荷
- 各ツール動作確認:Dify、OpenWebUI、各種生成AIモデルの基本機能の動作確認実施済み
- 使い方マニュアル:初期操作をカバーするマニュアルを同梱
- Q&Aチケット:マニュアルの不明点や実際の操作に関する疑問を解決
カスタマイズ費用もすぐわかる!お見積りはこちら。


LLM/RAGシリーズ ラインナップ
LLM/RAGスターターセットV2
LLM/RAGの試験導入に最適なスタンダードモデル

2,210,000 円 ~
Q. スターターセットと業務活用セットの違いは?
A. 違いは「G-RAGon」が標準搭載されているかどうかです。
- LLM/RAGスターターセット
→ LLMやRAGの試験導入や、基本的なRAG構築・運用を行いたい方向け
→ Difyなどの一般的なRAGツールをそのまま活用し、自社で調整できる方に最適 - LLM/RAG業務活用セット
→ RAG回答精度改善・運用支援ツール「G-RAGon」を標準搭載!
→ RAGの精度向上に時間をかけたくない、すぐに業務適用したい方におすすめ
RAGの回答精度向上のノウハウがあり、手動で最適化できる方はスターターセットで十分!
効率よくRAGを調整し、高精度な回答精度を早期に構築したい方は業務活用セットがおすすめ!
どちらが最適か迷われる場合は、お気軽にご相談ください。
LLM/RAG業務活用セット FAQ
Q1. LLMもRAGも使ったことがないのですが、導入後すぐに使用できますか?
A. はい、ユーザマニュアルを添付しておりますので、そちらを見て頂ければすぐに使うことができます。
Q2. RAGの回答精度が上がらないのは何故ですか?
A. RAGの回答精度が上がらない原因は様々です。
RAGでは、文書をChunk(チャンク)と呼ばれる単位に分割して保存しています。
質問(クエリー)を与えると、質問内容に最も近いと判断されるChunkを検索(類似検索)して生成AIに提供し、生成AIがその情報を元に回答を生成します。
回答精度が上がらない最も大きな原因は類似検索がうまく行かない場合で、そのようなケースでは生成AIは誤った情報を元に誤った回答をしてしまいます(ハルシネーション)。
Difyの自動Chunkingで回答精度が上がらないのは、類似検索しやすいChunkに分割できないことが多いためです。
Q3. G-RAGonを使うと、どんな場合でもRAGの回答精度は90%以上になりますか?
A. いいえ、回答精度はRAGに登録する文書の品質に大きく依存します。
見出しや段落などの体裁が整っている文書では90%程度の回答精度は得られますが、90%を保証するものではありません。
また、体裁が整っていない文書では回答精度が大幅に落ちる場合があります。その場合はまず文書の品質を上げることを推奨しております。
Q4. OSSを使ったことがないのですが、自分でLLMやRAGを構築しようとした場合はどのような難しさがありますか?
A. OSSで提供されるアプリケーションやツール類は、マニュアルや技術的な解説が十分に提供されていない場合がほとんどです。
また、それぞれのOSSが独立して提供されていますので、複数のアプリを連携させて動作させたり、バグがあった場合の技術的な調査やソースコード解析などをお客様ご自身で行ったり、OSSのコミュニティを利用して解決する必要が出てきます。
その他に、UbuntuやGPUドライバーのバージョンとの相性もあり、アプリのバージョンアップをする度に動作検証とデバッグが必要となります。このような難しさがありますので、OSSの管理やソフトウェアの実装に詳しいエンジニアの知識が必須となります。
Q5. G-RAGonで精度向上が期待できる文書のフォーマットには何がありますか?
A. 現在サポートしているフォーマットはMicrosoft Word形式(.docx)、PDF形式(.pdf)です。
Q6. 自分でUbuntuやドライバーのバージョンアップを行っても大丈夫ですか?
A. お客様ご自身でUbuntu、GPUドライバー、DifyやLLM等のアプリのバージョンアップを行った場合、ソフトウェア間の連携が取れなくなって動かなくなる可能性が高く、その場合はサポート対象外となります(約款をご覧ください)。
弊社では定期的にソフトウェアセットのバージョンアップ版をご提供しておりますのでそちらをお待ち頂くか、ご自分でバージョンアップを行う場合は、バージョンアップ前の状態に戻せるようにバックアップを取ってからバージョンアップを行うようお願い致します。
Q7. Difyの新しいバージョンを使いたいのですが、自分でバージョンアップをしても問題ありませんか?
A. Difyをバージョンアップすると、ナレッジデータが消失したり動作しなくなる可能性が高いのでおやめ下さい。どうしてもバージョンアップの必要がある場合は個別に対応しますので、弊社営業までお問い合わせ下さい。
Q8. ソフトウェアのバージョンアップ版の提供は有償ですか?
A. ご導入後1年間は無償でご提供しております。2年目以降はアップデートサービスをご契約頂ければご提供いたしますのでお問合せ下さい。
Q9. ソフトウェアのバージョンアップ版の提供頻度はどれくらいですか?
A. 数ヵ月から6か月に1度程度を予定しております。
Q10. 「LLMスターターセット」「RAGスターターセット」を購入しましたが、「LLM/RAGスターターセットV2」にバージョンアップできませんか?
A. 「LLMスターターセット」「RAGスターターセット」をご購入頂いたお客様には、「LLM/RAGスターターセットV2」のソフトウェアセットへのバージョンアップを無償でご提供しております。
Q11. 「LLM/RAGスターターセットV2」を購入して試した後に、「LLM/RAG業務活用セット」にバージョンアップしたいのですが、そのようなことはできますか?
A. はい、「LLM/RAGスターターセットV2」から「LLM/RAG業務活用セット」へのソフトウェアセットのアップグレードは個別でご提供しております。詳しくはお問合せ下さい。
Q12. エントリーモデルからミッドレンジモデルへのアップグレードはできますか?
A. いいえ、エントリーモデルとミッドレンジモデルのベースとなるワークステーションは、GPUの種類が異なっており、アップグレードの対象ではない為、将来の拡張性を重視される際は、ミッドレンジモデルをご検討ください。
Q13. エントリーモデルとミッドレンジモデルでインストールされている生成AIが違うのは何故ですか?
A. 生成AIが動作するためのGPUメモリが、生成AI毎に異なるためです。生成AIは、GPUメモリに入りきらなければ十分な性能を得られません。
RTX PRO 4500には32GBしかGPUメモリが搭載されておりませんので、32GBに入りきるサイズの生成AIをご用意しております。
Q14. なぜOSはUbuntuだけで、Windowsをサポートしないのですか?
A. 生成AI関連のOSSはUbuntuだけでしか動作しないものが多いためです。
Q15. 誤ってOSやアプリケーションが破損してしまった場合はどうすればいいですか?
A. 弊社のサポートにご連絡頂ければ、状況に応じて解決方法をご提示させて頂きます。万が一の事態に備えて、OSディスク全体のバックアップを取っておくことを推奨しております。
Q16. G-RAGonを他のコンピュータにコピーして使っても大丈夫ですか?
A. G-RAGonは弊社の知的財産となっておりますので、コピーして使用することは禁止しております。
Q17. Q&Aチケットはどのようなときに使えばいいですか?て使っても大丈夫ですか?
A. ユーザマニュアルの分からない部分について使用できます。RAGの精度を上げるための文書の作り方や、サポート外の使用方法等に関するご質問には使えません。
ただし、Q&Aチケットを2枚使用することで、生成AIやRAGに関するコンサルテーションを実施しております。詳しくは約款やサービス仕様をご覧ください。
Q18. ハードウェアの故障やソフトウェアが全く動作しないような場合もQ&Aチケットを消費しますか?
A. トラブルシューティングではQ&Aチケットは消費しません。サポートにトラブルの内容をご連絡下さい。
Q19. インストールされているDifyや生成AI等にバグがあることが分かりました。このようなバグのサポートもしてもらえますか?
A. 弊社のサービスはお客様の代行インストールとなっており、OSSの不良等の責任を負いません。AS ISでご利用頂く前提となっておりますので、ご理解よろしくお願い致します。
ただし、必要と考えられる機能にバグがある場合には、バグフィックスがリリースされた時点で更新版に積極的に取り込むようにしております。
Q20. LLM/RAGシリーズを使うメリットは、使いやすさや回答精度、価格以外に何がありますか?
A. 弊社では、コンピュータシステムの設計・開発・構築経験のあるインフラエンジニアチームと、生成AIの技術開発チームの両方を有しており、新技術の開発と取り込みを行ってお客様の生成AI活用の利便性向上に努めております。この体制により、常に最新技術の情報発信と商品提供を行っておりますので、バージョンアップ等を通してご購入後の資産の有効活用や、新機能の活用が可能になると考えております。